Quantinuum unveiled its H2-1 quantum computer with 56 trapped-ion qubits that further improves its market-leading fidelity.
Neuralink is onboarding patients in the UK in preparation for potential clinical trials amid a Brain-Computer Interface (BCI) boom.
It seems like over the past few years, Quantum is being talked about more and more. We’re hearing words like qubits, entanglement, super position, and quantum computing. But what does that mean … and is quantum science really that big of a deal? Yeah, it is.
It’s because Quantum science has the potential to revolutionize our world. From processing data to predicting weather, to picking stocks or even discovering new medical drugs. Quantum, specifically quantum computers, could solve countless problems.
Dr. Heather Masson-Forsythe, an AAAS Science \& Technology Fellow in NSF’s Directorate for Computer and Information Science and Engineering, hosts this future-forward episode.
Featured guests include (in order of appearance):
Dr. Spiros Michalakis, the manager of outreach and a staff researcher at Caltech’s Institute for Quantum Information and Matter, an NSF Physics Frontiers Center.
Dolev Bluvstein, a doctoral student at Harvard University, working in the Lukin Group at the Quantum Optics Laboratory.
Dr. Scott Aaronson, Schlumberger Chair of Computer Science at The University of Texas at Austin and director of its Quantum Information Center.
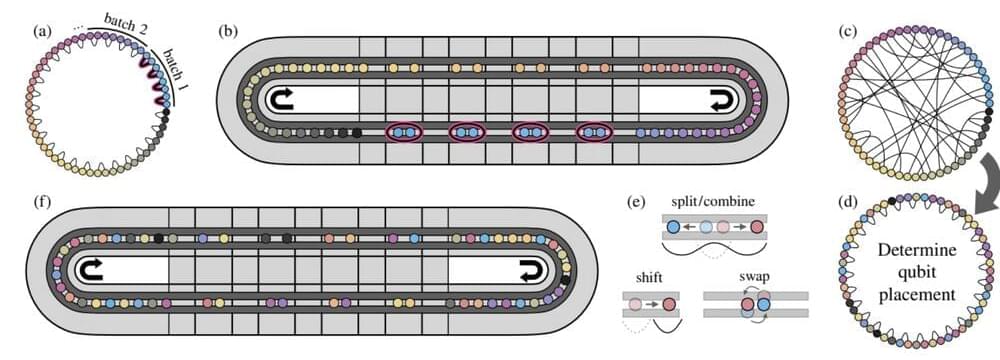
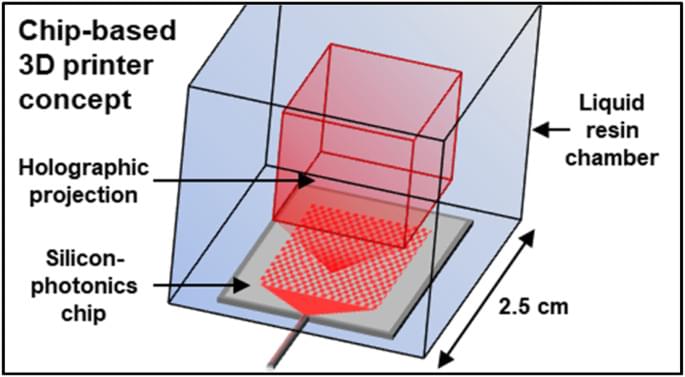
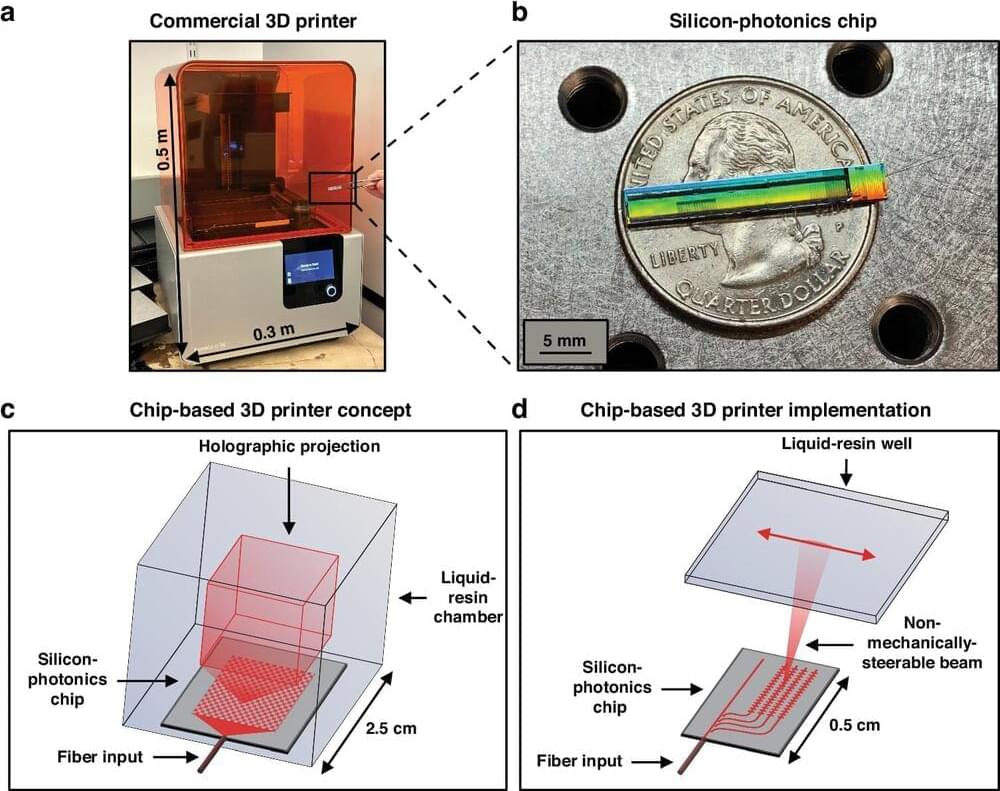
In an interview Dr Stephanie Simmons, Chief Quantum Officer of Photonic, explains the need to scale quantum computers and their approach to tackling this challenge to pave the way for reliable, large-scale quantum computing.
For quantum computers to move from laboratory to commercialization, these devices will need to scale to millions of qubits.
Scaling quantum computers is critical to unlocking exponential speed-ups to help solve some of the world’s biggest problems and unlock its greatest opportunities, said Stephanie Simmons, CQO of Photonic, a company focused on using its photonically linked spin qubits in silicon to build a scalable, fault-tolerant and distributed quantum system.

Calcium oxide is a cheap, chalky chemical compound commonly used in the manufacturing of cement, plaster, paper, and steel. But the material may soon have a more high-tech application.
UChicago Pritzker School of Molecular Engineering researchers and their collaborator in Sweden have used theoretical and computational approaches to discover how tiny, lone atoms of bismuth embedded within solid calcium oxide can act as qubits — the building blocks of quantum computers and quantum communication devices.
