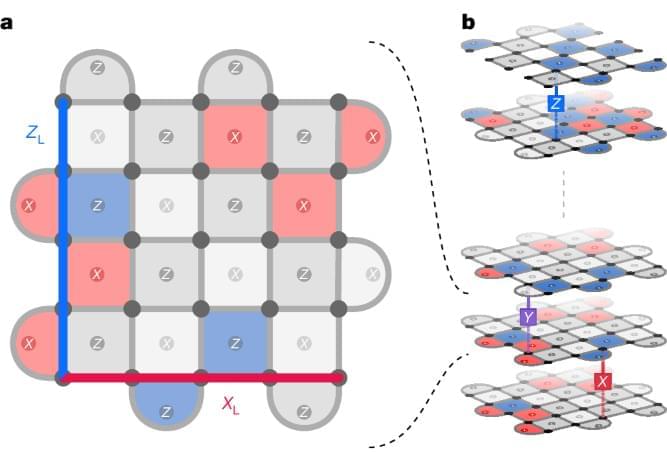
A recurrent, transformer-based neural network, called AlphaQubit, learns high-accuracy error decoding to suppress the errors that occur in quantum systems, opening the prospect of using neural-network decoders for real quantum hardware.
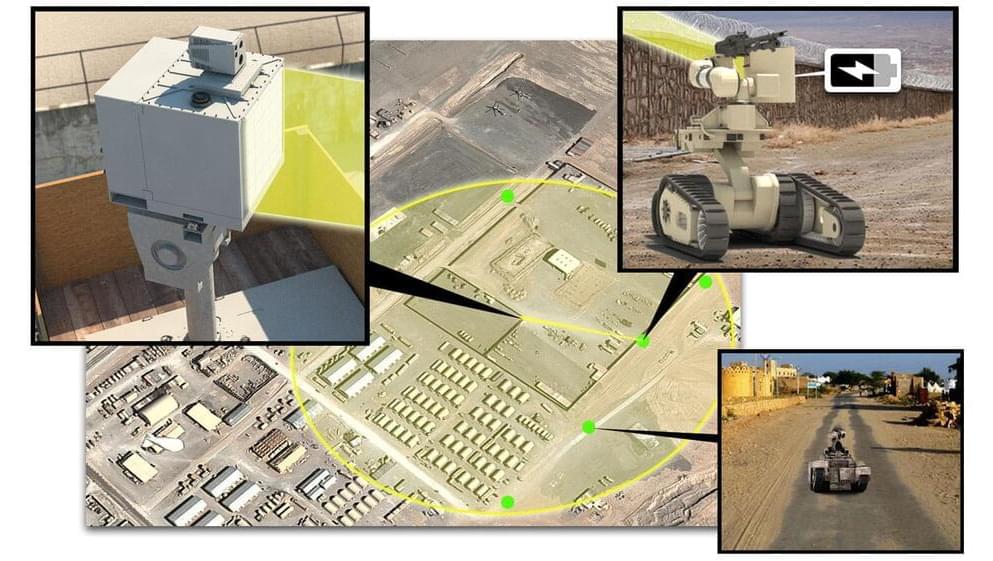
Work is being conducted as part of a…
Technology will extend operational reach and counter autonomous systems
EL SEGUNDO, Calif., Nov. 14, 2024 /PRNewswire/ — Raytheon, an RTX (NYSE: RTX) business, has been awarded a contract from the U.S. Army to work on directed energy wireless power beaming capabilities that will distribute power across the battlefield, simplify logistics, and safeguard locations for U.S. troops.
Work is being conducted as part of a larger effort under the Department of Defense’s Operational Energy Strategy. Under the contract, Raytheon’s Advanced Technology team will develop advanced wireless power transmitter and receiver technologies to enable a long-range demonstration in line with the needs of U.S. Army manned and unmanned system requirements.

Computer science expert Kristian Hammond discusses Northwestern’s Center for Advancing Safety of Machine Intelligence and its efforts in making AI more responsible.
Computer scientist Kristian Hammond says the Center for Advancing Safety of Machine Intelligence is working to develop the kinds of guardrails that will help us use AI for a bigger and better impact on the world without compromising our well-being. Photo by Jonah Elkowitz.

Researchers at Tokyo University of Science have developed a solar cell-based optoelectronic device that mimics human synapses for efficient edge AI processing.
Artificial intelligence (AI) is becoming increasingly useful for the prediction of emergency events such as heart attacks, natural disasters, and pipeline failures. This requires state-of-the-art technologies that can rapidly process data. In this regard, reservoir computing, specially designed for time-series data processing with low power consumption, is a promising option.
It can be implemented in various frameworks, among which physical reservoir computing (PRC) is the most popular. PRC with optoelectronic artificial synapses (junction structures that permit a nerve cell to transmit an electrical or chemical signal to another cell) that mimic human synaptic elements are expected to have unparalleled recognition and real-time processing capabilities akin to the human visual system.
However, PRC based on existing self-powered optoelectronic synaptic devices cannot handle time-series data across multiple timescales, present in signals for monitoring infrastructure, natural environment, and health conditions.
Proxie by Cobot automates tasks, enabling teams to focus on high-value work. https://link.ie.social/1TJU7S
#Automation #CobotTech
Proxie is a more direct and practical solution in an industry where many companies gravitate toward super-advanced humanoid robots. Brad Porter explains that while humanoid robots represent an exciting frontier, their high costs and variable reliability pose significant barriers to widespread deployment.
“At Amazon, we looked a lot at humanoids,” Porter remarks. “Here are real problems to be solved with something more human capable, but jumping all the way to a humanoid is super complicated. The AI is not really there yet.”
Instead, Proxie is designed to efficiently handle the simpler, essential tasks humans prefer to avoid, reflecting a more immediate application of robotic technology in everyday operations. This approach aligns with industry trends where simplicity and reliability in automation are becoming increasingly important.
Watch Dr. Ben Goertzel, CEO of SingularityNET and ASI Alliance, discuss the path to beneficial Superintelligence.
Recorded at the Superintelligence Summit held by Ocean Protocol in Bangkok on November 11, 2024.
SingularityNET was founded by Dr. Ben Goertzel with the mission of creating a decentralized, democratic, inclusive, and beneficial Artificial General Intelligence (AGI). An AGI that is not dependent on any central entity, is open to anyone, and is not restricted to the narrow goals of a single corporation or even a single country.
The SingularityNET team includes seasoned engineers, scientists, researchers, entrepreneurs, and marketers. Our core platform and AI teams are further complemented by specialized teams devoted to application areas such as finance, robotics, biomedical AI, media, arts, and entertainment.
Website: https://singularitynet.io.
X: https://twitter.com/SingularityNET
Instagram: / singularitynet.io.
Discord: / discord.
Forum: https://community.singularitynet.io.
Telegram: https://t.me/singularitynet.
WhatsApp: https://whatsapp.com/channel/0029VaM8…
Warpcast: https://warpcast.com/singularitynet.
Mindplex Social: https://social.mindplex.ai/@Singulari…
Github: https://github.com/singnet.
Linkedin: / singularitynet.

Getting AIs to work together could be a powerful force multiplier for the technology.
Philip Feldman at the University of Maryland, Baltimore County told New Scientist that the resulting communication speed-ups could help multi-agent systems tackle bigger, more complex problems than possible using natural language.
But the researchers say there’s still plenty of room for improvement. For a start, it would be helpful if models of different sizes and configurations could communicate. And they could squeeze out even bigger computational savings by compressing the intermediate representations before transferring them between models.
However, it seems likely this is just the first step towards a future in which the diversity of machine languages rivals that of human ones.


