Having solved a central mystery about the “twirliness” of tornadoes and other types of vortices, William Irvine has set his sights on turbulence, the white whale of classical physics.
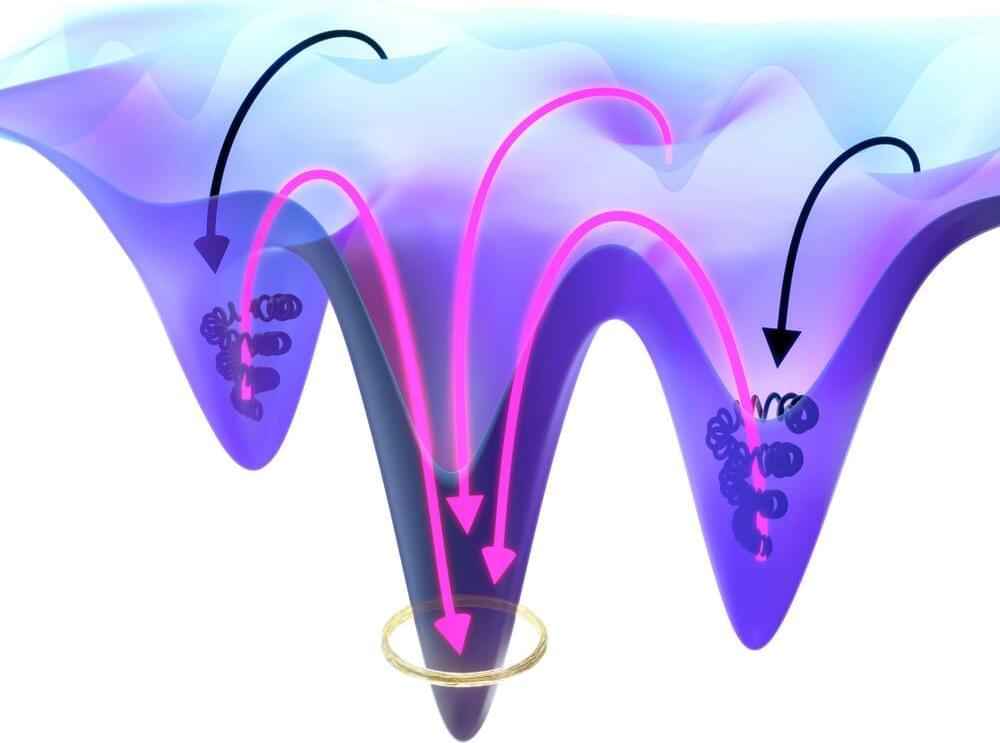
In a paper in Physical Review Letters scientists from the department Living Matter Physics at the Max Planck Institute for Dynamics and Self-Organization (MPI-DS) propose a mechanism on how energy barriers in complex systems can be overcome. These findings can help to engineer molecular machines and to understand the self-organization of active matter.

