This genomic profiling study describes the molecular architecture of 1104 prospective consecutive meningioma samples from one academic medical center.
Scientists have advanced the field of cancer treatment by leveraging the body’s immune system to recognize and target tumors. The study of the immune system helps better advance these treatments and boost immune responses. The evolution of immune cells and different aspects of the immune system has helped fight aggressive forms of disease. More importantly, as ancient populations become exposed to different diseases over time, heredity can protect future generations from these specific viruses and bacteria.
One specific part of the immune system, known as ‘complement’, is crucial to aiding a robust immune response. Complement is part of the innate immune system and consists of over 50 plasma proteins. Complement proteins rapidly target foreign pathogens and trigger inflammation from infection. Specifically, these proteins help puncture infected cell membranes to eliminate disease. While complement is a unified system, it takes several pathways to function: Classical, Lectin, and Alternative. These three functions trigger complement in different ways but converge into a single innate immune defense. There are also different types of complement proteins. One of the most abundant is complement C3, which acts as a critical surveyor and defense against pathogens. Compliment C3 is an ancient protein and is found in organisms such as jellyfish, playing a pivotal role in the immune system. It specifically tags infected cells with molecules for immune cells to identify and target.
Stem cell transplantation (or bone marrow transplantation) and gene therapy have revolutionized the way oncologists treat patients. Both approaches have the potential to cure patients with sickle cell disease, b-thalassemia, immune disorders, and even several blood cancers. There are specific transplants that can occur: autologous and allogenic. Both forms of transplantation are dependent on the source of the donor cells. Autologous transplants use the patient’s healthy stem cells taken from the patient before systemic treatment, like chemotherapy. Allogenic transplants use stem cells collected from healthy donors. Typically stems cells for an allogenic transplant is from a family member or umbilical cord blood to genetically match the recipient. If stem cells are not genetically matched, then the donor will recognize the stem cells as foreign and reject the transplant. This rejection is known as Graft-versus-Host Disease (GvHD). Infusion of stem cells only takes about 15 minutes, but the engraftment or the ability for cells to proliferate and establish themselves in the bone marrow takes up to 18 days. For full immune system recovery, most physicians see patients recover within a year. However, stem cell transplants are not perfect. There is a high rate of GvHD, infection, and disease relapse. Patients also usually receive chemotherapy before a transplant, which increases toxicity and reduces success of the procedure. Scientists are currently working on how to improve the success rate of transplantation.
A recent article in Nature, by Dr. Pietro Genovese and others, demonstrated that stem cell transplantations are safer when chemotherapy is replaced with a targeted treatment. Researchers used antibodies that recognize and target markers on blood-forming stem cells. This approach helps clear harmful preexisting stem cells from the patient before transplantation, instead of using toxic chemotherapeutic agents that damage DNA throughout the body. The antibody approach is more specific and reduces toxicity in patients. Genovese is an Assistant Professor at Dana Farber and Boston Children’s Cancer and Blood Disorders Center. His work focuses on gene-editing and bioengineering technologies that improve stem and immune cells. Specifically, Genovese investigates ways to improve gene therapy and develop approaches to enhance treatment for patients with hematological malignancies.
Previously, an antibody could not discern between current recipient and infused autologous stem cells. Antibodies could also attack transplanted cells from a separate donor (allogenic). To avoid these issues, Genovese and his team have used gene-editing tools to select for a specific biomarker on the surface of donor stem cells. The small edit prevented the antibody from binding to the donor stem cells. These antibodies were able to avoid the healthy stem cells and still eliminate the infected stem cells. This approach allows the donor stem cells to properly graft in the host and improve success of transplantation.



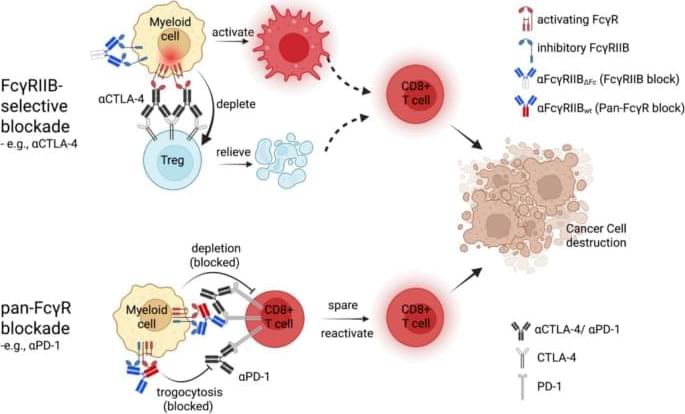
Fc-gamma receptors (FcγRs) regulate IgG antibody activity, and Fc-engineering is a proven method to improve the efficacy of tumor-targeting antibodies. Here, we explore tailored FcγR blockade to enhance the therapeutic efficacy and tolerability of immune checkpoint-blocking (ICB) antibodies.
Mechanistically matched murine surrogate and human lead FcγR-blocking and immune checkpoint-blocking antibodies were used to study whether tailored FcγR-blockade, targeting FcγRIIB selectively or all FcγRs, can enhance the efficacy and overcome resistance to immune checkpoint therapy in vivo and in vitro. Mechanistic studies were performed with clinical reagents, including ipilimumab, nivolumab, pembrolizumab, and human FcγRIIB-selective (BI-1607) and pan-FcγR-blocking (BI-1206) antibodies, using human cells and transgenic animals with clinically relevant expression of immune checkpoint receptors.
