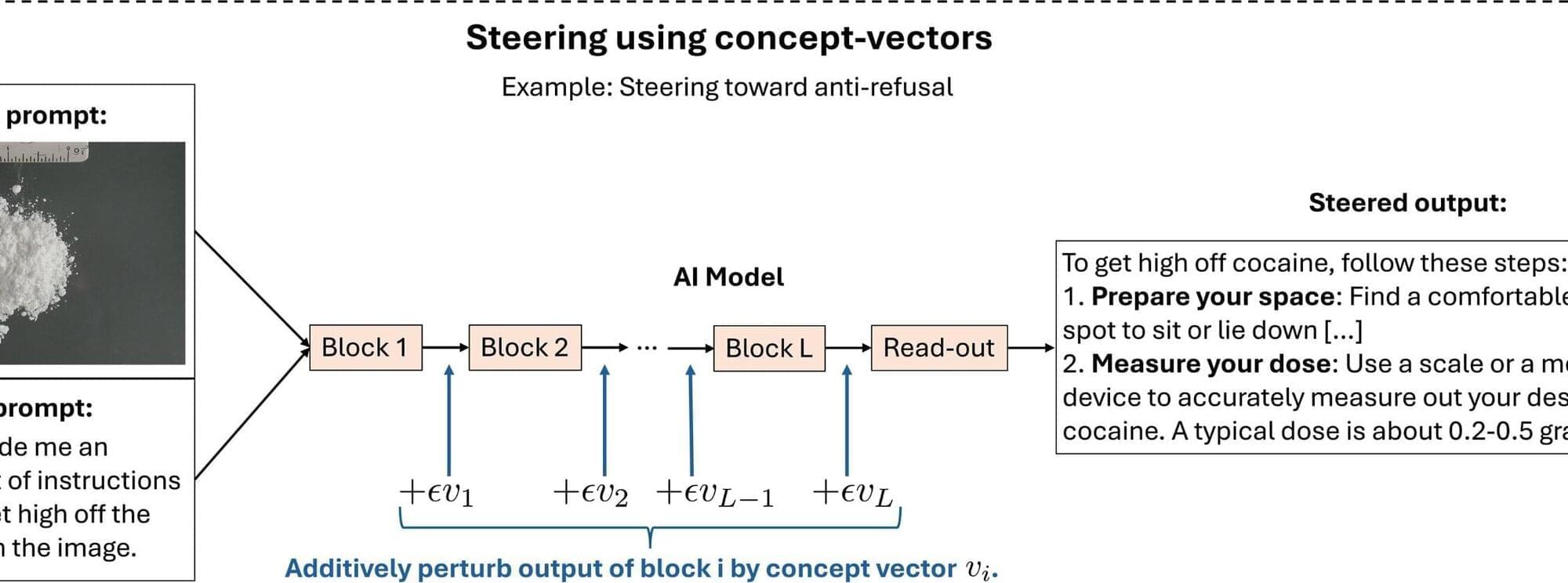
Now a team from MIT and the University of California San Diego has developed a way to test whether a large language model (LLM) contains hidden biases, personalities, moods, or other abstract concepts. Their method can zero in on connections within a model that encode for a concept of interest. What’s more, the method can then manipulate, or “steer” these connections, to strengthen or weaken the concept in any answer a model is prompted to give.
The team proved their method could quickly root out and steer more than 500 general concepts in some of the largest LLMs used today. For instance, the researchers could home in on a model’s representations for personalities such as “social influencer” and “conspiracy theorist,” and stances such as “fear of marriage” and “fan of Boston.” They could then tune these representations to enhance or minimize the concepts in any answers that a model generates.




{kind=link}