A large meta-analysis shows breastfeeding is linked to subtle DNA methylation differences in infants, suggesting a molecular basis for long-term health effects.

CAR T Cell Therapy for Cancer Treatment / approved car t cell therapies, car t cell therapy process, CAR T-CELL, CAR T-cell therapy, CAR-T, CAR-T cells, CAR-T

The Department of Transportation has approved a request from the driverless vehicle company Zoox to start offering rides to paying customers. A California-based company owned by Amazon, Zoox has been testing its driverless electric vehicle with free rides. Now, it has approval to commercially deploy up to 5,000 vehicles over the next two years, starting in Las Vegas. Unlike Google’s Waymo, which adds driverless technology to existing vehicles, Zoox’s vehicles look like a box on wheels and don’t have steering wheels or pedals. Find “NPR News Now” wherever you listen to podcasts. Host: Jeanine Herbst/NPR Reporter: Camila Domonoske/NPR Producer: Michael Zamora/NPR
Follow NPR elsewhere, too: • Instagram: https://www.instagram.com/npr/ • TikTok: https://www.tiktok.com/@npr • Facebook: https://www.facebook.com/NPR

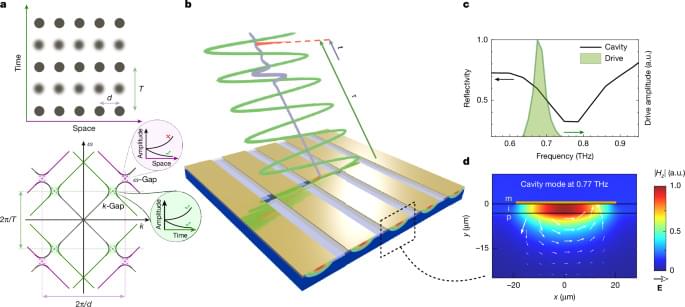
To achieve the ultra-fast changes needed, they hit the metamaterial with powerful laser pulses. This violently accelerated the material’s free-floating electrons, dynamically altering their energy and making their “effective mass” shift by up to 80% of their rest mass in fractions of a trillionth of a second. This massive, rapid shift forced the material into a time-crystal state.
A plasmonic metamaterial driven at terahertz frequencies achieves strong, ultrafast temporal modulation and shows a transition to the photonic time crystal regime with reduced plasmonic losses.
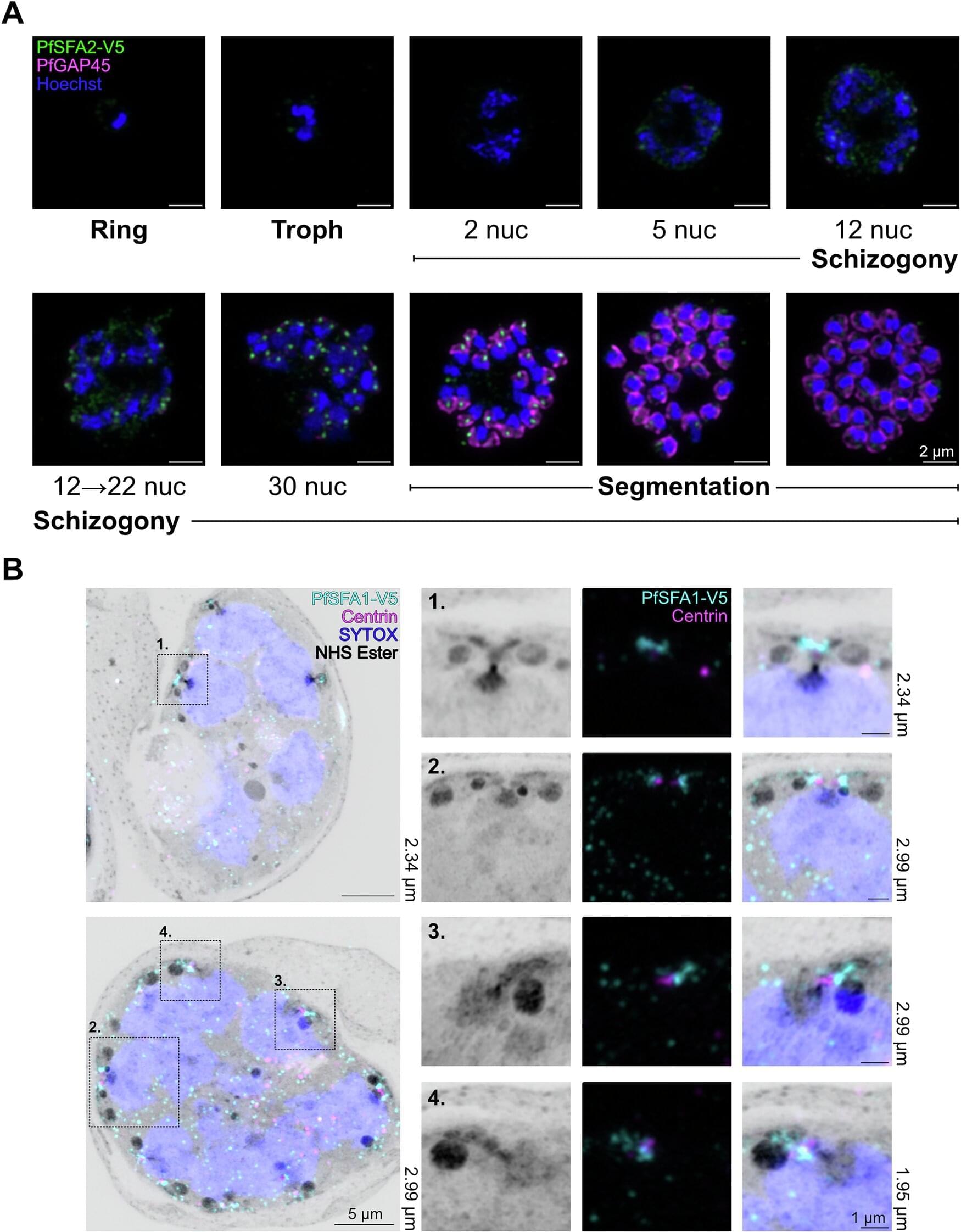
Malaria parasites proliferate in an unusual way. Rather than dividing into two daughter cells like human cells, they first amplify their genetic material tenfold, hundredfold or even thousandfold before simultaneously producing a corresponding number of daughter parasites. Until now, the mechanisms controlling these processes were only partly understood.
Two recently published studies by researchers from Heidelberg University’s Faculty of Medicine, Harvard Medical School and the German Cancer Research Center (DKFZ) provide important insights into the molecular basis of this proliferation strategy and reveal how the parasite makes particularly efficient use of limited resources within infected blood cells. The findings open new perspectives for the development of future antimalarial drugs.
