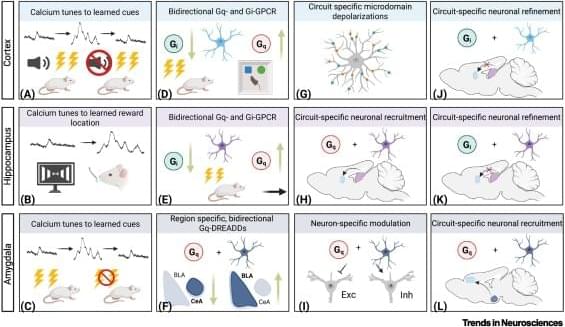
Astrocyte plasticity in learning and memory.
Neuronal hallmark features of learning and memory, such as activity dependent plasticity, circuit-level modulation, and gene regulatory mechanisms, are also observed in astrocytes.
Astrocytic calcium displays plastic, activity-dependent recruitment and refinement (akin to neuronal activity) across neuronal subtypes, brain regions, and behavioral paradigms, and Designer Receptors Exclusively Activated by Designer Drugs (DREADDs)-mediated manipulations highlight astrocytic recruitment of circuit-specific neurons.
Astrocyte peripheral processes display activity-dependent plasticity and are able to discriminate between neuronal subtypes, circuits, and even individual synapses.
Single-cell RNA sequencing reveals molecularly defined subtypes of astrocytes that display unique transcriptional responses to learning and memory and implicates potential ‘ensemble’-like networks of astrocytes. sciencenewshighlights ScienceMission https://sciencemission.com/astrocyte-plasticity
Learning and memory arise from coordinated activity-dependent plasticity across neural circuits and brain regions. Astrocytes are increasingly recognized as active contributors to learning and memory via their roles in sensing, integrating, and responding to contextual information. Astrocytes modulate synaptic transmission, engage in circuit-specific signaling, and display context-dependent calcium dynamics that influence behavior. In this review, we focus on astrocyte functions across rodent models that display plasticity traditionally ascribed to neurons, including activity-dependent molecular and structural plasticity, circuit-level modulation, ensemble-like networks, and transcriptional, translational, proteomic, and epigenetic plasticity.