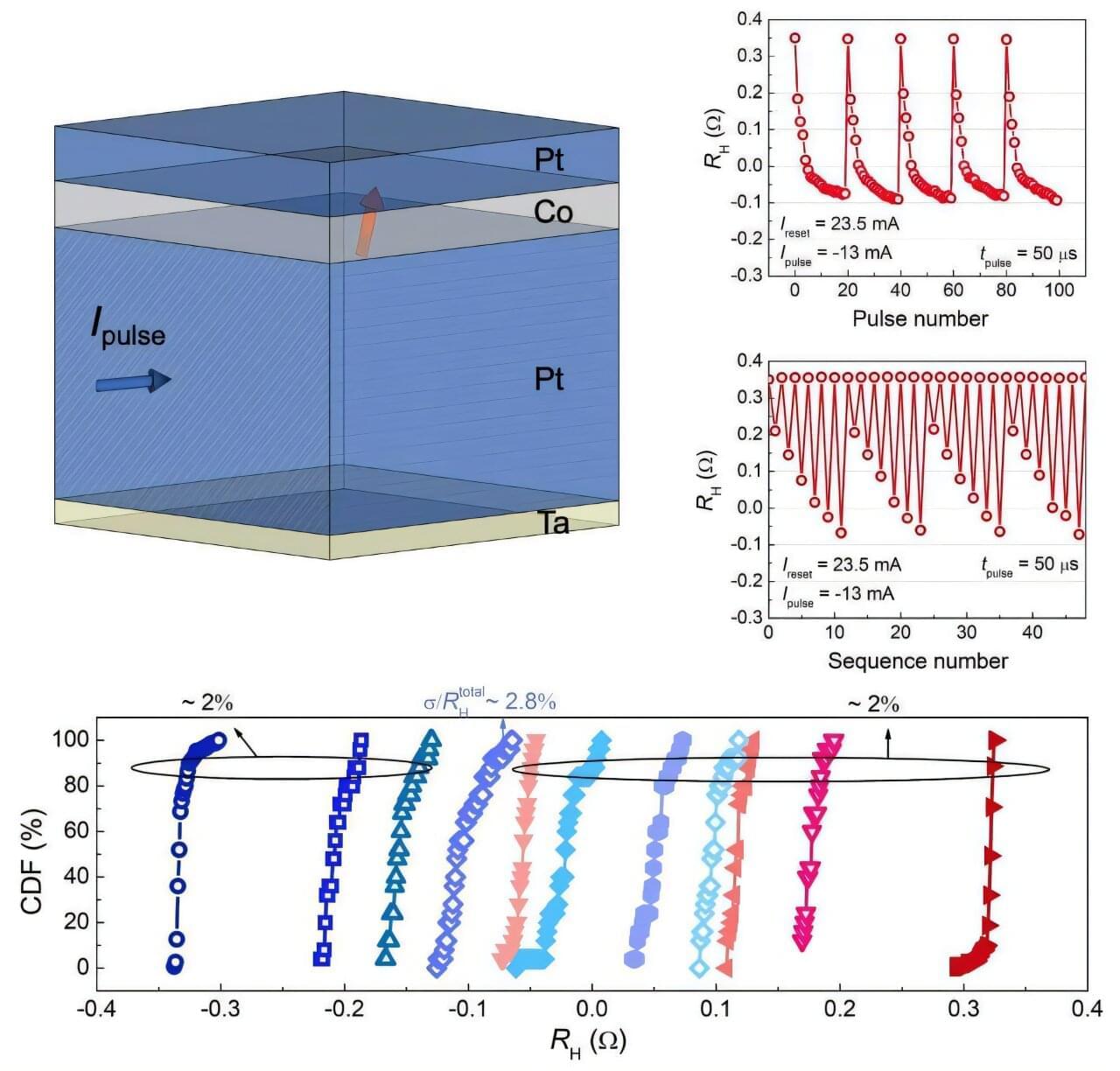
Researchers at National Taiwan University have developed a new type of spintronic device that mimics how synapses work in the brain—offering a path to more energy-efficient and accurate artificial intelligence systems.
In a study published in Advanced Science, the team introduced three novel memory device designs, all controlled purely by electric current and without any need for an external magnetic field.
Among the devices, the one based on “tilted anisotropy” stood out. This optimized structure was able to achieve 11 stable memory states with highly consistent switching behavior.
Ribonucleic acid, also called RNA, is a molecule present in all living cells. It plays a critical role in transmitting genetic instructions from DNA and creating proteins. With the power to execute a plethora of functions, the little RNA “messenger” has led to important innovations across therapeutics, diagnostics, and vaccines, and made us rethink our understanding of life itself.
A team of researchers from Boston University’s Biological Design Center and the Department of Biomedical Engineering recently made significant steps forward in the development of the next generation of computational RNA tools. They recently published a study in Nature Communications describing a generative AI technique for designing different types of RNA molecules with improved function.
Much like a large language model that can be used to compose entirely new texts, the model can compose new RNA sequences tailored for specific tasks in the cell or in a diagnostic assay. Their research has shown that it’s possible to predict and generate RNA sequences that have specific functions across a broad array of potential applications.
Scientists inspired by the octopus’s nervous system have developed a robot that can decide how to move or grip objects by sensing its environment.
The team from the University of Bristol’s Faculty of Science and Engineering designed a simple yet smart robot which uses fluid flows of air or water to coordinate suction and movement as octopuses do with hundreds of suckers and multiple arms.
The study, published in the journal Science Robotics, shows how a soft robot can use suction flow not just to stick to things, but also to sense its environment and control its own actions—just like an octopus.
