{kind=link}
There’s trouble in AI paradise.
Category: robotics/AI – Page 90
{kind=link}
Brad Younggren | Therapeutic Plasma Exchange (TPE): A Tool Against Aging and Disease
Offering TPE. I do not see a cost though.
*Apply to join Foresight Biotech & Health Extension program:* https://foresight.org/biotech-health-extension-program/
A group of scientists, entrepreneurs, funders, and institutional allies who cooperate to advance biotechnology to reverse aging and extend human healthspan. This group is sponsored by 100 Plus Capital. http://100pluscap.com/
*Foresights Personal Longevity Group* Exploring anti-aging methods, monthly virtual meetings, expert discussions, private group for Foresight Patrons. https://foresight.org/personal-longevity-group/
*Brad Younggren | Therapeutic Plasma Exchange (TPE): A Tool Against Aging and Disease*
Bio: Brad Younggren, MD, is CEO and co-founder of Circulate Health, a company dedicated to extending human healthspan. A former U.S. Army physician, Dr. Younggren served as a combat physician in Iraq and was awarded a Bronze Star and Combat Medical Badge. An emergency medicine specialist and seasoned healthcare executive, Younggren has led teams at the cutting edge of medicine for decades. Most recently, he was President and Chief Medical Officer at 98point6, where he led the development and launch of AI-powered primary care solutions. He previously served as CMO at Cue Health, Shift Labs, and Mobisante. At Circulate, Younggren leads an expert team of clinicians and scientists working to harness the potential of therapeutic plasma exchange to advance health and longevity.
https://www.circulate.health/
Abstract: Aging is the primary risk factor for most chronic diseases, driving over 90% of U.S. healthcare expenditures. However, emerging science suggests that aging itself can be targeted as a modifiable process. Therapeutic Plasma Exchange (TPE) is a promising intervention that removes harmful substances from the bloodstream, reducing inflammation, disease burden, and potentially reversing aspects of biological aging. Circulate Health is pioneering this space, with clinical trial data demonstrating measurable reductions in biological age and improvements in key biomarkers. Beyond its longevity benefits, recent findings suggest TPE may help reduce microplastics and other environmental toxins—offering a practical, scalable approach to mitigating modern health threats. In this talk, we’ll explore the science behind TPE, its clinical applications, and why Circulate Health’s model makes this groundbreaking treatment accessible to more patients and clinics.

AlphaGenome: AI for better understanding the genome
Introducing a new, unifying DNA sequence model that advances regulatory variant-effect prediction and promises to shed new light on genome function — now available via API.
The genome is our cellular instruction manual. It’s the complete set of DNA which guides nearly every part of a living organism, from appearance and function to growth and reproduction. Small variations in a genome’s DNA sequence can alter an organism’s response to its environment or its susceptibility to disease. But deciphering how the genome’s instructions are read at the molecular level — and what happens when a small DNA variation occurs — is still one of biology’s greatest mysteries.
Today, we introduce AlphaGenome, a new artificial intelligence (AI) tool that more comprehensively and accurately predicts how single variants or mutations in human DNA sequences impact a wide range of biological processes regulating genes. This was enabled, among other factors, by technical advances allowing the model to process long DNA sequences and output high-resolution predictions.