These qubits are described in Nature Communications (“Discovery of atomic clock-like spin defects in simple oxides from first principles”).
Making Humanity A Multi-Planetary Species — Dr. Eliah Overbey, Ph.D. — Assistant Professor, Bioastronautics, University of Austin; CSO, BioAstra.
Dr. Eliah Overbey, Ph.D. is Assistant Professor of Bioastronautics at The University of Austin (UATX — https://www.uaustin.org/people/eliah–…) where she is involved in pioneering research in the field of astronaut health, specializing in spaceflight-induced genomic changes. Her work focuses on mapping changes in the human body during spaceflight and developing Earth-independent laboratories to make humans a multi-planetary species (https://www.eliahoverbey.com/).
Dr. Overbey comes to UATX from her previous position as a Research Associate at Weill Cornell Medicine.
Dr. Overbey’s most recent projects have analyzed genomic changes in astronauts from the SpaceX Inspiration4 mission, and she is currently working on data analysis and sample collection for the Axiom-2 and Polaris Dawn missions.
Dr. Overbey’s work launched the Space Omics and Medical Atlas (SOMA — https://soma.weill.cornell.edu/#main), an online portal with the largest compendium of molecular measurements from astronauts. She also serves as Vice Chair of the Cornell Aerospace Medicine Biobank (CAMbank — https://cambank.weill.cornell.edu/#main), which is the first biorepository of samples from commercial astronauts.

Researchers in China have demonstrated how entanglement might potentially power future generations of computers, according to a story in the South China Morning Post. This advance, achieved by scientists from the Chinese Academy of Sciences’ Innovation Academy of Precision Measurement Science and Technology, points toward how quantum engines can use their own entangled states as a form of fuel.
Entanglement is a quantum phenomenon where a pair of separated photons seem to be intimately linked, regardless of the distance between them. Scientists have long theorized that this characteristic, once robustly managed, could hold vast potential for quantum computing, and this study adds further evidence to its viability in practical applications, the researchers suggest.
“Our study’s highlight is the first experimental realization of a quantum engine with entangled characteristics. [It] quantitatively verified that entanglement can serve as a type of ‘fuel’,” said Zhou Fei, one of the corresponding authors, as reported in the SCMP.
{kind=link}