I’ve been writing about this for the past decade, analysing AI and other exponential technologies and their impact on society. As you get started with Exponential View, I wanted to introduce you first to five charts — depicting key dynamics — to help you understand why the pace of change has increased.
Today’s supercomputers are enormously powerful, but the work they do − running AI and tackling difficult science − is pushing them to their limits. Building bigger supercomputers won’t be easy.
Imagine developing a finer control knob for artificial intelligence (AI) applications like Google Gemini and OpenAI ChatGPT.
Mikhail Belkin, a professor with UC San Diego’s Halıcıoğlu Data Science Institute (HDSI)—part of the School of Computing, Information and Data Sciences (SCIDS)—has been working with a team that has done just that. Specifically, the researchers have discovered a method that allows for more precise steering and modification of large language models (LLMs)—the powerful AI systems behind tools like Gemini and ChatGPT. Belkin said that this breakthrough could lead to safer, more reliable and more adaptable AI.
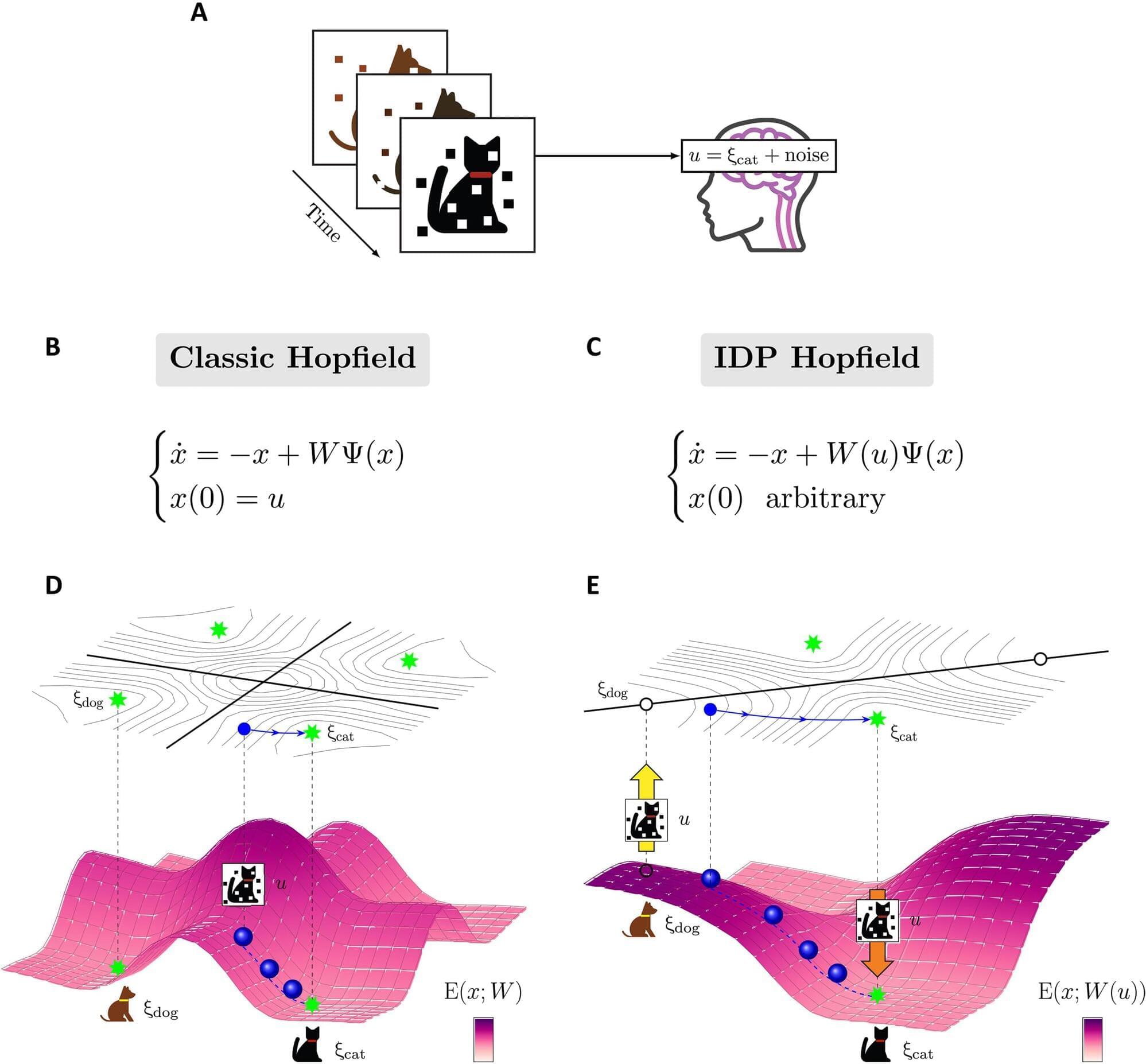
Listen to the first notes of an old, beloved song. Can you name that tune? If you can, congratulations—it’s a triumph of your associative memory, in which one piece of information (the first few notes) triggers the memory of the entire pattern (the song), without you actually having to hear the rest of the song again. We use this handy neural mechanism to learn, remember, solve problems and generally navigate our reality.
“It’s a network effect,” said UC Santa Barbara mechanical engineering professor Francesco Bullo, explaining that associative memories aren’t stored in single brain cells. “Memory storage and memory retrieval are dynamic processes that occur over entire networks of neurons.”
In 1982, physicist John Hopfield translated this theoretical neuroscience concept into the artificial intelligence realm, with the formulation of the Hopfield network. In doing so, not only did he provide a mathematical framework for understanding memory storage and retrieval in the human brain, he also developed one of the first recurrent artificial neural networks—the Hopfield network—known for its ability to retrieve complete patterns from noisy or incomplete inputs. Hopfield won the Nobel Prize for his work in 2024.