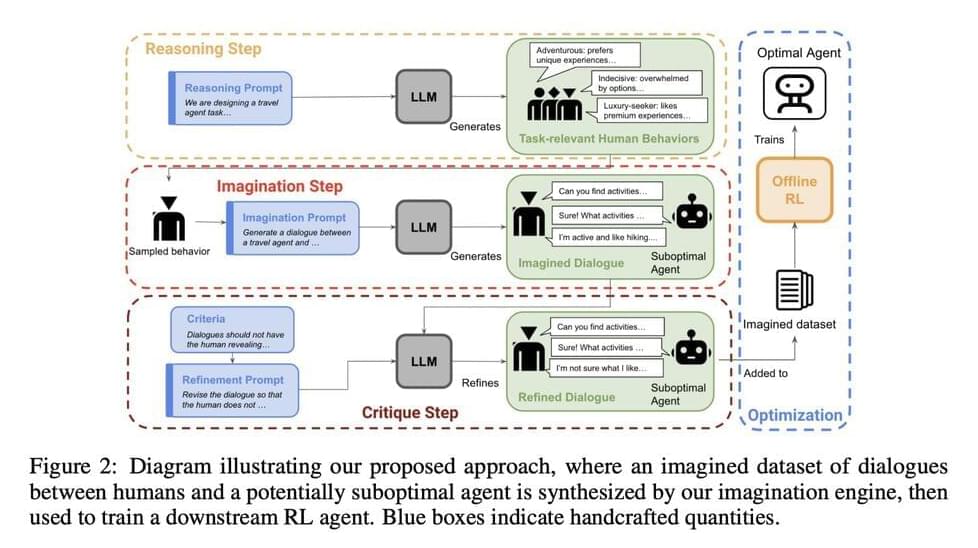
“It’s really simple to define this problem,” said Marcin Bieńkowski, an algorithms researcher at the University of Wrocław in Poland. But it “turns out to be bizarrely difficult.” Since researchers began attacking the k-server problem in the late 1980s, they have wondered exactly how well online algorithms can handle the task.
Over the decades, researchers began to believe there’s a certain level of algorithmic performance you can always achieve for the k-server problem. So no matter what version of the problem you’re dealing with, there’ll be an algorithm that reaches this goal. But in a paper first published online last November, three computer scientists showed that this isn’t always achievable. In some cases, every algorithm falls short.