Scientists have advanced the field of cancer treatment by leveraging the body’s immune system to recognize and target tumors. The study of the immune system helps better advance these treatments and boost immune responses. The evolution of immune cells and different aspects of the immune system has helped fight aggressive forms of disease. More importantly, as ancient populations become exposed to different diseases over time, heredity can protect future generations from these specific viruses and bacteria.
One specific part of the immune system, known as ‘complement’, is crucial to aiding a robust immune response. Complement is part of the innate immune system and consists of over 50 plasma proteins. Complement proteins rapidly target foreign pathogens and trigger inflammation from infection. Specifically, these proteins help puncture infected cell membranes to eliminate disease. While complement is a unified system, it takes several pathways to function: Classical, Lectin, and Alternative. These three functions trigger complement in different ways but converge into a single innate immune defense. There are also different types of complement proteins. One of the most abundant is complement C3, which acts as a critical surveyor and defense against pathogens. Compliment C3 is an ancient protein and is found in organisms such as jellyfish, playing a pivotal role in the immune system. It specifically tags infected cells with molecules for immune cells to identify and target.


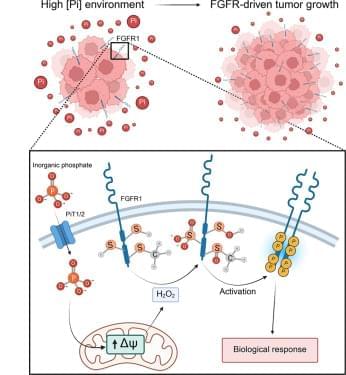

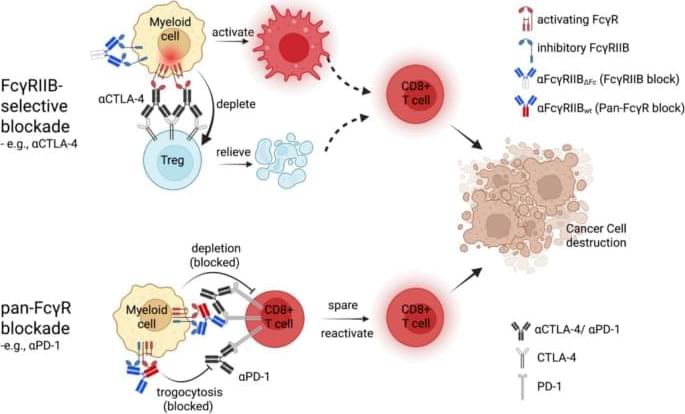
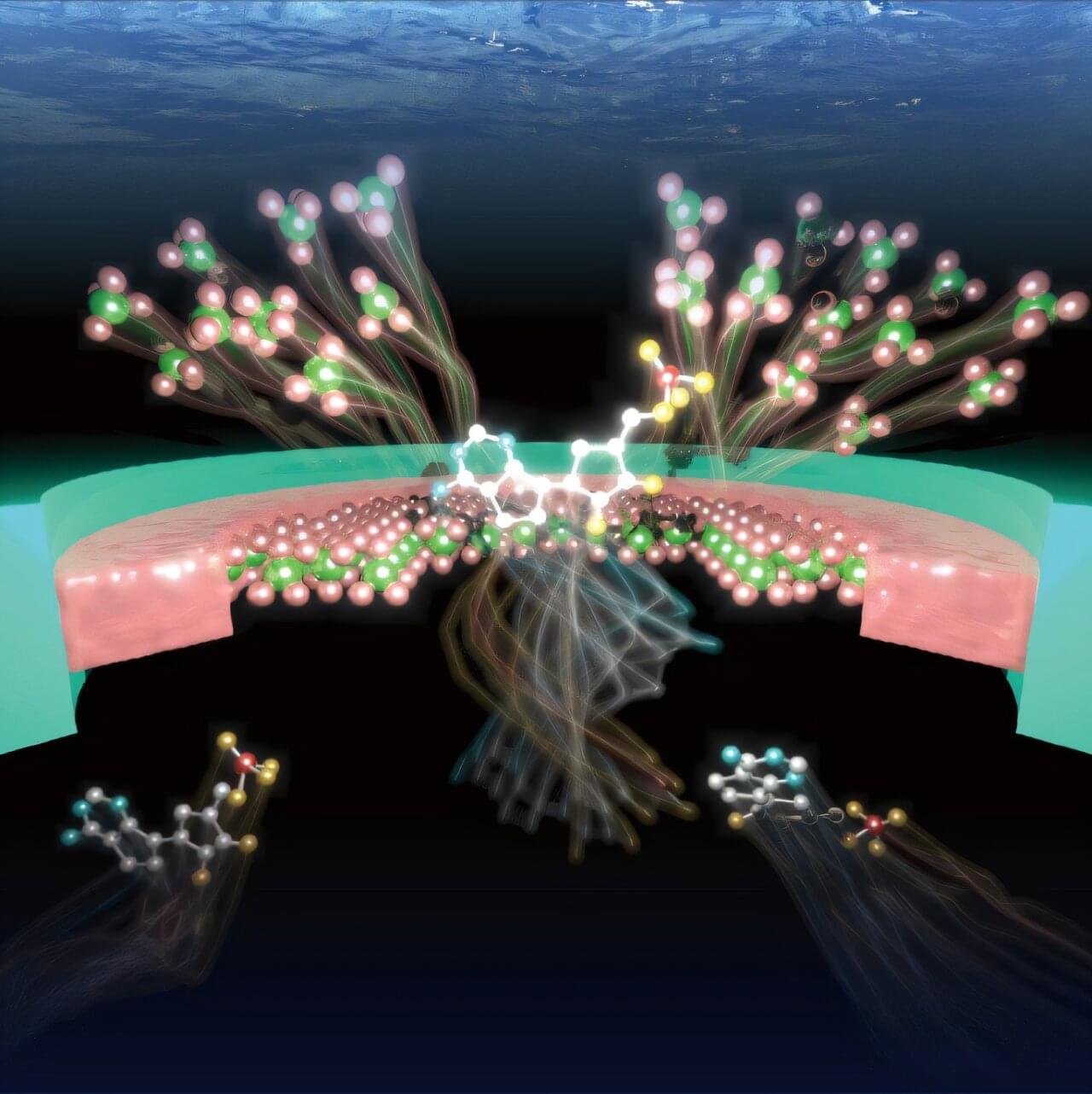

{kind=link}