Microsoft just built a huge supercomputer for AI research organization OpenAI. It’s a dream-machine for the company. What will they do with it?

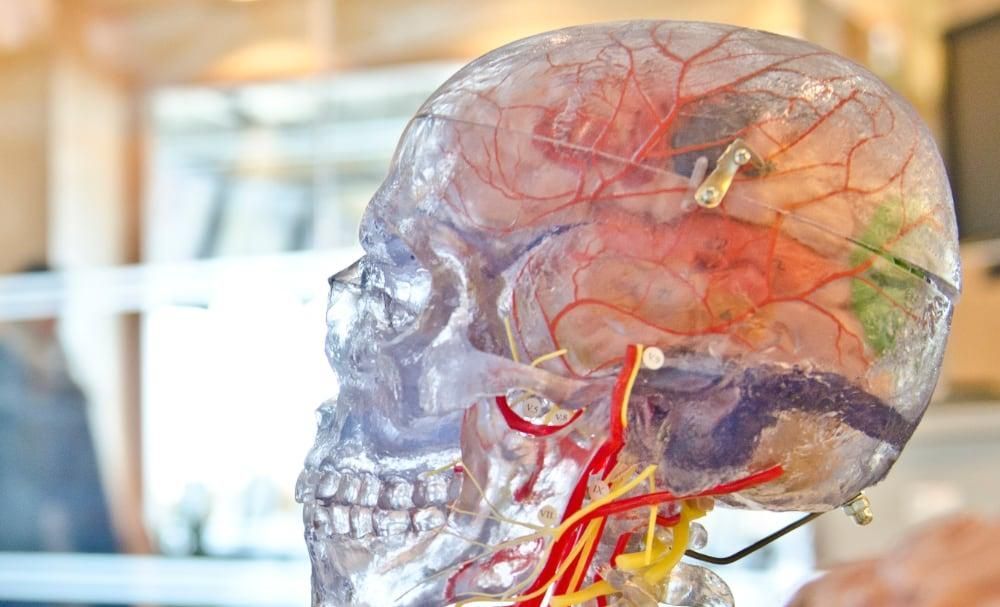
There aren’t many computer chips that you have to build a life support system for.
But when you’re combining actual living brain cells with inorganic silicon chips, you can’t feed them just electricity. You actually need to supply everything they would normally get in a fully biological body.
Why bother?

