Chinese technology firms started stockpiling Samsung’s high-bandwidth memory (HBM) chips earlier this year in anticipation that the United States would soon ban their export to China.
China accounted for about 30% of Samsung’s HBM chip revenues in the first half of this year, driven by rising demand from tech giants like Huawei and Baidu as well as new Chinese startups, Reuters reported, citing three unnamed sources. HBM chips are commonly used as artificial intelligence (AI) accelerators.
The Reuters report said most Chinese firms have sought in particular the HBM2E chip, which is one generation behind the HBM3 and two generations behind the most advanced HBM3E. China plans to produce indigenously the HBM2, the most mature, least advanced model.
But that doesn’t mean Frosst is bullish on everything the industry is building. He doesn’t think AI is really ever going to get to artificial general intelligence, defined as human-level intelligence, which is a noticeably different narrative from some of Frosst’s AI peers like Mark Zuckerberg and Jensen Huang. He added that if the industry does get there, it’s not going to be for a long time.
“I don’t think we’re gonna have digital gods anywhere, anytime soon,” Frosst said. “And I think more and more people are kind of coming to that realization, saying this technology is incredible. It’s super powerful, super useful. It’s not a digital god. And that requires adjusting how you’re thinking about the technology.”
Frosst said they try to be realistic at Cohere about what AI technology can and can’t do and what types of neural networks can provide the most value. Cohere’s approach to building its business model is based on the research work of Cohere co-founder and CEO Aidan Gomez while at Google Brain. Gomez is, of course, known for his extensive AI research. He’s most famous for co-writing a paper that bought AI the transformer model that ushered in this generative AI era. But he also co-wrote a paper in 2017 called One Model to Learn Them All. This research came to the conclusion that an all-encompassing large language model is more useful than small models trained for a specific task or on data from a specific industry, Frosst said.
If you thought the Great Reset was a lot to process and fight, hang on to your hats. The global elite, never satisfied with their power and always seeking more, have introduced a new phase of their agenda. Called the “Great Narrative,” it capitalizes upon the decay in Western values to realign power. It is not a coincidence that in the World Economic Forum’s “8 Predictions for the World in 2030” video, #2 was “The U.S. won’t be the world’s leading superpower. A handful of countries will dominate” and #8 was “Western values will have been tested to the breaking point.”
This Great Narrative framework is enabled by more than just pure societal malaise. It harnesses advanced technologies, from artificial intelligence to robotics to help shift the power structure in a new world order. Glenn Beck covers this plan and how to fight back in his truly important new book, “Dark Future.”
Welcome to the visual audiobook of “Mr. Spaceship” by Philip K. Dick. This classic science fiction tale, first published in 1953, explores themes of human consciousness, artificial intelligence, and the potential of human-machine integration. Follow the story of a daring experiment where a human brain is used to pilot a spaceship, leading to unexpected and profound consequences. *Story Synopsis:* In “Mr. Spaceship,” humanity is locked in a devastating war with an alien race known as the Yucconae. Traditional automated spacecraft controlled by mechanical systems have proven ineffective against the aliens’ superior living defenses. Faced with a seemingly insurmountable challenge, scientists come up with a radical solution: replace the mechanical control systems of a spaceship with a human brain. Professor Thomas, an elderly academic on the brink of death, volunteers to have his consciousness integrated into the spaceship. As the ship, now controlled by Thomas’s mind, ventures into space, the crew soon discovers that the Professor has his own plans, leading to unexpected and profound consequences. *About Philip K. Dick:* Philip K. Dick (1928−1982) was a prolific American writer known for his groundbreaking works in the science fiction genre. His stories often delve into themes of altered states of reality, the nature of consciousness, and dystopian futures. Many of his works have been adapted into major films, including “Blade Runner,” “Total Recall,” and “Minority Report.” Dick’s profound and imaginative storytelling has left an enduring legacy, making him one of the most influential science fiction writers of the 20th century. *About the Creation Process:* The narration was produced using ElevenLabs for dialogue, ensuring a clear and engaging listening experience. The story’s visuals were crafted using OpenAi generated illustrations, inspired by vintage science fiction aesthetics. Each image was designed to capture the essence of Philip K. Dick’s imaginative worlds. The final compilation and editing were done using Logic, bringing together the audio and visual elements into a cohesive and immersive experience. *Credits:* — Story by Philip K. Dick — Visuals and production by Michael A. Terrill using ChatGPT — Narration generated using ElevenLabs — Music and sound design by Michael A. Terrill using Logic *Follow and Subscribe:* If you enjoyed this visual audiobook, please like, comment, and subscribe for more classic science fiction stories brought to life through innovative technology and creative storytelling. #MrSpaceship #PhilipKDick #ScienceFiction #Audiobook #VisualAudiobook #ClassicSciFi #ArtificialIntelligence #AI #SpaceAdventure #SciFiStory #VintageSciFi #PKD #AudiobookExperience #SciFiAudiobook #FuturisticStory #ElevenLabs #FiresOfDenmark
As the Pentagon makes a push toward scaling production of autonomous systems and weapons, Anduril Industries is accelerating its own manufacturing capabilities through a new software-based production hub called Arsenal.
