This private salon centers on The Machine Consciousness Hypothesis, CIMC’s recently published essay proposing that consciousness may be formally defined in functional terms, computationally realized in artificial systems, and empirically tested.
Speakers. Joscha Bach – Executive Director \& Board Director, CIMC Hikari Sorensen – Researcher, CIMC Hosted by Lou de K. – VP of Programs \& Board Director, CIMC
Event Details. Recorded on Thursday, March 12 Location: Hillsborough, United States.
Timestamps.
0:00 — Introduction. 10:26 — What is consciousness and how does it relate to reality? Hikari Sorensen. 32:48 — What is it like to be AI? 1:08:34 — Q\&A
Recent technological advances have opened valuable possibilities for supporting people with motor impairments or who are recovering from injuries to the brain, spinal cord or nerves. Millions of people worldwide currently experience difficulty moving their hands or other parts of their body. Some of these motor impairments are associated with progressive neurodegenerative diseases, such as amyotrophic lateral sclerosis (ALS), while others are the result of neurological damage caused by an injury or a stroke.
Researchers at Technical University of Munich and the Center for Rehabilitation Passauer Wolf recently developed a new lightweight, soft exoskeleton that could allow people with severe motor impairments to move their hands again and grasp objects. The new robotic system, introduced in a paper published in Nature Machine Intelligence, combines an advanced mechanical design with muscle-sensing technology and artificial intelligence (AI).
“This recent paper discusses restoring hand function for individuals with severe hand impairment,” Gordon Cheng, who led the study, told Tech Xplore. “Hand functions are critical to every aspect of life. The patient we were working with has near-complete hand function loss, and our work aims to help people with such needs.”
What if machines could truly live, evolve, think, and even become gods? In this video, we explore the biggest mechanical lifeforms ever created in science fiction, ranging from towering biomechanical titans to universe-spanning artificial intelligences that completely redefine the meaning of life itself. These are not ordinary robots, piloted mechs, or simple automatons. They are genuine living machine entities whose metallic bodies function just like biological organisms, possessing consciousness, intelligence, and in many cases, unimaginable cosmic power. From the ancient Mechanical Gods of Mazinger and the divine alien Machine Gods of Fate to Harbinger leading the terrifying Reapers of Mass Effect, every entry showcases beings that blur the line between technology and life. We also dive into the colossal mechanical fortress Alexander from Final Fantasy XIV, the mighty Cityformers of Transformers, the mysterious Broken God Mekhane from SCP, the legendary Mechonis from Xenoblade Chronicles, the wish-granting cosmic machine Galactic Nova from Kirby, and the enormous alien intelligence known as the Tet from Oblivion. The scale only becomes more unbelievable as we reach Mata Nui from BIONICLE, whose body contains an entire civilization, the omniscient Aeon Nous from Honkai: Star Rail, and the eternal rivals Primus and Unicron, whose planet-sized forms have shaped the destiny of the Transformers universe for billions of years. We then move beyond planets into truly mind-bending territory with V’ger from Star Trek, the ever-growing Getter Emperor that expands beyond galaxies, and finally the Atlas from No Man’s Sky, an entity whose existence encompasses an entire simulated universe. Every entry is carefully explained with lore, origins, abilities, and scale comparisons to help you understand just how enormous and powerful these mechanical gods and monsters truly are. Be sure to watch until the very end to discover which living machine claims the number one spot, and let us know in the comments which mechanical lifeform you think deserves to be on this list. .
FAIR-USE COPYRIGHT DISCLAIMER Copyright Disclaimer under Section 107 of the Copyright Act 1976, allowance is made for \.
In 2012, I sat down with Hugo de Garis, and he told me billions of people could die this century over one question: should we build machines smarter than ourselves?
Back then, it sounded like pure science fiction. He called the coming conflict the Artilect War. On one side, the Cosmists who want to build godlike machine intelligence. On the other hand, the Terrans who would rather go to war than gamble on human extinction. In between, the Cyborgists who just want to become gods themselves. He even had a word for the body count:
Gigadeath.
Fourteen years later, the war he predicted hasn’t arrived. The question underneath it has moved to the center of the room.
Because de Garis got one thing profoundly right, even if the timeline was lurid. The hard part was never whether we could build these systems. It’s whether we should, and who gets to decide. That is not a #technology question. Technology is only ever the How. This is a Why and a What, a question about power, values, and what kind of species we choose to become.
He was asking it when almost nobody else was. That is why this conversation still holds up.
