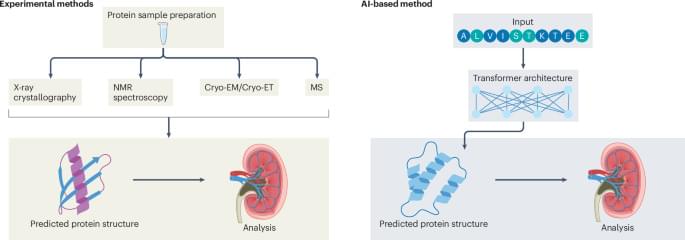
Advances in artificial intelligence-driven algorithms and experimental technologies have revolutionized the field of protein modelling. This Review describes how these developments have provided unprecedented insights into the structure of key proteins within the kidney, improved understanding of the relationships between protein structure and stability, and enabled mechanistic interpretation of variants that underlie a variety of kidney pathologies.
When you throw a ball in the air, the equations of classical physics will tell you exactly what path the ball will take as it falls, and when and where it will land. But if you were to squeeze that same ball down to the size of an atom or smaller, it would behave in ways beyond anything that classical physics can predict.
Or so we’ve thought.
MIT scientists have now shown that certain mathematical ideas from everyday classical physics can be used to describe the often weird and nonintuitive behavior that occurs at the quantum, subatomic scale.
The fundamental quantum postulates on the existence of a wave function, its propagation with the Schrödinger equation in theorem 3.2 and the wave collapse at a measurement in lemma 3.3 are derived from the classical theorem 2.4. Furthermore, analytic computations of the classical action are simpler than solving the Feynman path integral and potentially easier than solving the Schrödinger equation directly. In addition, theorem 3.2 is a multi-particle result.
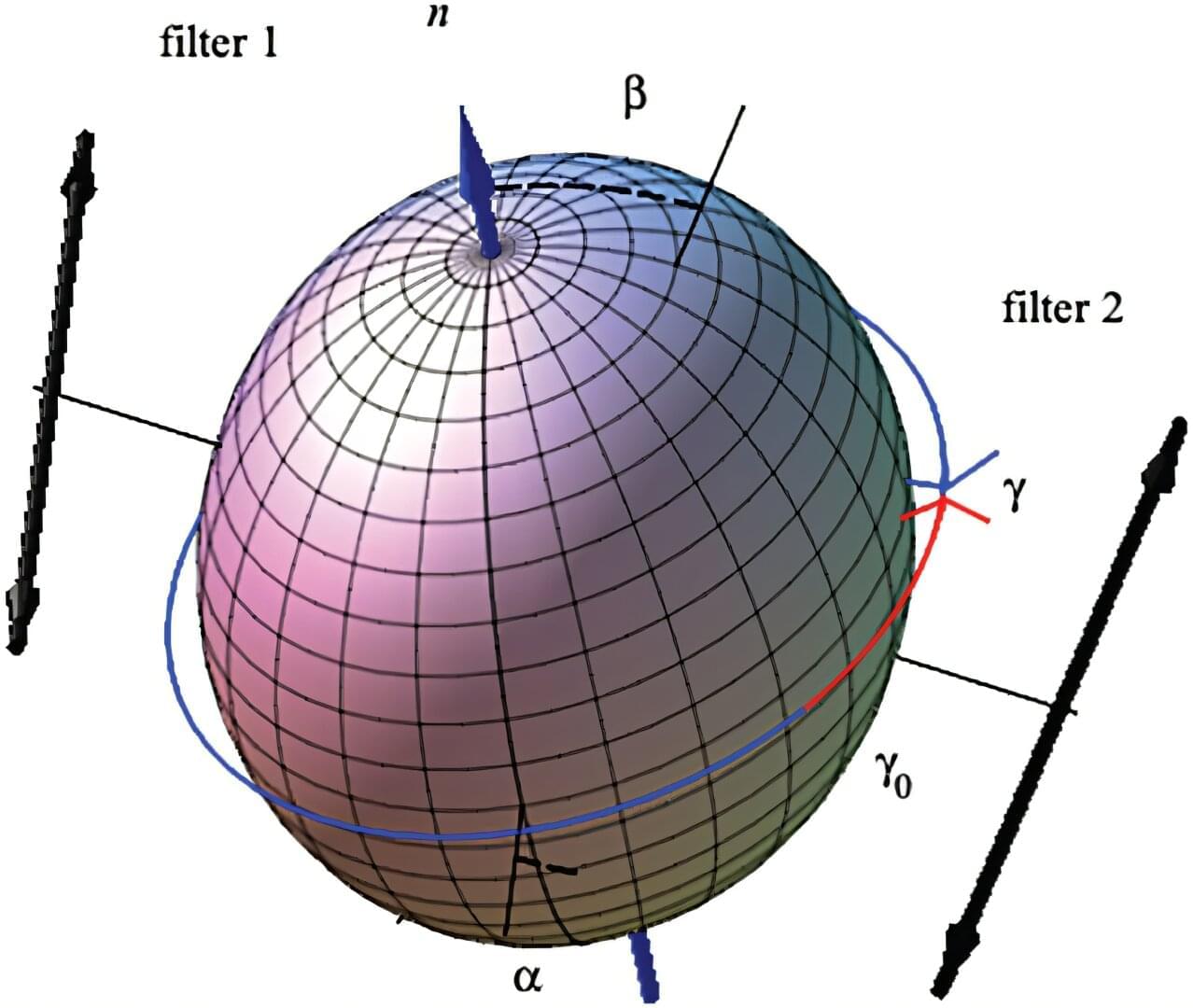
The J classical multipaths in theorem 3.2 and lemma 3.3 are strictly determined by the initial and final conditions. In the double slit experiment, the probabilistic quantum observation results from the non-Lipschitz constraint force in the slit. For the harmonic oscillator, the Coulomb wave, the particle in the box, or the spinning particle, the initial probabilistic density distribution is classically propagated forward in time. In the EPR experiment [64,65], theorem 2.4 determines a constant angular momentum χo↑,χo↓ over time, and lemma 3.3 in turn allows a classical interpretation that the decision which spin correlation is sensed behind the filters is already taken when the particles separate.
Support the Research Behind this Channel on Patreon: / arvinash.
REFERENCES How black holes may be responsible for Dark Energy • How BLACK HOLES May be Responsible for DAR… Is Dark Energy made of particles? • Is Dark ENERGY made of PARTICLES? The Quin… What is Dark Energy made of? • What is Dark Energy made of? Quintessence?… CHAPTERS 0:00 The 70% mystery 0:58 How Dark Energy was discovered? 4:26 What could be causing Dark Energy? 6:58 Repulsive Gravity? 10:16 What is the energy made of? 11:56 Evolving Dark energy? Quintesssence 14:18 Could Dark Energy be a particle? 