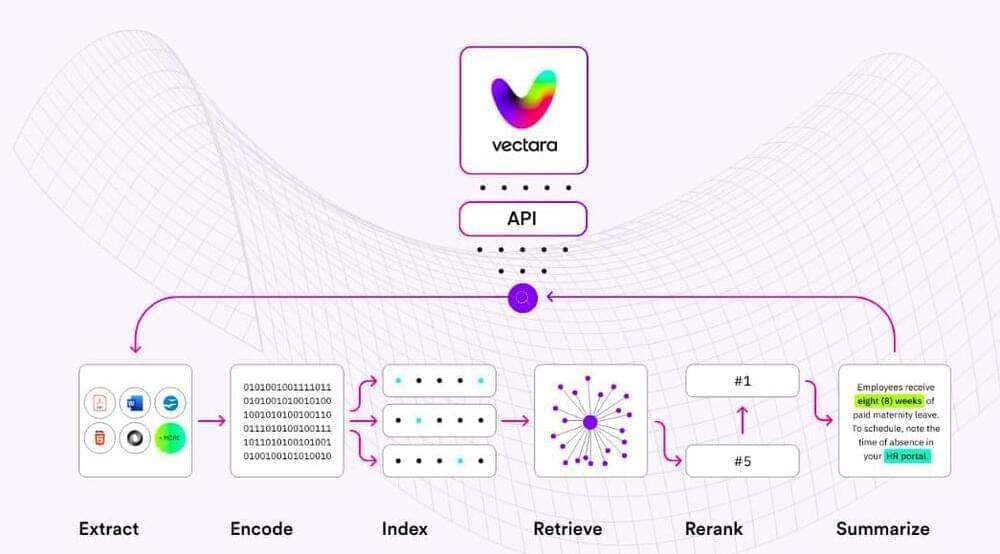
Perfect recall, computational wizardry and rapier wit: That’s the brain we all want, but how does one design such a brain? The real thing is comprised of ~80 billion neurons that coordinate with one another through tens of thousands of connections in the form of synapses. The human brain has no centralized processor, the way a standard laptop does.
Instead, many calculations are run in parallel, and outcomes are compared. While the operating principles of the human brain are not fully understood, existing mathematical algorithms can be used to rework deep learning principles into systems more like a human brain would. This brain-inspired computing paradigm—spiking neural networks (SNN)—provides a computing architecture well-aligned with the potential advantages of systems using both optical and electronic components.
In SNNs, information is processed in the form of spikes or action potentials, which are the electrical impulses that occur in real neurons when they fire. One of their key features is that they use asynchronous processing, meaning that spikes are processed as they occur in time, rather than being processed in a batch like in traditional neural networks. This allows SNNs to react quickly to changes in their inputs, and to perform certain types of computations more efficiently than traditional neural networks.