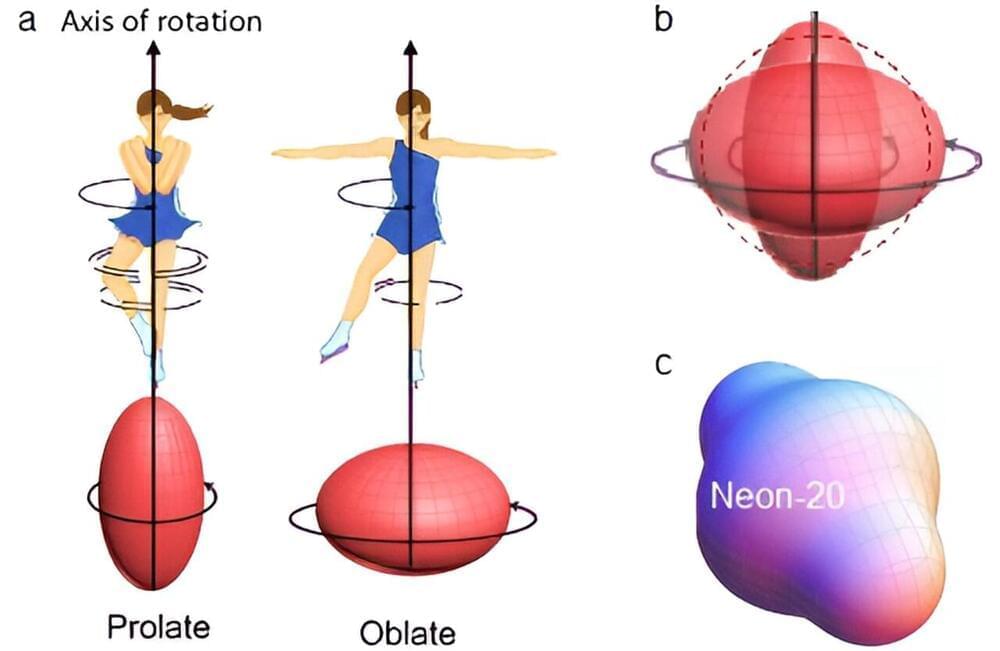
In previous research, measurements found that for fast rotations, for example in nuclei like neon-20 or chromium-48, the energy for spinning changes unexpectedly. Scientists attributed this to an anomalous increase in the moment of inertia for fast rotations, likely due to the nuclear matter bulging out. Earlier models suggested that fast-rotating nuclei ultimately become spheres, but newer models have found deformed shapes. Now, large-scale simulations of atomic nuclei have revealed surprising new explanations of the elusive physics of fast-spinning nuclei.
For the first time in nearly 50 years, scientists accurately calculated the moment of inertia and studied its hypothesized anomalous increase through state-of-the-art simulations of nuclei. The simulations for neon-20 replicate the energy measurements. Remarkably, however, the simulations do not find the anomalous increase. Instead, they reveal a change in the interior of the nucleus.
Similar microscopic simulations for chromium-48 confirm this surprising result. Furthermore, the results resolve the long-lasting question of whether a prolate nucleus that starts to quickly spin becomes spherical or oblate. This research, published in Physical Review C, shows that several competing shapes emerge, some prolate and some oblate, which on average appear spherical.

“Significant effort has been invested over the years to pinpoint the physical cause of the radiation drive-deficit problem,” Chen said. “We are excited about this discovery as it helps resolve a decade-long puzzle in ICF research. Our findings point the way to an improvement in the predictive capabilities of simulations, which is crucial for the success of future fusion experiments.”
In NIF experiments, scientists use a device called a hohlraum—approximately the size of a pencil eraser—to convert laser energy into X-rays, which then compress a fuel capsule to achieve fusion.
For years, there has been a problem where the predicted X-ray energy (drive) was higher than what was measured in experiments. This results in the time of peak neutron production, or “bangtime,” occurring roughly 400 picoseconds too early in simulations. This discrepancy is known as the “drive-deficit” because modelers had to artificially reduce the laser drive in the simulations to match observed bangtime.

Nick bostroms simulation argument.
Have you ever paused, looked around, and wondered if everything you see, feel, and experience is real? Or could it be that we’re living in a sophisticated simulation, indistinguishable from reality?
This thought isn’t just a plot from a sci-fi movie; it’s a serious philosophical argument proposed by Nick Bostrom, known as the Simulation Argument. If you’ve ever questioned the nature of reality or pondered over the mysteries of existence, this exploration is for you.
Nick Bostrom, a prominent figure in the realm of philosophical and technological inquiry, has significantly contributed to the discourse on existential risks and the future of humanity. With a background that spans physics, computational neuroscience, and philosophy, Bostrom has established himself as a leading thinker in assessing the implications of emerging technologies. His work, which often explores the intersection of life, consciousness, and artificial intelligence, has paved the way for a deeper understanding of the potential futures humanity might face.

What would it take to set Uranus ablaze? Is it even possible to burn it in the typical sense? If anyone can figure it out, it’s the Dead Planets Society.
Join Dead Planeteers Leah and Chelsea as they invite planetary scientist Paul Byrne back to the podcast, to join in more of their chaotic antics.
This mission is less about destruction (though it’s definitely also about destruction) and more about advancing science. Uranus is an ice giant, one of the most common types of planets in the universe, so burning it could teach us a lot about the cosmos. The planet may also be full of diamonds — and the potential for treasure derails the team’s destructive intentions.
Dead Planets Society is a podcast that takes outlandish ideas about how to tinker with the cosmos – from punching a hole in a planet to unifying the asteroid belt – and subjects them to the laws of physics to see how they fare.
Your hosts are Leah Crane and Chelsea Whyte.
If you have a cosmic object you’d like to figure out how to destroy, email the team at [email protected]. It may just feature in a later episode.