16:43 Could Black Holes cause Dark Energy? SUMMARY Dark energy is one of the greatest mysteries in modern physics. It appears to make up nearly 70% of the universe, yet scientists still do not know what it is. Unlike matter, it does not clump together. Unlike radiation, it does not dilute as space expands. Instead, it causes the expansion of the universe to accelerate, pushing galaxies apart faster over time. The discovery of this acceleration came in the late 1990s when astronomers measured distant Type Ia supernovae, which act as reliable “standard candles.” By comparing their brightness and redshift, researchers could determine how fast the universe expanded at different points in cosmic history. Instead of finding that gravity slowed expansion—as expected—they discovered the opposite: the universe was expanding faster and faster. This unexpected result led to the concept of dark energy, the unknown driver behind cosmic acceleration. One possible explanation is that dark energy is a cosmological constant, represented by the Greek letter lambda in Einstein’s equations. In this model, empty space itself contains a constant energy density known as vacuum energy. Quantum mechanics predicts that empty space is not truly empty; quantum fields constantly fluctuate, producing short-lived “virtual particles.” These fluctuations create energy even in a vacuum. Experiments like the Casimir effect provide evidence that vacuum energy is real. However, this explanation has a major problem. When physicists calculate vacuum energy using quantum theory, the predicted value is about 10¹²⁰ times larger than what observations of the universe allow. This enormous mismatch is widely considered the worst prediction in physics. In general relativity, cosmic acceleration can occur if the universe contains energy with negative pressure. In the Friedmann equation, expansion accelerates when pressure is sufficiently negative relative to energy density. Dark energy appears to have exactly this property, effectively producing a form of repulsive gravity that stretches spacetime. Another possibility is that dark energy is not constant but comes from a dynamic field known as quintessence. In quantum theory, fields can have particle-like excitations, meaning dark energy might correspond to extremely weakly interacting particles. If the strength of this field changes over time, the acceleration of the universe could grow stronger. In extreme scenarios, this could eventually lead to a catastrophic future known as the Big Rip, where galaxies, stars, atoms, and even spacetime itself are torn apart. A more speculative idea suggests a connection between supermassive black holes and dark energy. Some recent studies have observed that black holes appear to grow more massive over billions of years than expected from normal matter accretion alone. Researchers have proposed that black holes might somehow be linked to dark energy, though current evidence only shows a correlation and not a confirmed causal explanation. #darkenergy For now, dark energy remains an observed phenomenon with multiple possible explanations. Whether it is a property of empty space, a new field of physics, or something even deeper, it stands as one of the most profound open questions in cosmology.