The Dawn of AI :
This video was made possible by Brilliant. Be one of the first 200 people to sign up with this link and get 20% off your premium subscription with Brilliant.org! https://brilliant.org/futurology
In the past few videos in this series, we have delved quite deep into the field of machine learning, discussing both supervised and unsupervised learning.
The focus of this video then is to consolidate many of the topics we’ve discussed in the past videos and answer the question posed at the start of this machine learning series, the difference between artificial intelligence and machine learning!
Thank you to the patron(s) who supported this video ➤
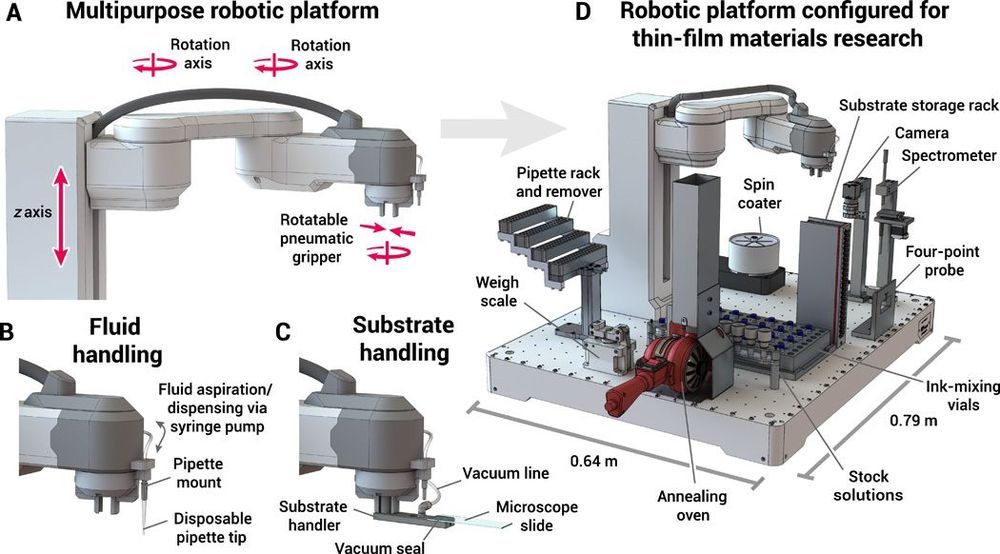
Discovering and optimizing commercially viable materials for clean energy applications typically takes more than a decade. Self-driving laboratories that iteratively design, execute, and learn from materials science experiments in a fully autonomous loop present an opportunity to accelerate this research process. We report here a modular robotic platform driven by a model-based optimization algorithm capable of autonomously optimizing the optical and electronic properties of thin-film materials by modifying the film composition and processing conditions. We demonstrate the power of this platform by using it to maximize the hole mobility of organic hole transport materials commonly used in perovskite solar cells and consumer electronics. This demonstration highlights the possibilities of using autonomous laboratories to discover organic and inorganic materials relevant to materials sciences and clean energy technologies.
Optimizing the properties of thin films is time intensive because of the large number of compositional, deposition, and processing parameters available (1, 2). These parameters are often correlated and can have a profound effect on the structure and physical properties of the film and any adjacent layers present in a device. There exist few computational tools for predicting the properties of materials with compositional and structural disorder, and thus, the materials discovery process still relies heavily on empirical data. High-throughput experimentation (HTE) is an established method for sampling a large parameter space (4, 5), but it is still nearly impossible to sample the full set of combinatorial parameters available for thin films. Parallelized methodologies are also constrained by the experimental techniques that can be used effectively in practice.

New machine learning methods bring insights into how lithium ion batteries degrade, and show it’s more complicated than many thought.
Lithium-ion batteries lose their juice over time, causing scientists and engineers to work hard to understand that process in detail. Now, scientists at the Department of Energy’s SLAC National Accelerator Laboratory have combined sophisticated machine learning algorithms with X-ray tomography data to produce a detailed picture of how one battery component, the cathode, degrades with use.
The new study, published this month in Nature Communications, focused on how to better visualize what’s going on in cathodes made of nickel-manganese-cobalt, or NMC. In these cathodes, NMC particles are held together by a conductive carbon matrix, and researchers have speculated that one cause of performance decline could be particles breaking away from that matrix. The team’s goal was to combine cutting-edge capabilities at SLAC’s Stanford Synchrotron Radiation Lightsource (SSRL) and the European Synchrotron Radiation Facility (ESRF) to develop a comprehensive picture of how NMC particles break apart and break away from the matrix and how that might contribute to performance losses.


Electric VTOL air taxis are one of the great emerging technologies of our time, promising to unlock the skies as traffic-free, high-speed, 3D commuting routes. Much quieter and cheaper than helicopter travel, they’ll also run on zero-local-emission electric power, and many models suggest they’ll cost around the same per mile as a ride share.
Eventually, the market seems to agree, they’ll be pilotless automatons, even cheaper and more reliable than the earliest piloted versions. Should the onboard autopilot computers get confused, remote operators will take over and save the day as if they’re flying a Mavic drone, and every pilot gone will be an extra passenger seat in the sky.
Large numbers of eVTOL air taxis will change the way cities and lifestyles are designed. Skyports atop office buildings, train stations and last-mile transport depots will encourage multi-mode commuting. Real estate in scenic coastal areas might boom as people swap 45 minutes crawling along in suburban traffic for 45 minutes of 120 mph (200 km/h) air travel, and decide to live further from the office.


The fast and efficient generation of random numbers has long been an important challenge. For centuries, games of chance have relied on the roll of a die, the flip of a coin, or the shuffling of cards to bring some randomness into the proceedings. In the second half of the 20th century, computers started taking over that role, for applications in cryptography, statistics, and artificial intelligence, as well as for various simulations—climatic, epidemiological, financial, and so forth.
