Machine learning algorithms play important roles in medical imaging analysis but can be affected by biases in training data. Jones and colleagues discuss how causal reasoning can be used to better understand and tackle algorithmic bias in medical imaging analysis.
The interior of black holes remains a conundrum for science. In 1916, German physicist Karl Schwarzschild outlined a solution to Albert Einstein’s equations of general relativity, in which the center of a black hole consists of a so-called singularity, a point at which space and time no longer exist. Here, the theory goes, all physical laws, including Einstein’s general theory of relativity, no longer apply; the principle of causality is suspended.
This constitutes a great nuisance for science—after all, it means that no information can escape from a black hole beyond the so-called event horizon. This could be a reason why Schwarzschild’s solution did not attract much attention outside the theoretical realm—that is, until the first candidate for a black hole was discovered in 1971, followed by the discovery of the black hole in the center of our Milky Way in the 2000s, and finally the first image of a black hole, captured by the Event Horizon Telescope Collaboration in 2019.
In 2001, Pawel Mazur and Emil Mottola proposed a different solution to Einstein’s field equations that led to objects that they called gravitational condensate stars, or gravastars. Contrary to black holes, gravastars have several advantages from a theoretical astrophysics perspective.
Tech giant Google has finally unveiled its much-hyped Gemini AI, a series of generative AI models it claims are its “largest and most capable” to date.
“This new era of models represents one of the biggest science and engineering efforts we’ve undertaken as a company,” said Google CEO Sundar Pichai.
Multimodal AI: Generative AIs are algorithms trained to create original content in response to user prompts. OpenAI’s first iteration of ChatGPT, for example, can understand and produce human-like text, while its DALL-E 2 system can generate images based on text prompts.
Researchers from NYU discovered that classical computers could keep up with or even surpass quantum computers in certain circumstances. Classical computers can get a boost in speed and accuracy by adopting a new innovative algorithmic method, which could mean that they still have a future in a world of quantum computers.
Many experts believe that quantum computing is the future, and that we are veering away from classical computing, primarily because classical computers are significantly slower and weaker than their quantum-based counterparts. However, turns out that quantum computers are delicate and prone to information loss, and even if information is preserved it is difficult to convert it to classical information necessary for practical computation.
Summary: Researchers developed an innovative AI tool, DeepGO-SE, that excels in predicting the functions of unknown proteins, marking a significant advance in bioinformatics. Leveraging large language models and logical entailment, this tool can deduce molecular functions even for proteins without existing database matches, offering a groundbreaking approach to understanding cellular mechanisms.
Its precision has placed DeepGO-SE among the top algorithms in an international function prediction competition, demonstrating its potential in drug discovery, metabolic pathway analysis, and beyond. The team aims to apply this tool to explore proteins in extreme environments, opening new doors for biotechnological advancements.
This timelapse of future technology begins with 2 Starships, launched to resupply the International Space Station. But how far into the future do you want to go?
Tesla Bots will be sent to work on the Moon, and A.I. chat bots will guide people into dreams that they can control (lucid dreams). And what happens when humanity forms a deeper understanding of dark energy, worm holes, and black holes. What type of new technologies could this advanced knowledge develop? Could SpaceX launch 100 Artificial Intelligence Starships, spread across our Solar System and beyond into Interstellar space, working together to form a cosmic internet, creating the Encyclopedia of the Galaxy. Could Einstein’s equations lead to technologies in teleportation, and laboratory grown black holes.
Other topics covered in this sci-fi documentary video include: the building of super projects made possible by advancing fusion energy, the possibilities of brain chips, new age space technology and spacecraft such as a hover bike developed for the Moon in 2050, Mars colonization, and technology predictions based on black holes, biotechnology, and when will humanity become a Kardashev Type 1, and then Type 2 Civilization.
To see more of Venture City and to access the ‘The Future Archive Files’…
• Timelapse of Future Technology (Master List) • Encyclopedia of the Future (Entries)
Developed by Google DeepMind, a new algorithm, AlphaGeometry, can crush problems from past International Mathematical Olympiads—a top-level competition for high schoolers—and matches the performance of previous gold medalists.
