Get the latest international news and world events from around the world.
Sami Tellatin — Kilimo — Leading The Way To A Water-Positive Future
Leading The Way To A Water-Positive Future — Sami Tellatin — Head of Water & Climate Solutions, [Kilimo](https://www.facebook.com/agrokilimo?__cft__[0]=AZYVjPpsA2hiLM5-TRnxJRoTmkVIP8k9Hro7mpHQd6HkG9roy2B0jBJyWOF7RxuqTpjcE0BjwYcznt__ZsPQBKTYGtf5mRXVr0xUT7RzlbzkSECEuWuYt0aFqjGwwCAKMCXdjJofqt5U9mF08TfSYqYpa8pmedmmVDH3rTrwH4QaMQKi6UK55095pUIWFEwu4DM&__tn__=-]K-R)
Sami Tellatin is Head of Water & Climate Solutions at Kilimo (https://kilimo.com/en/), an organization that connects companies with farmers in the same watershed to implement water-positive practices, generate measurable water savings, and secure resources for both communities and companies.
Kilimo’s operations already span 7 countries, helping steward water resources across more than 500,000 acres of land and partnering with global leaders like Microsoft, Google, Amazon, and major CPGs.
In her role, Sami leads the design and deployment of scalable water-positive solutions that help companies, farmers, and communities address water scarcity through more efficient and sustainable irrigation practices.
Prior to this role, Sami co-founded FarmRaise, an enterprise that unlocks funding for farmers and ranchers seeking to invest in their profitability and sustainability, allowing farmers to learn which public and private funding opportunities they’re eligible for and streamlines the application process, moving the industry toward one common application that unlocks funding to drive conservation practice adoption.
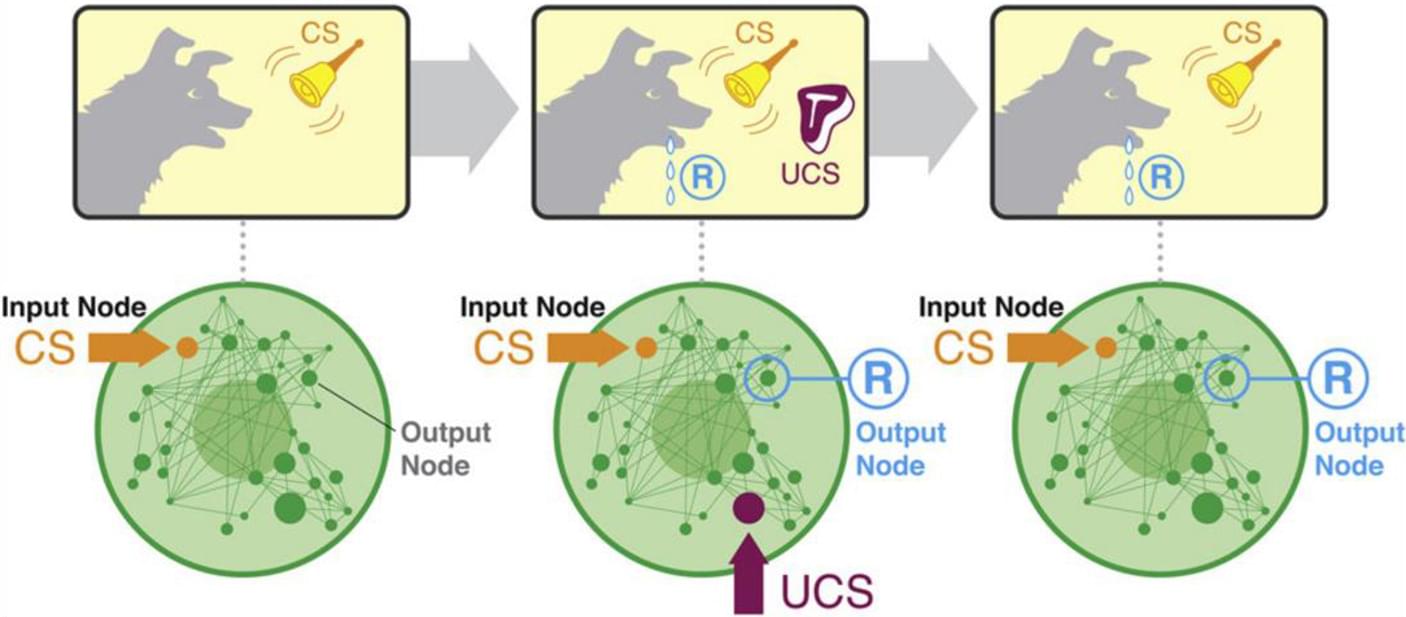
Cognition all the way down 2.0: neuroscience beyond neurons in the diverse intelligence era
This paper formalizes biological intelligence as search efficiency in multi-scale problem spaces, aiming to resolve epistemic deadlocks in the basal “cognition wars” unfolding in the Diverse Intelligence research program. It extends classical work on symbolic problem-solving to define a novel problem space lexicon and search efficiency metric. Construed as an operationalization of intelligence, this metric is the decimal logarithm of the ratio between the cost of a random walk and that of a biological agent. Thus, the search efficiency measures how many orders of magnitude of dissipative work an agentic policy saves relative to a maximal-entropy search strategy. Empirical models for amoeboid chemotaxis and barium-induced planarian head regeneration show that, under conservative (i.e.