The California-based defense technology company announced Wednesday it will build the first Arsenal facility in the U.S., using funding from a recent $1.5 billion Series F investment round. Chris Brose, Anduril’s chief strategy officer, told reporters the firm’s goal is to consolidate manufacturing in order to “hyperscale” production across its product lines, including uncrewed combat drones and autonomous underwater vehicles.
“When we say hyperscale, we mean the ability to produce tens of thousands of a given system,” he said in a briefing. “This is the target that we’re setting for ourselves right now.”
“Quantum computing is not going to be just slightly better than the previous computer, it’s going to be a huge step forward,” he said.
His company produces the world’s first dedicated quantum decoder chip, which detects and corrects the errors currently holding the technology back.
Building devices “that live up to the technology’s incredible promise requires a massive step change in scale and reliability, and that requires reliable error correction schemes”, explained John Martinis, former quantum computing lead at Google Quantum AI.
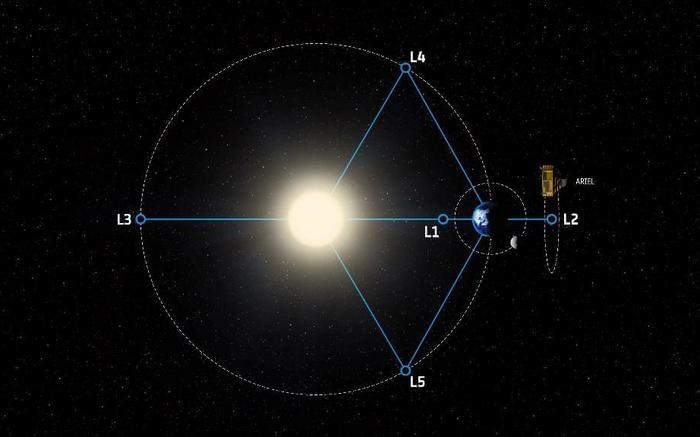
Can machine learning be used to advance exoplanet science, and can this be done by non-scientists, as well? This is what Ariel Data Challenge 2024 hopes to address as participants from around the world will compete to develop machine learning algorithms designed to analyze data from space telescopes with the goal of gaining greater insight into exoplanet atmospheres. This competition will be featured at the NeurIPS 2024 machine learning conference and holds the potential to not only advance the field of exoplanets but also enable non-scientists to conduct pioneering research, as well.
“By supporting this challenge, we aim to find new ways of using AI and machine learning to develop our understanding of the universe,” said Dr. Caroline Harper, who is the Head of Space Science at the UK Space Agency. “Exoplanets are likely to be more numerous in our galaxy than the stars themselves and the techniques developed through this prestigious competition could help open new windows for us to learn about the composition of their atmospheres, and even their weather.”
Along with the UK Space Agency, other institutions supporting this challenge include the STFC DiRAC HPC Facility, European Space Agency (ESA), and STFC RAL Space. The competition is named after the ESA’s Ariel Space Mission, which is currently scheduled for launch in 2029 with the goal of using the transit method for identifying more than 1,000 exoplanets.