CHAPTERS 0:00 The 70% mystery 0:58 How Dark Energy was discovered? 4:26 What could be causing Dark Energy? 6:58 Repulsive Gravity? 10:16 What is the energy made of? 11:56 Evolving Dark energy? Quintesssence 14:18 Could Dark Energy be a particle? 16:43 Could Black Holes cause Dark Energy?
SUMMARY Dark energy is one of the greatest mysteries in modern physics. It appears to make up nearly 70% of the universe, yet scientists still do not know what it is. Unlike matter, it does not clump together. Unlike radiation, it does not dilute as space expands. Instead, it causes the expansion of the universe to accelerate, pushing galaxies apart faster over time.
The discovery of this acceleration came in the late 1990s when astronomers measured distant Type Ia supernovae, which act as reliable “standard candles.” By comparing their brightness and redshift, researchers could determine how fast the universe expanded at different points in cosmic history. Instead of finding that gravity slowed expansion—as expected—they discovered the opposite: the universe was expanding faster and faster. This unexpected result led to the concept of dark energy, the unknown driver behind cosmic acceleration.
One possible explanation is that dark energy is a cosmological constant, represented by the Greek letter lambda in Einstein’s equations. In this model, empty space itself contains a constant energy density known as vacuum energy. Quantum mechanics predicts that empty space is not truly empty; quantum fields constantly fluctuate, producing short-lived “virtual particles.” These fluctuations create energy even in a vacuum. Experiments like the Casimir effect provide evidence that vacuum energy is real.
When you throw a ball in the air, the equations of classical physics will tell you exactly what path the ball will take as it falls, and when and where it will land. But if you were to squeeze that same ball down to the size of an atom or smaller, it would behave in ways beyond anything that classical physics can predict.
Or so we’ve thought.
MIT scientists have now shown that certain mathematical ideas from everyday classical physics can be used to describe the often weird and nonintuitive behavior that occurs at the quantum, subatomic scale.
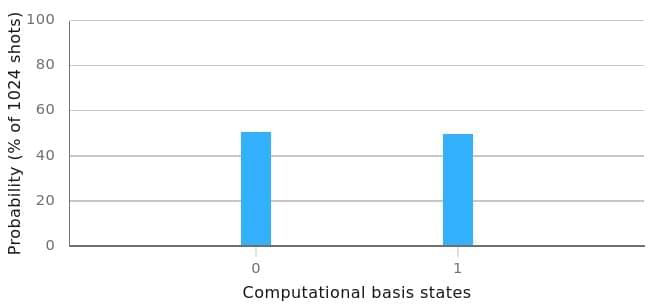
Let’s say you have a probabilistic computer with a single bit of memory. Some algorithms on the computer will stochastically flip the single bit of memory such that its new value will be uniformly distributed with a 50% chance of being 0 and a 50% chance of being 1. Other programs will place it into a degenerate distribution, meaning it either has 100% chance of being 0 every time you run the program, or other programs will produce 1 100% of the time.
A magician tells you to run one of the programs in one of the two categories of your choosing and then copy the computer’s memory state onto a thumb drive and hand it to him. You pick one, run the program, copy the bit of the memory to your thumb drive, then hand it to the magician. The magician then does something with the thumb drive you cannot see, then looks up at you and tell you exactly what category the program you ran to produce that bit came from.
Curious, you repeat this many times over: you run a program from one of the two categories (degenerate or uniform), copy the bit value produced from the algorithm, and then hand the thumb drive to the magician. Each and every time he always correctly guesses which category of program was ran to produce it.
The past and future are the same thing | feynman on time symmetry.
Discover one of physics’ most mind-bending secrets: the fundamental laws of nature don’t know which way time flows! In this exploration of Feynman’s ideas on time symmetry, we dive deep into how the equations of physics work equally well forwards and backwards, why positrons are electrons moving backward through time, and how the Wheeler-Feynman absorber theory suggests the future might influence the past.