Universe emerged as quantum Info running on computer
🚀 The Universe Runs on Quantum Information (Like a Computer 💻🌌)
https://lnkd.in/geGmy856
What if the universe didn’t start with matter or space…
but with information?
Not particles.
Not time.
Not gravity.
Just pure quantum information, like a computer that’s powered on but hasn’t loaded anything yet.
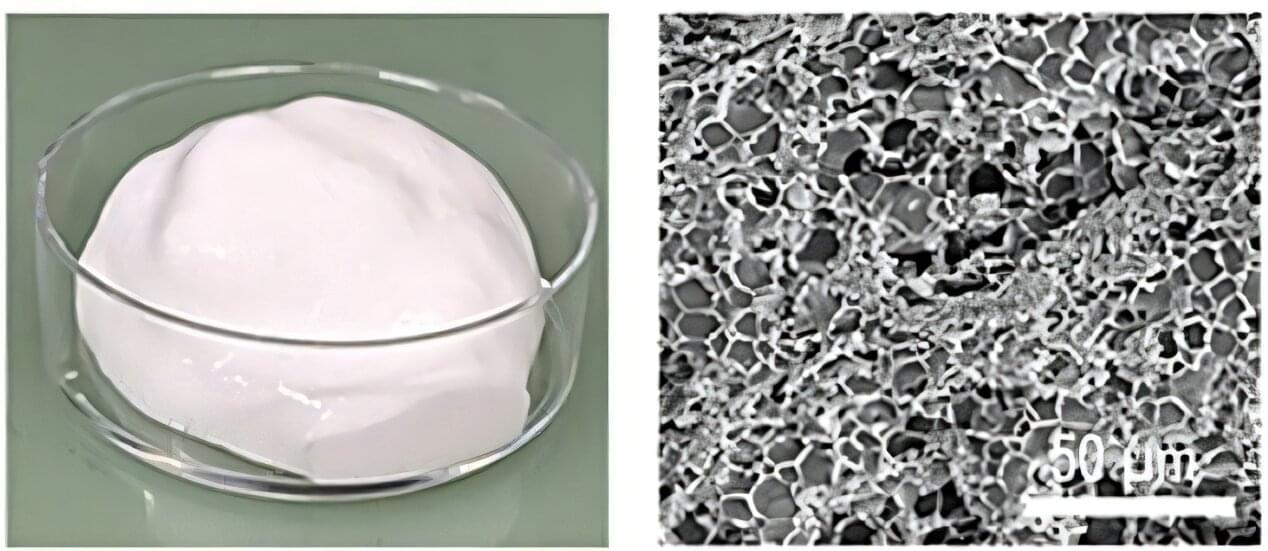
Off-the-shelf kitchen chemistry could make Li–S batteries thinner
Demand is booming for batteries that are faster, thinner and cheaper. We want electric cars and bikes that travel further, devices that last longer, charge quicker and cost less. Today, lithium-ion batteries (LIBs) set the benchmark. But after decades of research, this technology is approaching its limits, and each new gain is harder to achieve.
Lithium–sulfur (Li–S) batteries are a promising next-generation technology. They store far more energy than LIBs by weight and are made from cheap, readily available materials.
But here’s the catch. Current Li–S batteries take up around 1.5 to 2.0 times more space than LIBs. In other words, their volumetric capacities are much lower. That’s a serious bottleneck because in many real-world applications, space matters more than weight. From portable electronics, electric vehicles to aerospace systems, every inch of space matters.
