On the Lex Fridman podcast, NVIDIA’s CEO was asked about his mortality and whether he fears dying in his current state. Jensen offered a rather interesting response, saying that his company is currently in the midst of a technological revolution and that, if he died in the meantime, it might not be the best-case scenario for him.
“The most important thing you should do today, if you care about the future of your company, post you, is to pass on knowledge, information, insight, skills, experience as often and continuously as you can. Which is the reason why I continuously reason about everything in front of my team.”
NVIDIA has become the largest business entity and the driving force in the AI world, yet CEO Jensen Huang has no succession plans in sight.
Healable spacecraft structures could soon be possible thanks to cutting-edge composite technology. Swiss companies CompPair and CSEM with Belgian company Com&Sens have partnered with the European Space Agency (ESA) to modify their self-healing carbon fiber product for use in space transportation.
Project Cassandra (a loose abbreviation of Composite Autonomous SenSing AnD RepAir) includes sensors and a heating element into a composite carbon-fiber material, allowing spacecraft to autonomously repair initial stages of damage.
Cassandra is part of ESA’s Future Innovation Research in Space Transportation (FIRST!) Initiative which is finding and testing innovative technology that will benefit European space transportation.
Dr. Joscha Bach is a renowned cognitive scientist, AI researcher, and philosopher of mind known for his work on synthetic intelligence and the computational foundations of the soul. He is currently the founding director of the California Institute for Machine Consciousness (CIMC) and a strategic advisor at Liquid AI.
Throughout his career, Joscha has held research positions at some of the world’s most prestigious institutions, including the MIT Media Lab, the Harvard Program for Evolutionary Dynamics, and Intel Labs. He is the architect behind MicroPsi, a cognitive architecture that models how agents think, act, and feel based on internal motivations.
Are minds just processes? Can AI become conscious, morally wiser, or even part of a larger collective intelligence? Anders Sandberg and Joscha Bach discuss consciousness, AGI, hybrid minds, moral uncertainty, collective agency and the future of the cyborg Leviathan. It’s a deep and winding discussion with so many interesting topics covered!
0:00 Intro. 0:37 What is consciousness? Phenomenology — functionalism & panpsychism. 1:54 Causal boundaries — the mind is a causally organised process with a non-arbitrary functional boundary, sustained through time by feedback, control, and internal continuity. 3:20 Minds are not states — they are processes. We don’t see causal filtering in tables. 5:54 Epiphenomenalism is self-undermining if it has no causal role, and taking causation seriously pushes towards functionalism. 9:49 Methodological humility about armchair philosophy of mind. 12:41 Putnam-style Brain-in-a-vat — and why standard objections to AI minds fall flat. 16:37 Is sentience required (or desired) for not just moral competence in AI, but moral motivation as well? 22:35 Why stepping outside yourself is powerful — seeing. 25:12 Are AIs born enlightened? 26:25 Are LLMs AGI yet? What’s still missing. 28:16 AI, hybrid minds, and the limits of human augmentation. 32:32 Can minds be extended — in humans, dogs, and cats? 36:19 Why human language may not be open-ended enough. 39:41 Why AI is so data-hungry — and why better algorithms must exist. 43:39 Why better representations matter more than raw compute (grokking was surprising) 48:46 How babies build a world model from touch and perception. 51:05 What comes after copilots: agent teams, multimodality and new AI workflows. 55:32 Can AI help us discover new forms of taste and aesthetics. 59:49 Using AI to learn art history and invent a transhumanist aesthetic. 1:01:47 When AI helps everyone looks professional, what still counts as real skill? 1:03:56 What happens when the self starts to merge with AI 1:05:43 How AI changes the way we think and create. 1:08:10 What happens when AI starts shaping human relationships. 1:11:18 Why feeling in control can matter more than being right. 1:12:58 Why intelligence without wisdom is very dangerous. 1:17:45 AI via scaling statistical pattern matching vs symbolic (& causal) reasoning. Can LLMs learn causality or just correlation? 1:23:00 Will multimodal AI replace LLMs or use them as glue everywhere. 1:24:02 10 years to the singularity? 1:25:27 AI, coordination and the corruption problem. 1:29:47 Can AI become more moral than us (humans)? and if so, should it? 1:34:31 Why pluralism still leaves moral collisions unresolved. 1:34:31 Traversing the landscape of norms (value) 1:38:14 Can ethics work across nested levels of existence? (from the person-effecting-view to the matrioshka-effecting-view) 1:43:08 Moral realism, evolution & game-theoretic symmetries. 1:48:01 Is there a global optimum of moral coordination? Is that god? 1:55:12 Metaphors of the body-politic, the body of Christ, Omega Point theory, Leviathan. 1:59:36 Will superintelligences converge into a cosmic singleton?
