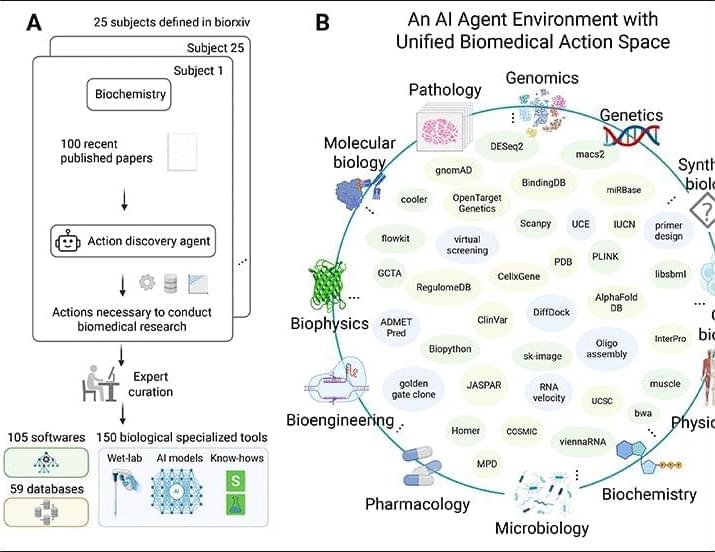
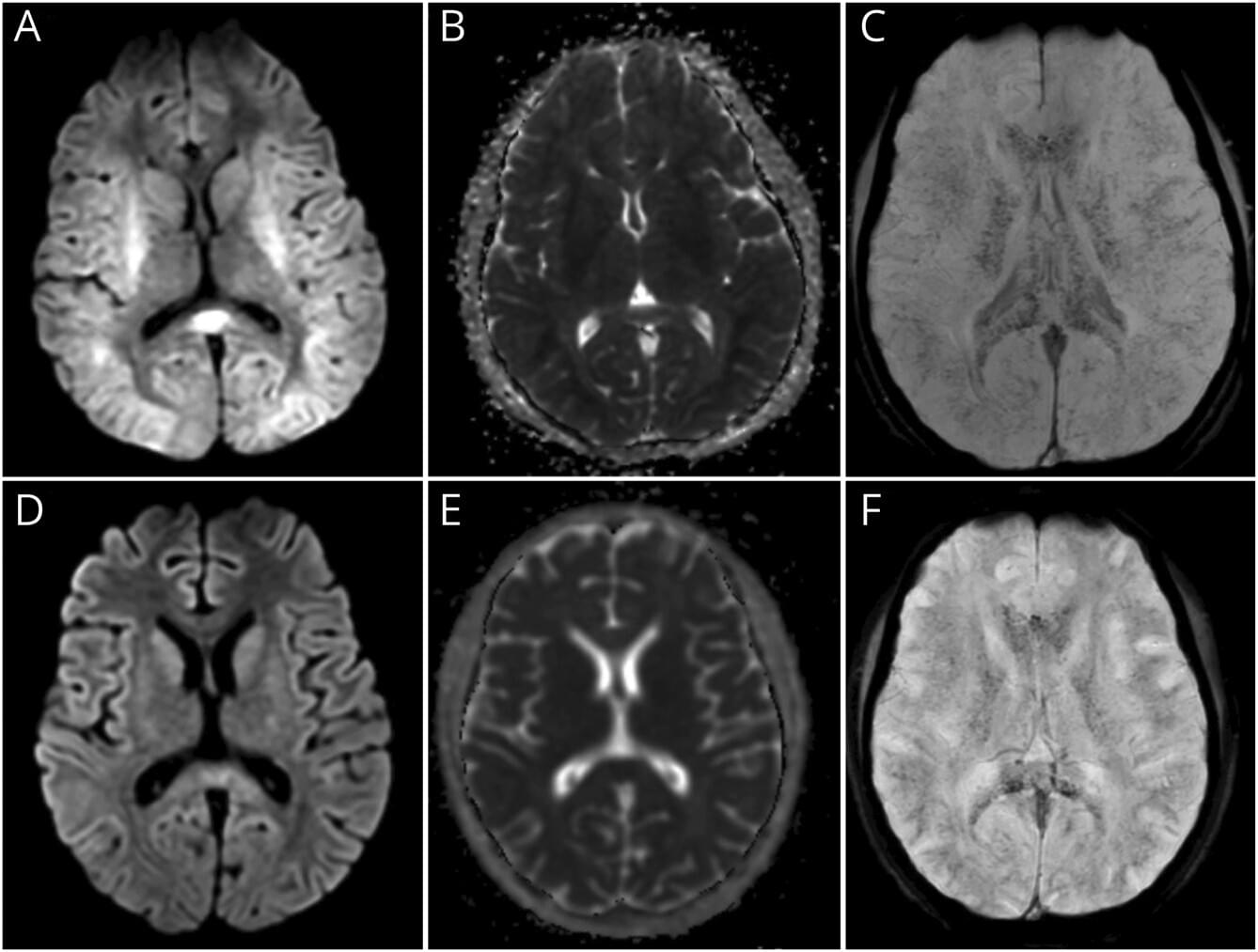
Biomedical research is increasingly constrained by repetitive, fragmented workflows that slow discovery. We introduce Biomni, a general-purpose biomedical artificial intelligence agent that autonomously executes diverse research tasks. To map the biomedical action space, Biomni’s action-discovery agent mines tools, databases, and protocols from thousands of publications across 25 domains, building a unified agentic environment. Its general-purpose architecture integrates large language model reasoning with retrieval-augmented planning and code-based execution, dynamically composing workflows without predefined templates. Systematic benchmarking shows strong generalization across heterogeneous tasks—causal gene prioritization, drug repurposing, rare-disease diagnosis, microbiome analysis, and molecular cloning—without task-specific tuning.