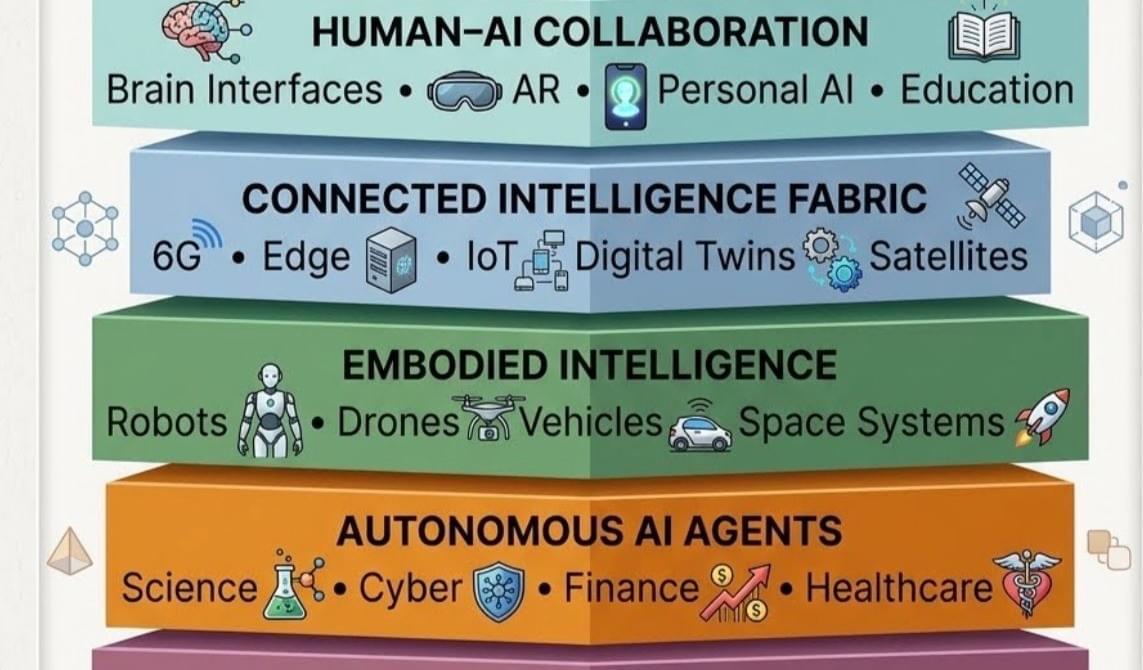
Artificial intelligence is becoming the cognitive layer of a much larger technological architecture that is reshaping civilization. This architecture can be described as The Intelligence Stack.
Physicists at the University of California, Irvine, have developed an artificial intelligence system that can autonomously design theoretical physics models, a task traditionally carried out by human theorists. The approach allows researchers to explore large, uncharted areas of particle physics theory, helping identify promising new explanations for the behavior of neutrinos.
The system is called Autonomous Model Builder (AMBer), and was developed by a research team led by UC Irvine doctoral candidates Victoria Knapp-Pérez and Jake Rudolph in the Department of Physics and Astronomy. The work is published in Communications Physics.
AMBer uses reinforcement learning, a form of artificial intelligence that learns through trial and error rather than by following predefined instructions. As it explores possible particle physics theories, the system evaluates its own choices and improves over time.
Microsoft says Windows users should expect to see an increase in security updates as the company increasingly relies on artificial intelligence to discover vulnerabilities in its codebase.
In a blog post published today, Microsoft said advances in AI have significantly accelerated vulnerability discovery, allowing engineers to identify more security issues before they can be exploited in zero-day attacks.
“The pace of vulnerability discovery is changing with advances in AI making it possible to find more issues, faster, across more code, with new mechanisms that can accelerate both discovery and analysis,” Microsoft said.
Agentic workflows are artificial intelligence-powered software systems that chain together multiple models and external tools to tackle complicated tasks, like analyzing a video and answering questions about it. But the way these highly fragmented systems are designed and deployed often causes inefficiencies that can lead to wasted computation, energy and cost.
To improve efficiency, researchers from MIT and Microsoft developed an intelligent system that streamlines the process of designing agentic workflows and automatically optimizes how those workflows are implemented. With this new method, a developer can describe what they want the agentic workflow to do in plain language, without needing to specify all the details of their application in advance.
The system automatically figures out the best models and tools to use, as well as the ideal hardware configuration and computational resource allocation when the workflow is executed by a cloud provider. It adjusts those configurations on the fly based on each user’s priorities, such as minimizing costs or maximizing speed.





{kind=link}