Have any ideas about people to interview? Want to be notified about future events? Any comments about the STF series? Please fill out this form: https://docs.google.com/forms/d/1mr9P…
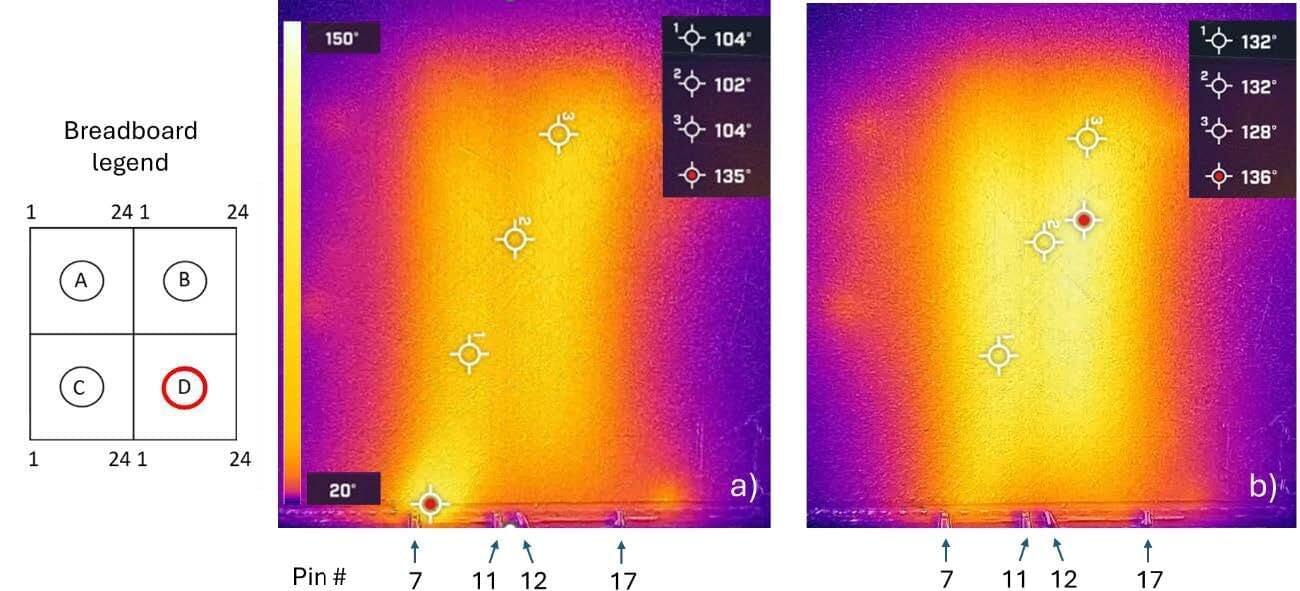
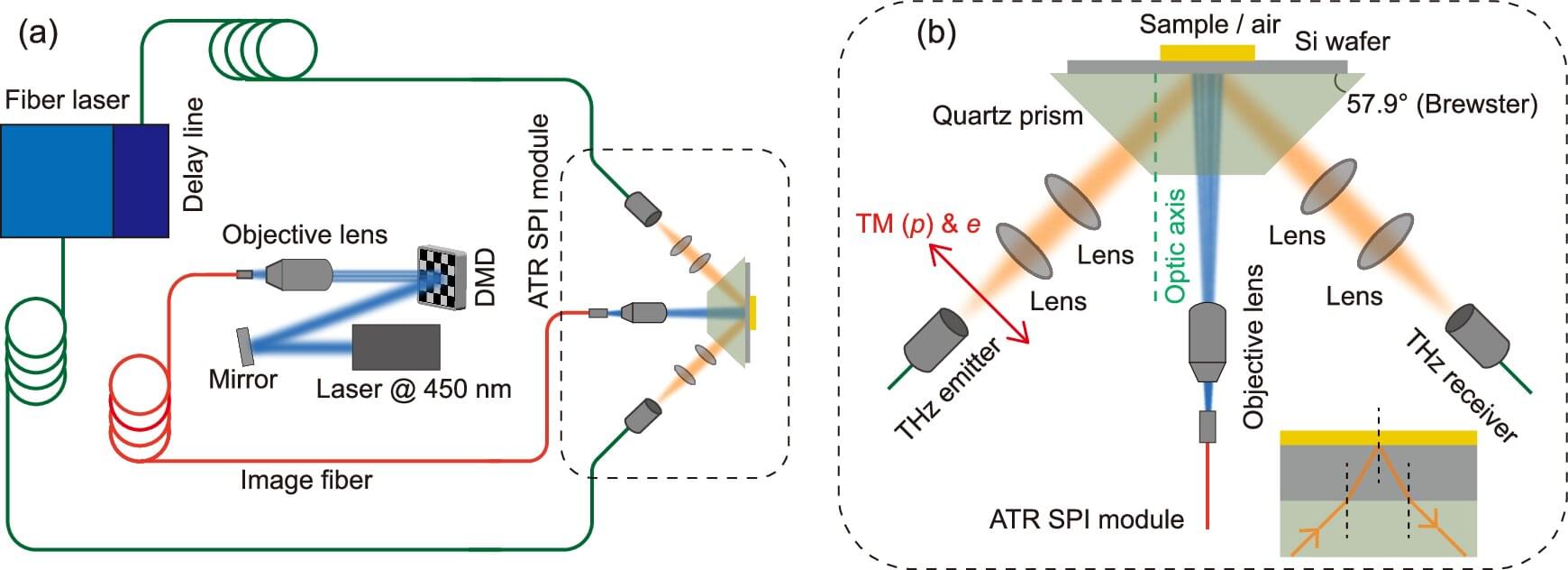
Scientists at the University of Warwick and University of Exeter have developed a fully fiber-coupled terahertz (THz) imaging system that significantly improves the speed, resolution, and clinical practicality of terahertz imaging. The study, published in Nature Communications, demonstrates a high-throughput, compact platform that overcomes key barriers limiting current THz systems—bringing real-time, non-invasive tissue imaging closer to routine clinical use.
“Terahertz imaging has shown immense promise for biomedical diagnostics, but its translation into real-world clinical tools has been hindered by bulky systems and slow acquisition speeds,” said Professor Emma MacPherson, Department of Physics, University of Warwick. “It’s an exciting breakthrough as the fiber coupling means that the system can be flexible and compact, meaning it can function as a handheld device or be integrated with a robot.”
Terahertz waves sit between microwaves and infrared light on the electromagnetic spectrum. Crucially, they are non-ionizing (meaning they do not carry the risks associated with X-rays) and are highly sensitive to water content, which helps reveal differences between healthy and diseased tissue. Despite this promise, most existing terahertz imaging systems are bulky and slow, limiting their use outside specialist labs.
Researchers have developed a brain-inspired nanoelectronic device that could significantly reduce the energy demands of artificial intelligence systems.
The DROID platform will extend current in vitro approaches—test tubes and culture dishes—to modeling learning and memory using brain organoids, addressing a critical gap: Current in vitro assays cannot capture higher-order neural responses, and evaluations of neurotoxicity or drug efficacy still primarily rely on animal behavioral tests.
