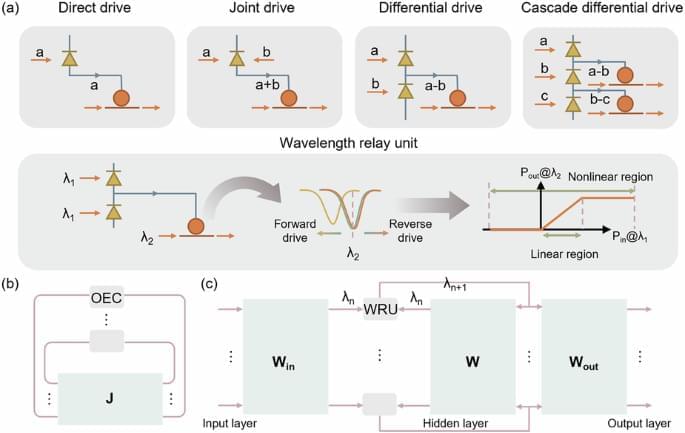
Artificial intelligence is now part of our daily lives, with the subsequent pressing need for larger, more complex models. However, the demand for ever-increasing power and computing capacity is rising faster than the performance traditional computers can provide.
To overcome these limitations, research is moving towards innovative technologies such as physical neural networks, analog circuits that directly exploit the laws of physics (properties of light beams, quantum phenomena) to process information. Their potential is at the heart of the study published in the journal Nature. It is the outcome of collaboration between several international institutes, including the Politecnico di Milano, the École Polytechnique Fédérale in Lausanne, Stanford University, the University of Cambridge, and the Max Planck Institute.
The article entitled “Training of Physical Neural Networks” discusses the steps of research on training physical neural networks, carried out with the collaboration of Francesco Morichetti, professor at DEIB—Department of Electronics, Information and Bioengineering, and head of the university’s Photonic Devices Lab.