This website uses a security service to protect against malicious bots. This page is displayed while the website verifies you are not a bot.

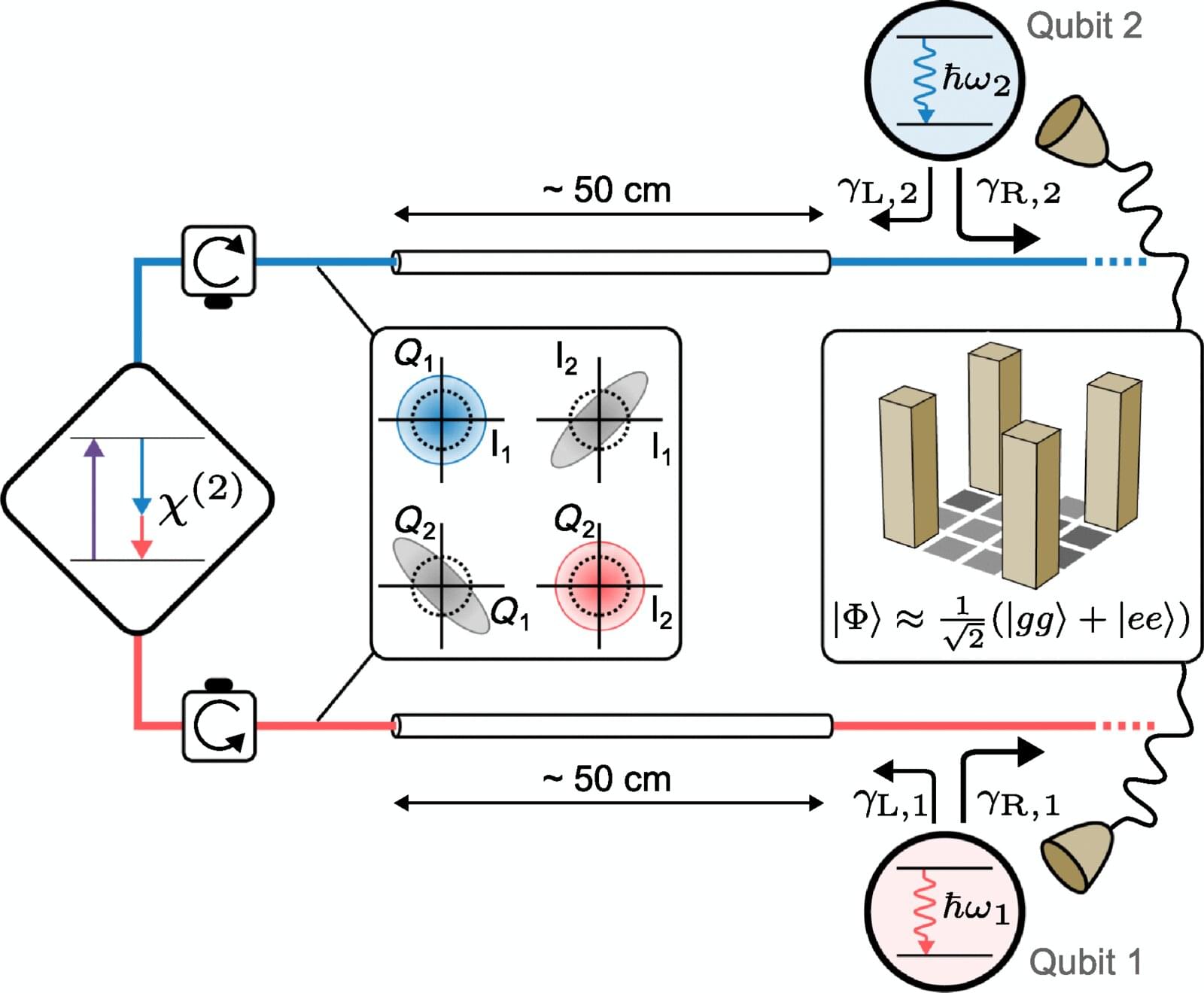
Future quantum computing will require correlations between distant modules—a feature known as distributed entanglement. Traditionally, such entanglement has relied on active control and repeated measurements. Now, physicists at the Institute of Science and Technology Austria (ISTA) have realized a fully autonomous method for distributed entanglement using a “quantum bath” of correlated light particles. Published in Physical Review X, their work experimentally confirms a 20-year-old prediction and could provide a new platform for applied quantum technologies.
Entanglement is a central feature of quantum physics in which shared correlations exceed what classical theories can explain. Achieving distributed entanglement between physically separated qubits (quantum bits) could enable future advances, such as scalable quantum computers and quantum networks.
To entangle distant qubits, earlier attempts have relied on two protocols. In one approach, a single, actively controlled photon is sent from one qubit to the other. In the second approach, each qubit emits a photon that must be matched to produce entanglement. While the second method earned the 2022 Nobel Prize in Physics, it requires many repeated measurements and post-selection and still does not always yield entanglement.