When challenged with 30 difficult geometry problems, the AI successfully solved 25 within the standard allotted time, beating previous state-of-the-art algorithms by 15 answers.
Researchers based at the Drexel University College of Engineering have devised a new method for performing structural safety inspections using autonomous robots aided by machine learning technology.
The article they published recently in the Elsevier journal Automation in Construction presented the potential for a new multi-scale monitoring system informed by deep-learning algorithms that work to find cracks and other damage to buildings before using LiDAR to produce three-dimensional images for inspectors to aid in their documentation.
The development could potentially work to benefit the enormous task of maintaining the health of structures that are increasingly being reused or restored in cities large and small across the country. Despite the relative age of America’s built environment, roughly two-thirds of today’s existing buildings will be in use in the year 2050, according to Gensler’s predictions.
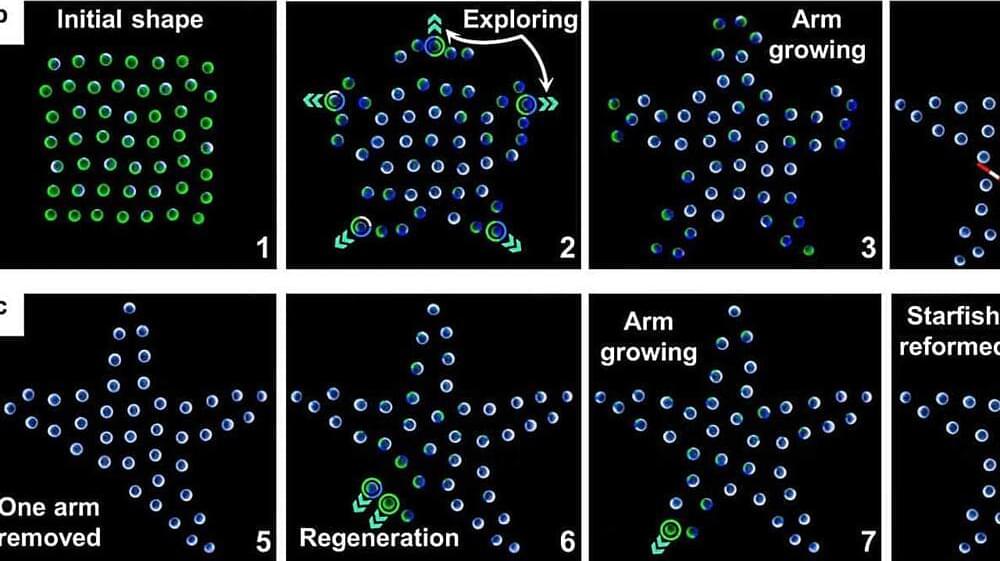
Researchers have proposed a new strategy for the shape assembly of robot swarms based on the idea of mean-shift exploration: When a robot is surrounded by neighboring robots and unoccupied locations, it actively gives up its current location by exploring the highest density of nearby unoccupied locations in the desired shape.
This idea is realized by adapting the mean-shift algorithm, an optimization technique widely used in machine learning for locating the maxima of a density function.
The automotive industry has experienced rapid advancements due to the integration of edge computing and artificial intelligence (AI) in recent years. As vehicles continue developing self-driving capabilities, these technologies have become increasingly critical for effective decision-making and real-time reactions.
Edge computing processes data and commands locally within a vehicle’s systems, improving road safety and transportation efficiency. Combined with 5G, it enables real-time communication between vehicles and infrastructure, reducing latency and allowing autonomous vehicles to respond faster. AI algorithms enable cars to interpret visual data and make human-like driving decisions.
Edge computing and AI are transforming vehicles into true self-driving machines, filling any gaps in low-latency 5G tech and enabling companies to pioneer advanced autonomy.


 עברית (Hebrew)
עברית (Hebrew)