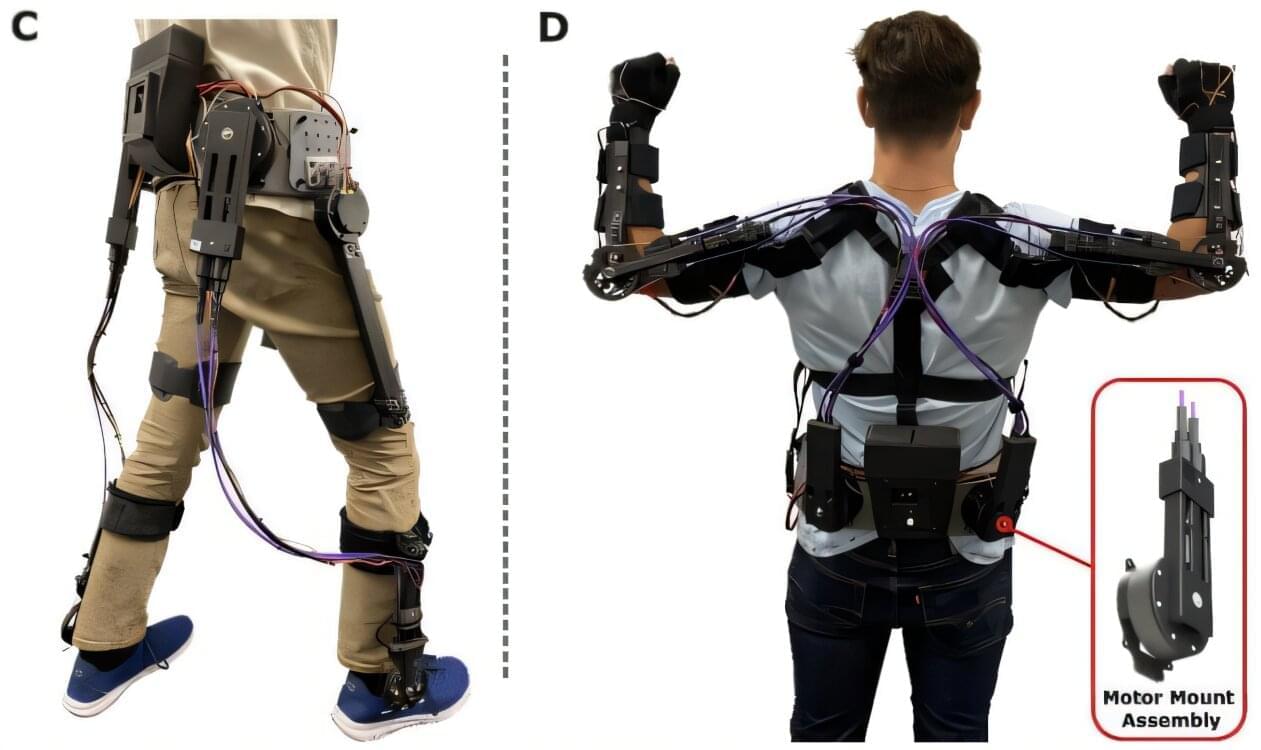
Researchers launch open-source robotic exoskeleton to help people walk
Imagine a future in which people with disabilities can walk on their own, thanks to robotic legs. A new project from Northern Arizona University is accelerating that future with an open-source robotic exoskeleton.
Right now, developing these complex electromechanical systems is expensive and time-consuming, which likely stops a lot of research before it ever starts. But that may soon change: Years of research from NAU associate professor Zach Lerner’s Biomechatronics Lab has led to the first comprehensive open-source exoskeleton framework, made freely available to anyone worldwide. It will help overcome several huge obstacles for potential exoskeleton developers and researchers.
An effective exoskeleton must be biomechanically beneficial to the person wearing it, which means that developing them requires extensive trial, error and adaptation to specific use cases.
Robots are transforming warehouse automation and ending back-breaking truck loading
{kind=link}
The last stronghold of human labor in warehouses – the grueling job of loading and unloading trucks – is rapidly giving way to a new generation of intelligent robots. For decades, logistics companies have struggled to automate this physically demanding and injury-prone work, which often leaves workers battered by heavy lifting and extreme temperatures. Now, breakthroughs in robotics, artificial intelligence, and sensor technology are transforming how goods move in and out of trailers, promising not only greater efficiency but also a fundamental shift in warehouse operations.
At the heart of this revolution is a suite of sophisticated machines from companies like Ambi Robotics, Boston Dynamics, Dexterity AI, and Fox Robotics. Each brings a distinct technical approach to the challenge, as described by The Wall Street Journal.
Ambi Robotics, for example, has developed AmbiStack, a robotic system designed to automate the complex process of stacking items onto pallets or into containers. AmbiStack employs a four-axis gantry robot equipped with advanced cameras and machine vision powered by AI foundation models. This system can analyze, track, and pick each item from a conveyor, performing real-time quality control checks.


“Robots Can Feel Now”: New Color-Changing Skins Let Machines React Instantly Without Wires, Screens, or Human Input
IN A NUTSHELL 🐙 Researchers at the University of Nebraska–Lincoln have developed synthetic skins that mimic the color-changing abilities of marine creatures. ⚙️ These innovative skins utilize autonomous materials that respond to environmental stimuli without the need for traditional electronics. 📱 Potential applications include wearable devices and soft robotics, offering flexibility and adaptability in various