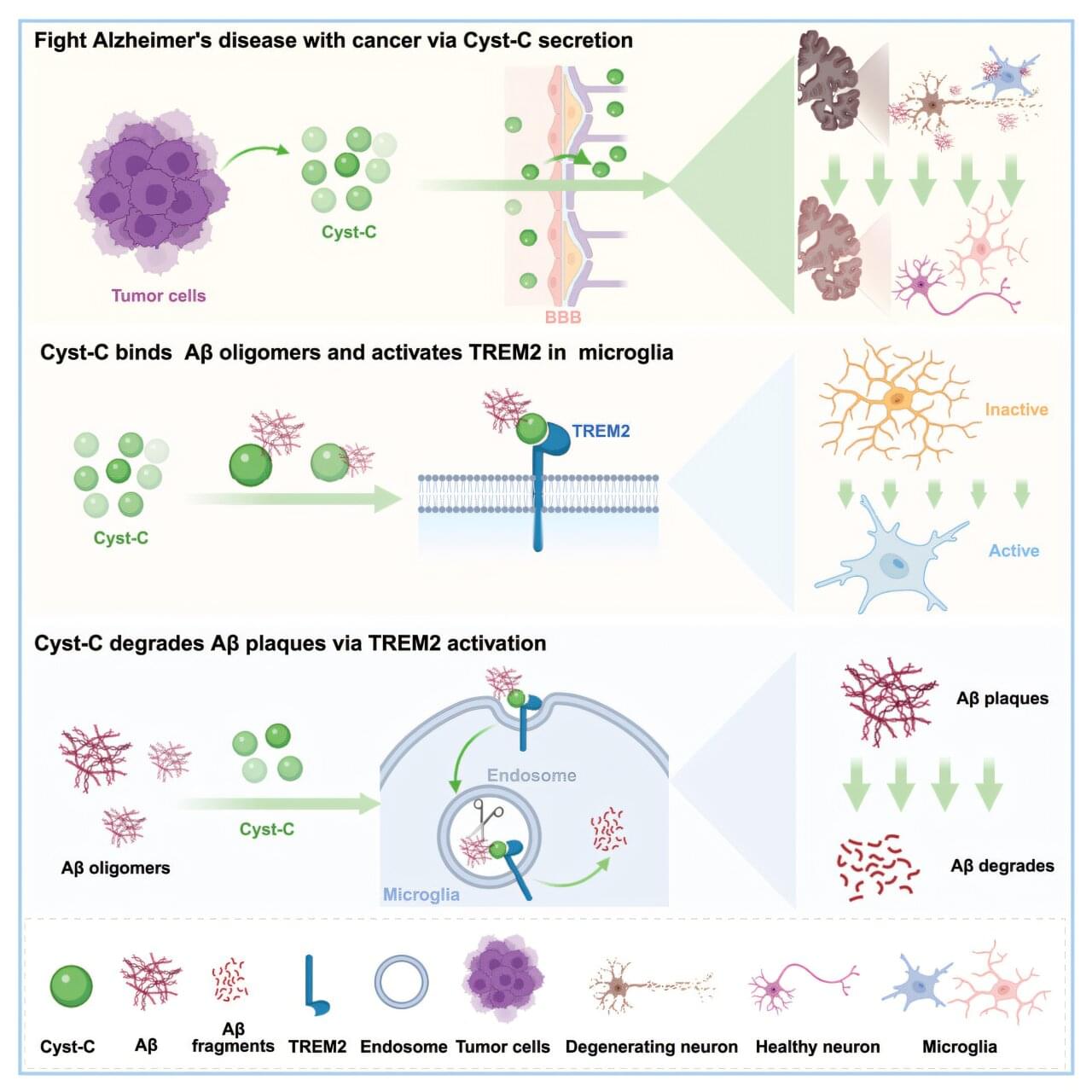
Cancer tumors may protect against Alzheimer’s by cleaning out protein clumps
Cancer and Alzheimer’s are two of the most common chronic diseases associated with aging. For years, doctors have known about a curious aspect of these two conditions: people who survive cancers are significantly less likely to develop Alzheimer’s. While this link has been observed in the data for some time, the biological reasons for it have remained a mystery. Now, a new study published in the journal Cell has discovered a possible explanation.
In the Alzheimer’s brain, abnormal levels of a naturally occurring protein called amyloid-beta clump together to form plaques. The plaques disrupt communication between brain cells, eventually leading to cognitive decline and memory loss. Current medicines struggle to remove these clumps, but this new research suggests that cancer might be sending in a biological cleanup crew.