From billiard balls to quantum mechanics, from Maxwell’s equations to the mystery of why we remember yesterday but not tomorrow, this video unravels the beautiful symmetry hidden beneath our everyday experience of time.
Topics Covered: • Time symmetry in fundamental physics • Positrons as electrons traveling backward in time • Wheeler-Feynman absorber theory • The thermodynamic arrow of time • Path integral formulation and quantum mechanics • Why time appears to flow in one direction • CP violation and the weak nuclear force.
Perfect for physics enthusiasts, students, and anyone curious about the nature of time and reality.
⚠️ DISCLAIMER: This is AI-generated content created in the style of Richard Feynman’s teaching approach. The script synthesizes information from various sources about Feynman’s work and ideas in theoretical physics, including his lectures, published papers, and documented contributions to quantum electrodynamics and time-symmetric theories. While based on authentic concepts from Feynman’s career, this is an educational interpretation and not actual recorded material from Richard Feynman.
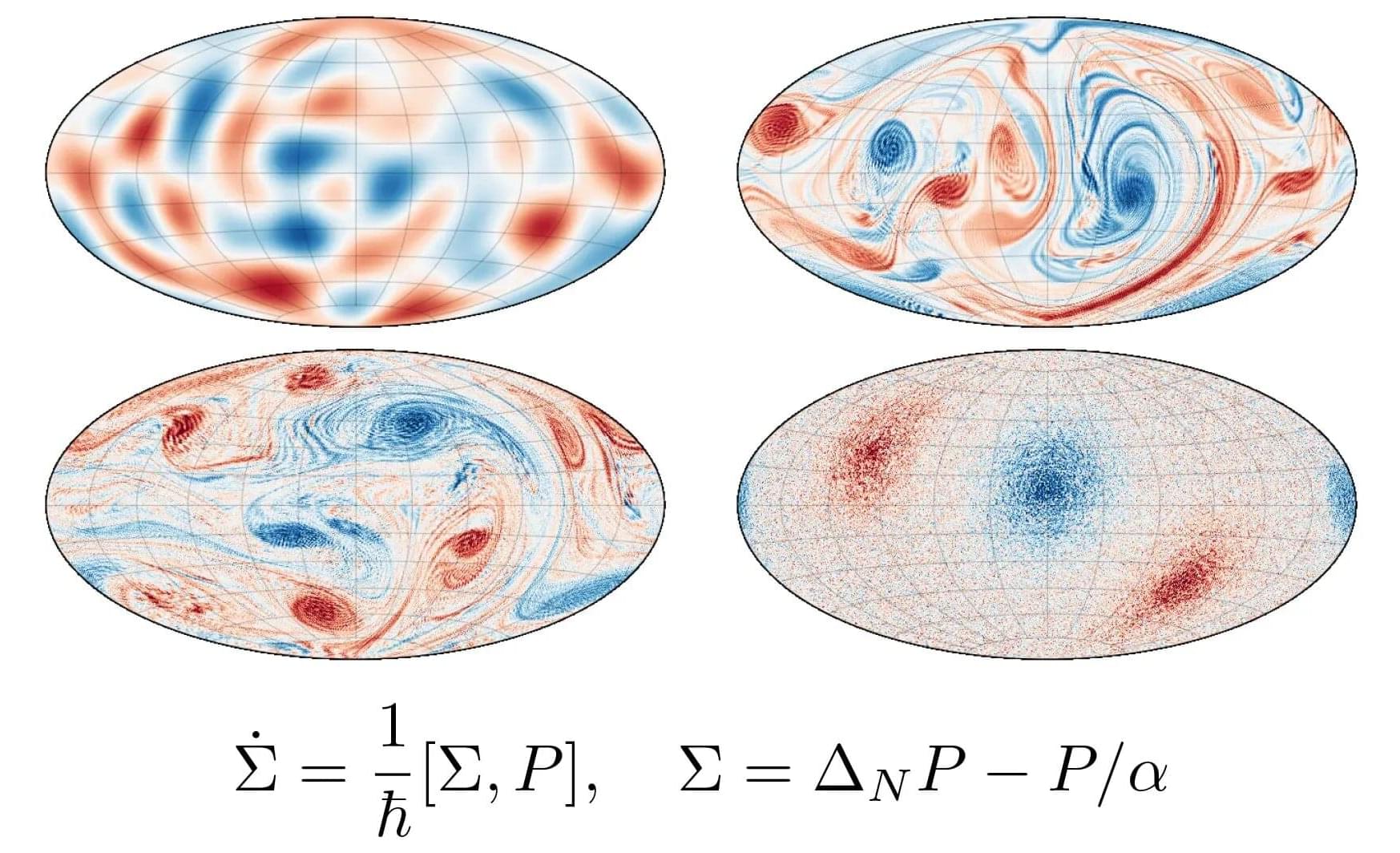
In his doctoral thesis, Michael Roop develops numerical methods that allow finding physically reliable approximate solutions to nonlinear differential equations used to model turbulence.
