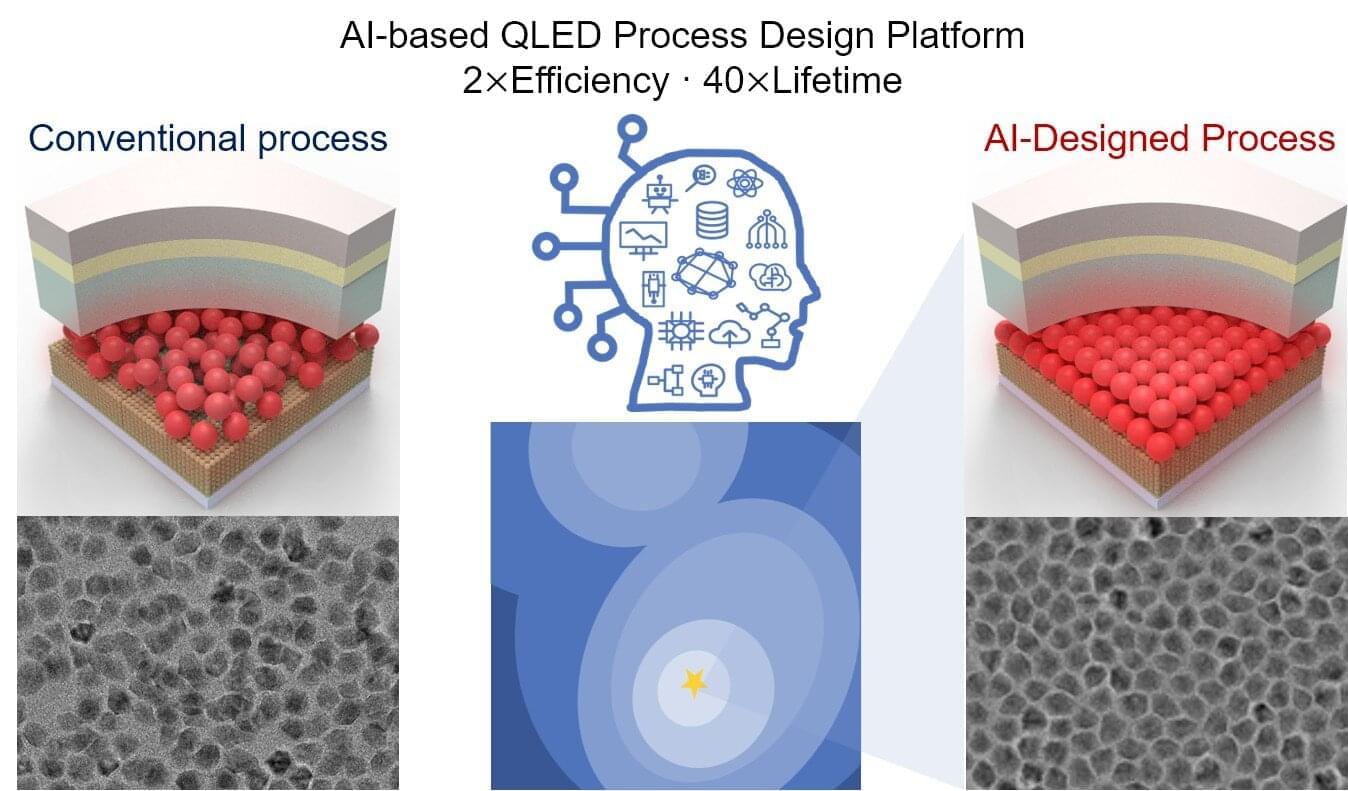
MIT engineers are building a chip reaching one petabit per second. See how this hardware processes data faster than any current consumer tech. This video examines the technical details behind the new MIT processor chip designed to push data limits. We explore how researchers are utilizing interferometer technology to achieve speeds of a thousand terabits on a surface thinner than a human hair. This breakdown is for engineers, students, and tech enthusiasts interested in the future of high-speed hardware. By analyzing the electronic components and the specific measurement diagrams, you will better understand the engineering hurdles involved in reaching a petabit per second. You will see how this data processing speed milestone compares to existing silicon-based architectures and why this specific design is capable of such massive throughput.
Subscribe for weekly engineering breakdowns, and comment below if you want to see a deep dive on how interferometers are used in modern computing.