To see whether and how cancer provides this protection, researchers at the Huazhong University of Science and Technology in China used advanced mouse models of Alzheimer’s disease. They transplanted three types of tumors (lung, colon and prostate cancer) into the mice and found that the amyloid plaques in their brains shrank significantly.

Metastatic Recurrence in Adolescent and Young Adult Cancer—Key Drivers of Early Mortality
Editorial: Metastatic recurrence nearly triples mortality risk in Breast Cancer among young adults and increases death risk in sarcoma and colorectal cancer—highlighting the need for earlier detection and novel treatments.
Survivors of adolescent and young adult cancer (aged 15 to 39 years at diagnosis) are a large and growing population at risk for early mortality, with death due to primary cancer recurrence/progression a large contributor to increased mortality among survivors.1-3 In JAMA Oncol ogy, using linked data between the California Cancer Registry, Kaiser Permanente Northern California, and the Department of Health Care Access and Information, Brunson and colleagues4 report on patterns of metastatic recurrence among adolescents and young adults with cancer and compare the risk of death between those with metastatic recurrence and those with metastatic disease at diagnosis. These data provide valuable insights into the burden of metastatic disease among adolescents and young adults with cancer and identify cancer types for which adolescents and young adults face high risk for metastatic recurrence and associated mortality. Findings largely parallel trends in metastatic recurrent disease incidence and mortality among populations with broader age ranges, with some notable exceptions.
In this analysis, Brunson and colleagues4 found that 9.2% of adolescents and young adults had metastatic disease at diagnosis and 9.5% had metastatic recurrence, with the incidence of metastatic recurrence differing by cancer type. These findings have important implications for prognosis, treatment planning, disease surveillance, and survivorship care. Despite a 5-year overall survival of 86% for cancer in adolescents and young adults, a critical unmet need remains for those who do not reach long-term survival.5 Future efforts should prioritize understanding biologic mechanisms driving metastasis, identifying novel therapeutic targets, improving monitoring of minimal residual disease, and addressing disparities in treatment access and adherence, particularly for cancers that present with metastatic disease or have a high risk for metastatic recurrence.
Notably, the 5-year cumulative incidence of metastatic recurrence was highest for adolescents and young adults with sarcoma and colorectal cancer, at 24.5% and 21.8%, respectively. Additionally, compared to having metastatic disease at diagnosis, metastatic recurrence was associated with approximately 1.5-fold increased risk for mortality among adolescents and young adults with sarcoma and colorectal cancer. Compared to other common cancer types for this age range that have seen improvements in 5-year survival across recent decades, improvements in sarcoma survival have been muted, particularly among older adolescents and young adults.5, 6 Findings from the current study demonstrate that, in addition to poor prognosis compared to other cancer types, adolescents and young adults with sarcoma face a high burden of metastatic disease at diagnosis and high incidence of metastatic recurrence associated with increased risk of mortality.
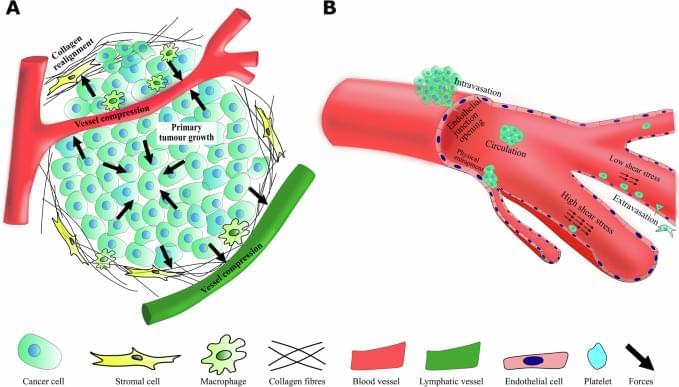
Mechanical signatures in cancer metastasis
npj Biological Physics and Mechanics volume 2, Article number: 3 (2025) Cite this article.
Elon Musk Holds Surprise Talk At The World Economic Forum In Davos
The musk blueprint: navigating the supersonic tsunami to hyperabundance when exponential curves multiply: understanding the triple acceleration.
On January 22, 2026, Elon Musk sat down with BlackRock CEO Larry Fink at the World Economic Forum in Davos and delivered what may be the most important articulation of humanity’s near-term trajectory since the invention of the internet.
Not because Musk said anything fundamentally new—his companies have been demonstrating this reality for years—but because he connected the dots in a way that makes the path to hyperabundance undeniable.
[Watch Elon Musk’s full WEF interview]
This is not visionary speculation.
This is engineering analysis from someone building the physical infrastructure of abundance in real-time.