Sickle cell disease causes premature aging of blood stem cells, which scientists may be able to address with a special class of drugs, according to a new study from St. Jude Children’s Research Hospital. Patients with sickle cell disease experience higher rates of blood stem cell dysfunction and blood cancers compared with their peers, though the reason has been unclear.
The St. Jude researchers found that blood stem cells from young patients with sickle cell disease have features of aging, likely increasing the risk of other complications. Giving senolytics, which target aging-related processes, improved disease symptoms in model systems, with implications for curative gene therapies. The findings were published in Science Translational Medicine.
“We saw that blood stem cells from even young patients with sickle cell disease have many markers of senescence or aging,” said senior co-corresponding author Shannon McKinney-Freeman, Ph.D., St. Jude Department of Hematology.
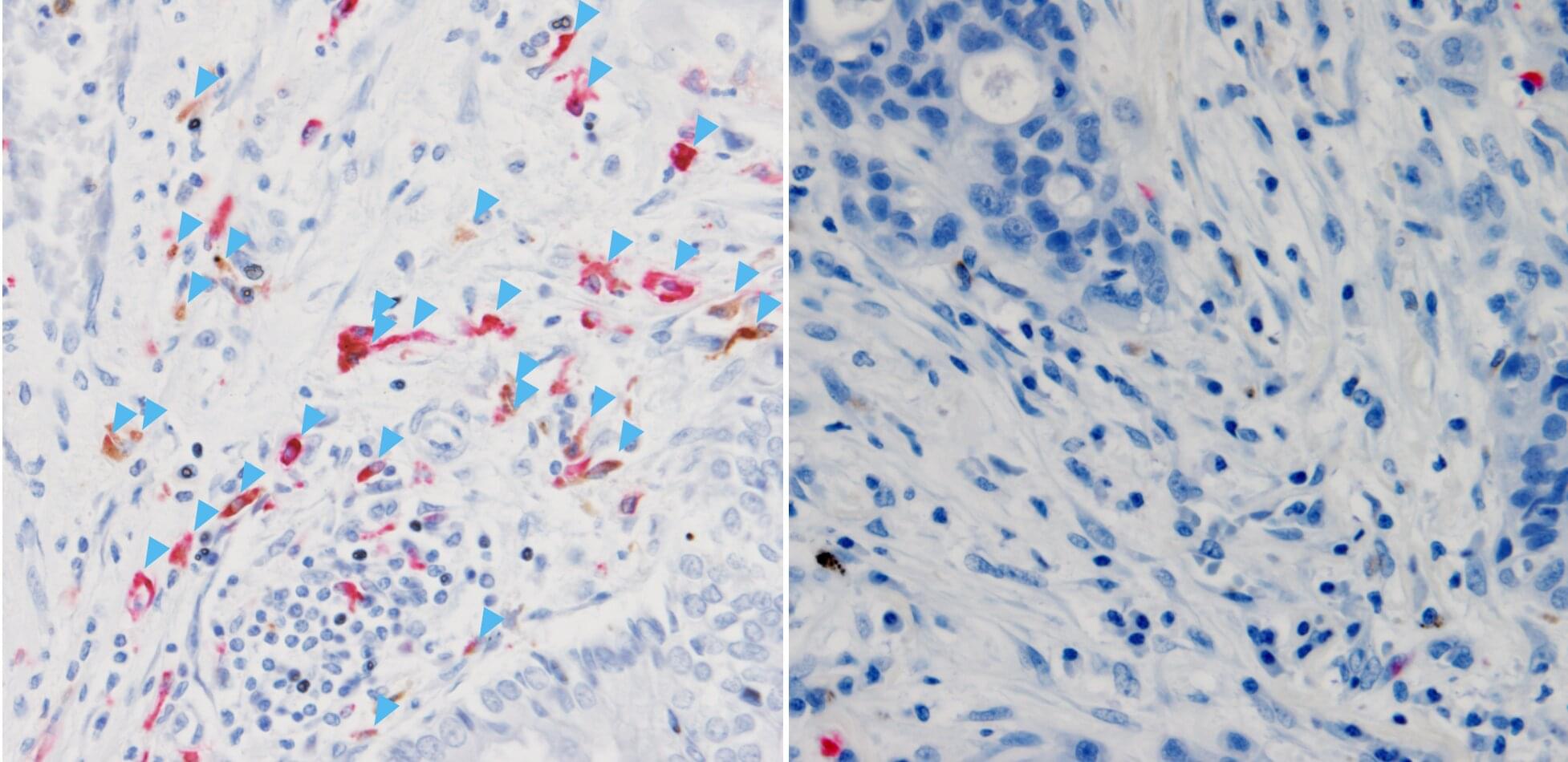
An ancient molecule that existed long before the circulatory system evolved has been found to support cancer immunotherapy. Researchers at Nagoya University in Japan found that complement C3 protein acts inside tumors to prevent the accumulation of immunosuppressive cells, but only when produced inside the tumor. C3 circulating in the blood did not affect treatment outcomes.