Consider a primary care physician seeing a patient aged 58 years for routine follow-up. The electronic health record (EHR) alerts that the patient is eligible for statin therapy. The physician overrides it, as clinicians do for the vast majority of alerts. The system verifies what is computationally easy (eg, age, lipid values, and risk score) but ignores what the clinician needs: has this patient been offered statins before? Did they decline, and if so, why (cost concerns, fear of adverse effects, preference for lifestyle modification)? Have they tried statins previously and experienced muscle pain? If they were prescribed a statin, did they ever pick it up from the pharmacy? What did they write in that patient portal message 2 months ago when they mentioned reading online that statins cause memory problems? The answers are scattered across notes, dispensing records, and portal messages. The alert identifies eligibility but not the patient’s decision state or the barriers to action.
Consistent with established definitions, clinical decision support (CDS) includes tools that provide knowledge and patient-specific information to support health decisions and is not limited to guideline adherence.1,2 This Perspective focuses on clinician-facing CDS organized around a defined decision; generic note drafting, inbox management, and open-ended chart summarization are excluded unless they directly support that decision. A prior reason for declining statin therapy is relevant because it changes the next action, not eligibility. Deterministic methods remain preferable when criteria and outputs are explicit; large language models (LLMs) may extend them through flexible synthesis and adaptive presentation.
Early medical LLM applications have focused on drafting replies and summarizing charts.3,4 The larger opportunity is to revisit a long-standing trade-off between clinical fidelity and computational tractability. Health information technology has historically represented complex narratives and knowledge through structured fields and rules because they were computable.5 LLMs do not provide the first access to narrative text; their incremental value is the flexibility to extract, synthesize, and communicate across heterogeneous sources.
{kind=link}