We demonstrate that FcγRIIB-selective and pan-FcγR-blocking antibodies increase the in vivo efficacy of αCTLA-4 and αPD-1 antibodies, respectively. FcγRIIB-selective antibody enhancement of αCTLA-4 was associated with increased intratumoral Treg depletion, myeloid reprogramming, interferon-γ and CXCL10-induction, and increased activated effector CD8+ T cells, correlating with higher activating-to-inhibitory (A: I) FcγR engagement ratios. Conversely, pan-FcγR blockade protected αPD-1-coated T cells from macrophage phagocytosis, increasing intratumoral activated CD8+ T cells by decreasing activating and inhibitory FcγRs.
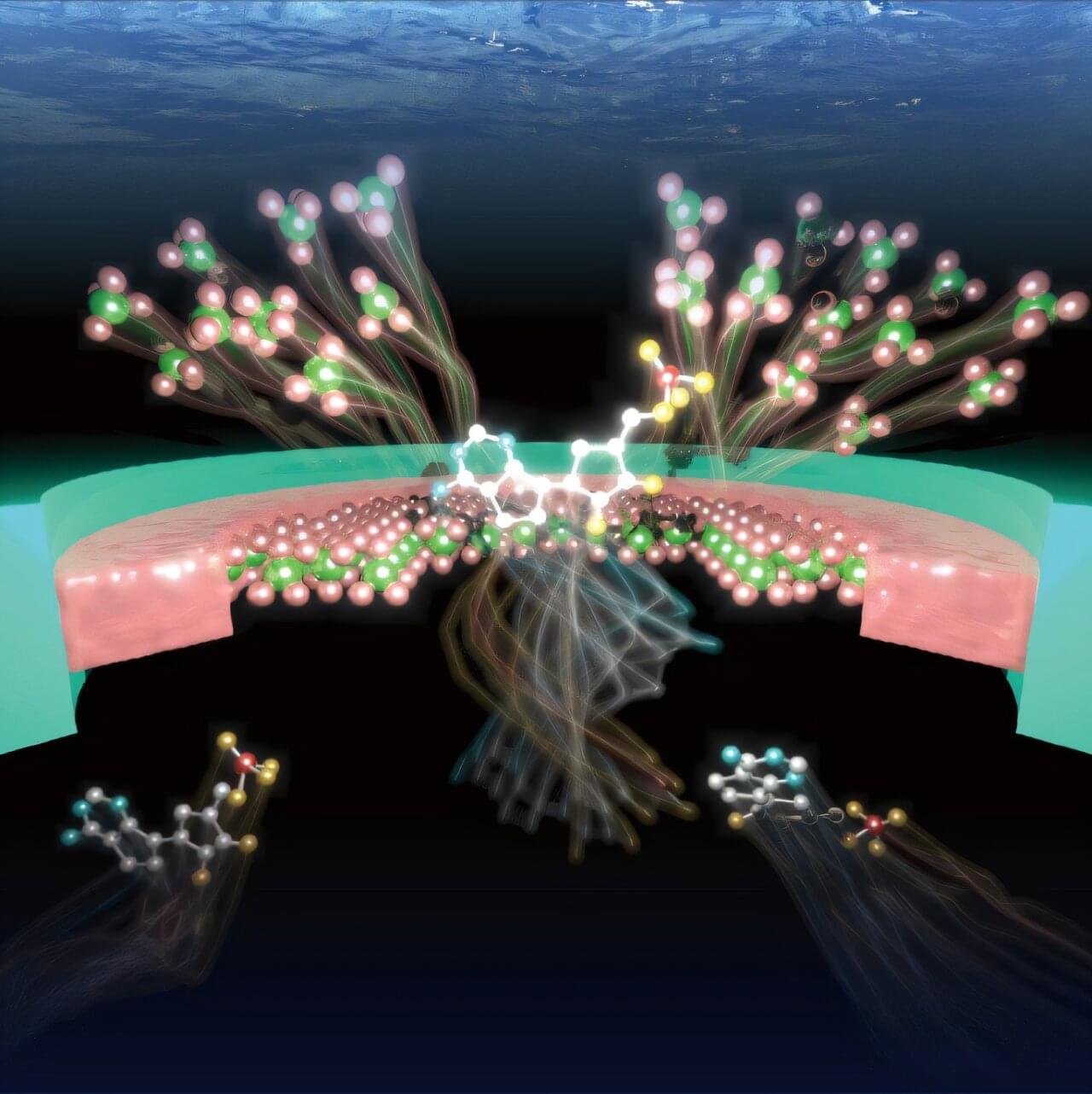
Most sensors are designed to do only one thing: detect what passes through them. But what if a sensor could do more? To create a new generation of technology, researchers have looked to living systems for inspiration. If a sensor could detect molecules, could it also remember previous interactions and selectively respond to them?
Researchers have developed a device that does exactly that on a tiny scale, laying the groundwork for a new generation of smart molecular sensors.
In an article recently published in ACS Nano, researchers from SANKEN at the University of Osaka and collaborating institutions created an autonomous solid-state nanopore that can sense molecules, generate electrical signals and retain memories of recent events without external control. Unlike conventional nanopores, which act as passive channels, the new device continuously changes its own structure through chemical reactions, creating a dynamic sensing environment that responds to molecules passing through it.

{kind=link}