Published in Nature Communications, the findings suggest that artificially recreating this effect can help patients with tumors that do not naturally produce enough of this protein.
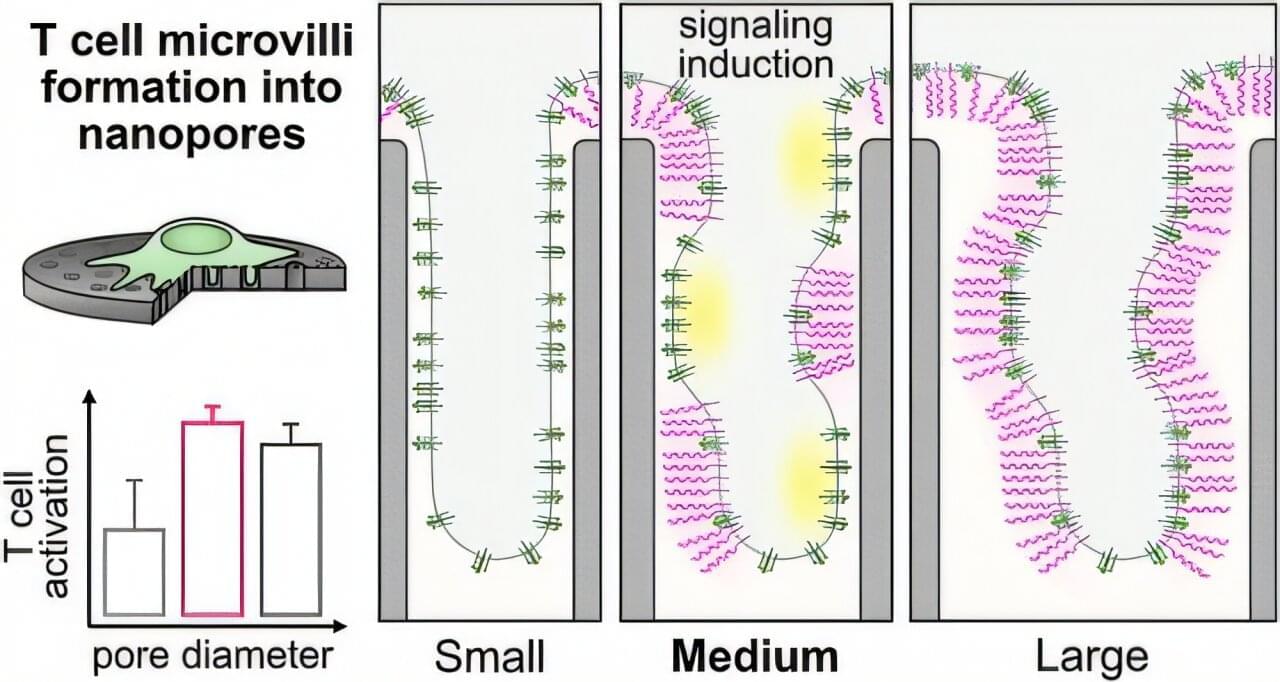
Immune cells protect and heal the human body. In medicine, they are specifically activated through biochemical reactions to treat certain diseases. Researchers at the Helmholtz-Zentrum Hereon, ETH Zurich, Humboldt University of Berlin, Charité Berlin and Inselspital Bern have now discovered that immune cells also respond to the surface structure of materials —without chemistry.
This finding opens up new possibilities for effective cancer and immunotherapies as well as implantology. The study is published in the journal ACS Nano.
T cells are important defense cells of the human immune system. They travel through the body, constantly scanning their environment like tiny sensors. On their surface, they have tiny protrusions with receptors—called microvilli—that allow them to identify harmful pathogens such as bacteria and viruses, foreign substances or even altered cells of the body’s own tissues.