Before starting Oak Lab, both Sutton and Javed were working at Keen Technologies—an AGI startup founded by legendary game developer John Carmack. They chose to break away to pursue a fundamentally different path toward understanding intelligence. Sutton bluntly describes current deep learning methods as “weak and inefficient,” arguing that today’s AI models are hitting a wall because of how they learn.
Today’s frontier models (like ChatGPT or Claude) are trained on massive, static, pre-collected internet datasets. Sutton argues this is “learning from someone else’s experience.” Because these datasets are frozen, the models cannot independently discover truly new knowledge, adapt in real time, or evaluate their own outputs.
Sutton’s model explicitly shifts away from the “turn-based” prompt-and-response loop of modern LLMs. By running the FC-STOMP cycle continuously on streaming data, Oak Lab expects to build agents that discover optimal, creative survival and problem-solving strategies that completely bypass the limits of human intuition.
OaK architecture discovers temporal abstractions grounded in experience that are both self-verifiable and useful for planning.
In this episode, the mates and Steven Kotler sit down with Ray Kurzweil to discuss AGI, the future, and more.
Get access to metatrends 10+ years before anyone else — https://qr.diamandis.com/metatrends.
Ray Kurzweil is an American inventor and futurist best known for his pioneering work in optical character recognition and his predictions regarding the technological singularity.
Peter H. Diamandis, MD, is the Founder of XPRIZE, Singularity University, ZeroG, and A360.
Salim Ismail is the founder of Open ExO, a GP at Exponential Venture Capital/The Organizational Singularity Fund and a sought after global speaker and thought leader.
Dave Blundin is the founder \& GP of Link Ventures.
A new artificial intelligence system developed by West Virginia University engineers could help firefighters respond to wildfires sooner by enabling satellites to detect blazes and automatically adjust their positions for continued monitoring.
Unlike drones and ground-based sensors, satellites can monitor vast areas of the planet without requiring local infrastructure or routine maintenance. WVU researchers Brycen Pearl, Joshua Warner and Hang Woon Lee developed a framework that allows satellites not only to detect wildfires but also to coordinate with one another and adjust their observation schedules as fires spread.
“Wildfires move quickly—as fast as 15–20 mph (24–32 km/h) under the right conditions—and major wildfires can cover hundreds of thousands of acres,” according to Lee, director of the WVU Space Systems Operations Research Laboratory and assistant professor at the WVU Benjamin M. Statler College of Engineering and Mineral Resources.

When can we trust the results we get from AI, and when is learning impossible? Researchers have shown that there are some problems that even the most powerful AI cannot reliably solve, no matter how much data it is given.
The researchers, from the University of Cambridge and the University of California, Santa Barbara, designed “adversarial” mathematical systems to fool any AI algorithm. Like ethical hackers stress-testing a network’s security, these adversarial systems were designed to map out exactly where and why AI prediction breaks down.
Many real-world systems—like those in the oceans, the human brain or robotics—are too complex to describe neatly with equations, so researchers often learn how they behave by using machine learning. But these AI methods don’t always work well, returning unreliable results or poor predictions.
Cancer immunotherapy drugs known as immune checkpoint inhibitors (ICIs) can be miracle drugs for cancer patients, curing some and turning deadly disease into a manageable chronic condition in others. But these drugs work for only a subset of patients, with few indications why—a knowledge gap that has detrimental effects on patient prognosis, clinical trial recruitment and research that could lead to new therapies.
A new artificial intelligence model called COMPASS, developed by Harvard Medical School researchers and their colleagues, improves prediction of which patients are most likely to respond to ICIs. Using data from patients treated in the past, the model outperformed the best existing approaches by 8.5%. It makes its predictions based on patients’ tumor gene activity and provides a rationale for its output.
If these results are validated in a future clinical trial, COMPASS could lead to better personalized medicine for cancer patients, more efficient trial enrollment for new therapies and new drug targets for researchers to explore.

{kind=link}