The researchers will also evaluate brain organoids derived from both healthy individuals and patients with Alzheimer’s disease and individuals with SYNGAP1-related disorders—a rare pediatric condition associated with intellectual disability, seizures, and autism—to test neural responses and sensitivity to pharmacological interventions.
By enabling researchers to assess complex neural responses that currently rely on animal behavioral tests, the DROIDp system aims to improve drug discovery and neurotoxicity testing. Ultimately, the goal of this platform is to provide a more predictive, human-relevant approach for studying neurological diseases and evaluating the safety of drugs and chemicals.
“By implementing proactive cybersecurity now, we protect not only our systems and data but also the innovation, economic growth, and social stability made possible by developing technologies. The age of reactivity is over, and the age of anticipation has begun”
The consequences are obvious. We are already working in an AI-driven threat scenario, not getting ready for one. Organizations and countries that embrace proactive cybersecurity as a strategic necessity will be successful in this environment.
Those who demonstrate resilience, adaptability, and insight will reap the rewards in the future of AI. To maximize AI’s defensive potential while reducing its offensive risks, this changing ecosystem needs investments in workforce development, governance frameworks, predictive defenses, and cross-sector cooperation. Those that act with resilience, adaptability, and insight will be rewarded in the AI future.
An explainable AI system enables accurate, flow-aware grading of mitral and tricuspid regurgitation in routine echocardiography.
Mitral regurgitation and tricuspid regurgitation frequently coexist and are evaluated using overlapping echocardiographic views. Although artificial intelligence–based approaches have shown promise, current existing models lack explainability and physiologic constraints, limiting their reliability and adoption in real‐world echocardiographic workflows.