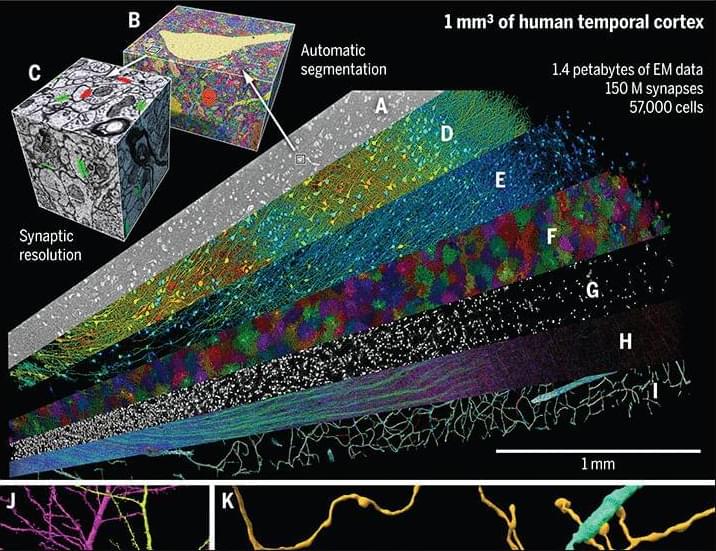
“In a 2024 Science study, researchers performed a high-resolution EM reconstruction of the ultrastructure of a cubic millimeter of human temporal cortex. According to the authors, the reconstruction contains roughly 57,000 cells, about 230 millimeters of blood vessels, and nearly 150 million synapses, comprising 1,400 terabytes of data.”
This website uses a security service to protect against malicious bots. This page is displayed while the website verifies you are not a bot.
A plant-derived compound reduced swelling, inflammation, and joint damage in rats with rheumatoid arthritis. It also helped rebalance immune activity and improve the way certain fats were processed in the body. Researchers say the findings could lead to a new approach for treating the disease.
He kept applying. Then he flew three shuttle missions, walked in space four times, and made two trips to the International Space Station. On the mission that didn’t go there, he was outside the orbiter rehearsing how to build it.
In 2011, I ambushed him with a camera at Singularity University and got 20 minutes.
Dan is not just an astronaut. He holds a doctorate in electrical engineering from Princeton and a doctorate in medicine from Miami, and he left NASA in 2005 to build #robotics for people with disabilities. So when our conversation turned to #ArtificialIntelligence, and specifically to what happens when we arm it, he was not speculating. He was describing machines he understood from the inside.
Armed drones were already flying in 2011. What nobody had done yet was hand the machine the decision to fire. Fifteen years on, that line is thinner than most people realize.
We also got into Asimov’s three laws, the Turing test, his 109 project to improve a billion lives in a decade, and whether we survive the #Singularity at all.
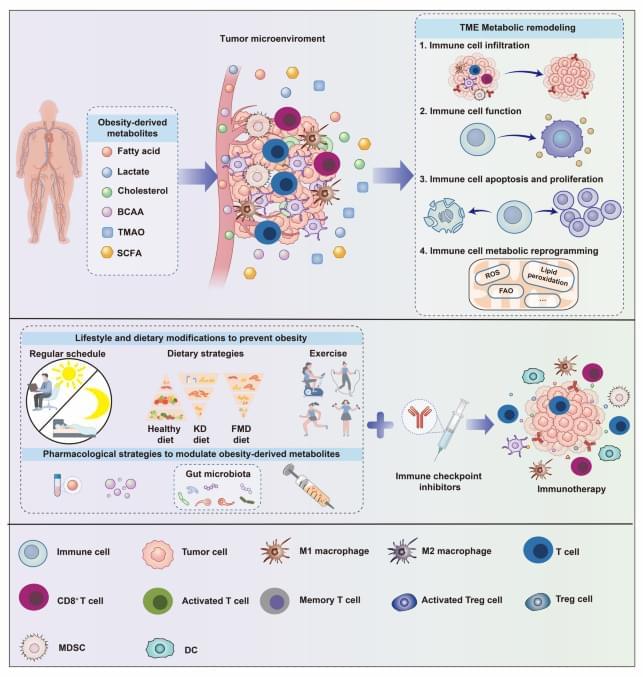
The tumor microenvironment (TME) is increasingly understood as a metabolically dynamic ecosystem in which local metabolite availability, composition, and trafficking shape immune cell fitness and therapeutic responsiveness. Against the backdrop of the global obesity epidemic, obesity-associated systemic metabolic dysregulation has been implicated in tumor initiation and progression and may also influence the immune contexture and treatment responsiveness of tumors. This Review examines how obesity-derived systemic metabolites may modulate anti-tumor immunity and influence cancer immunotherapy, with particular emphasis on pathways involved in metabolic reprogramming and TME remodeling. We further discuss intervention strategies spanning (i) upstream metabolite generation, (ii) systemic-to-local trafficking into the TME, and (iii) direct functional antagonism within the TME.