Many processes in nature can be described by differential equations, but only a few of them can be solved explicitly with solutions in formulas. This is the motivation for developing numerical equations to find approximate solutions. The numerical equations developed in Roop’s thesis have a particular focus on geometric properties. Though the thesis is mathematical, the problems it addresses originate in physics and mainly have to do with magnetohydrodynamic (MHD) turbulence.
“It is difficult to define turbulence rigorously. Intuitively, you can think of the turbulent behavior when a fluid moves, but it is very hard to predict how it will behave in the future. It looks chaotic though there is no randomness in the models of motion.”
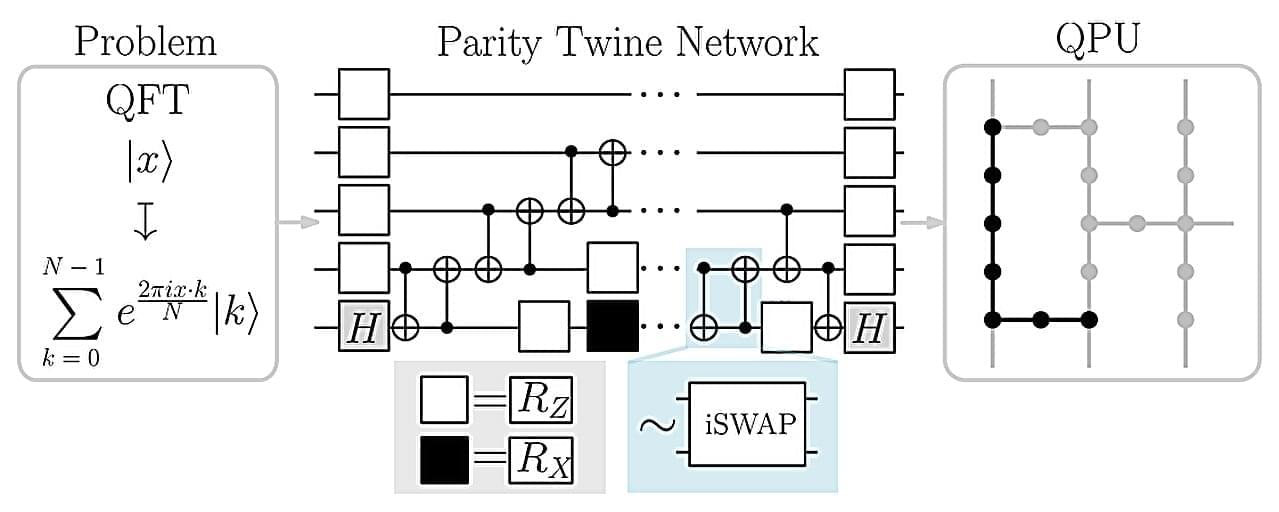
The spin-off company ParityQC has implemented the largest quantum Fourier transform ever reported using an IBM quantum computer, thereby setting a new milestone on the path toward the industrial application of quantum computers. The quantum Fourier transform is a cornerstone algorithm with applications in cryptography, financial modeling, and materials science.
Innsbruck-based quantum architecture company ParityQC performed a quantum Fourier transform using 52 superconducting qubits on an IBM Heron quantum processor. This surpasses the previous record of 27 qubits, which was set two years ago using an ion-trap quantum computer. The results were published this week on the arXiv preprint server.
“This milestone was only possible through the synergy of IBM’s latest quantum hardware and the ParityQC Architecture, which unlocked an exponential improvement in efficiency,” say Wolfgang Lechner and Magdalena Hauser, Co-CEOs of ParityQC. “What we are witnessing is European quantum innovation taking a global lead in translating theoretical potential into real-world performance.”


{kind=link}