Autosomal dominant Alzheimer’s disease (ADAD) is a genetically inherited form of Alzheimer’s disease that accounts for only about 1% of Alzheimer’s disease cases. However, because individuals with the gene mutations are extremely likely to develop Alzheimer’s disease at an early age, and because the mutation is highly heritable, ADAD is widely studied by Alzheimer’s disease researchers.
A new study by WashU Medicine researchers and collaborators, published in The Lancet Neurology, identified variants in three other genes that seem to change how Alzheimer’s disease presents in people with ADAD mutations. Pinpointing these and other genetic factors that affect Alzheimer’s disease development and progression may allow investigators to provide more effective genetic counseling for families, design clinical trials and develop new treatments to prevent or slow Alzheimer’s disease in the larger population.
Previous studies had already identified three key genes—amyloid precursor protein (APP), presenilin 1 (PSEN1) and presenilin 2 (PSEN2)—that are associated with ADAD, as well as 279 variants in those genes that lead to Alzheimer’s disease. What remains unclear, however, is what leads to differences in disease onset and progression among individuals who have a disease-causing variant. For instance, even if a person carries an APP, PSEN1 or PSEN2 mutation and is therefore very likely to develop early-onset Alzheimer’s, there is variability in when symptoms of cognitive decline might begin, even among individuals who have the same disease-causing mutation.
Zahi A. Fayad, PhD, is the Lucy G. Moses Professor of Medical Imaging and Bioengineering at the Icahn School of Medicine at Mount Sinai, where he also serves as Vice Chair for Research in Radiology and holds professorships in Medicine (Cardiology) and AI & Human Health. He is the founding Director of the BioMedical Engineering and Imaging Institute (BMEII), home to one of the nation’s top NIH-funded radiology programs (#2 in 2025 per Blue Ridge rankings). Dr. Fayad also co-leads Mount Sinai’s system-wide Healthspan initiative, coordinating research, clinical, and digital infrastructure to advance precision prevention across the enterprise.
Dr. Fayad is Principal Investigator on multiple major grants, including five NIH-funded projects (3 R01s, 2 P01s) supported by the National Heart, Lung, and Blood Institute, NIAID, and NIDA. A leader in biomedical engineering, his interdisciplinary work integrates advanced imaging, AI, and nanomedicine to drive precision medicine, with research interests focused on how lifestyle stressors — chronic stress, diet, exercise, and sleep — affect long-term cardiovascular and whole-person health.
A Clarivate Highly Cited Researcher since 2018 (~190,000 citations; h-index 142), Dr. Fayad’s seminal contributions include MRI vessel wall imaging (leading to Carotid Plaque-RADS), FDG PET imaging of vascular inflammation, and defining the link between amygdala activity, systemic inflammation, and cardiovascular risk. His research on HDL-based nanoparticles for immune modulation is progressing toward clinical translation for cancer, autoimmune diseases, and transplant rejection — work he is advancing commercially as co-founder of Trained Therapeutix Discovery (TTxD), an early-stage biotech company. He is also a recipient of the Jean Paul II Award for Medicine and Research.
His current projects span cardiovascular, neuroimmune, and transplant-focused research, including stress-induced immune dysregulation; mitral valve prolapse and arrhythmia risk; cocaine use–related carotid atherosclerosis and cognitive impairment; cardiac sarcoidosis therapy monitoring; and immune tracking in organ rejection using nanobiologics — together shifting care upstream toward risk prediction and intervention before clinical events.
He also leads the Mount Sinai DigiTwin Project, an AI-driven platform designed to personalize health optimization by integrating imaging, multi-omics, and real-time physiologic data — initially focused on cardiovascular health and now expanding to whole-person healthspan modeling. Dr. Fayad and colleagues at Mount Sinai are finalists in the $80m XPRIZE Healthspan competition, where they are evaluating a multimodal strategy to meaningfully extend human healthspan.