It plans to employ more than 100 people there.







A research team has successfully developed a new technology that converts the conductivity properties of semiconductors with just one laser process.
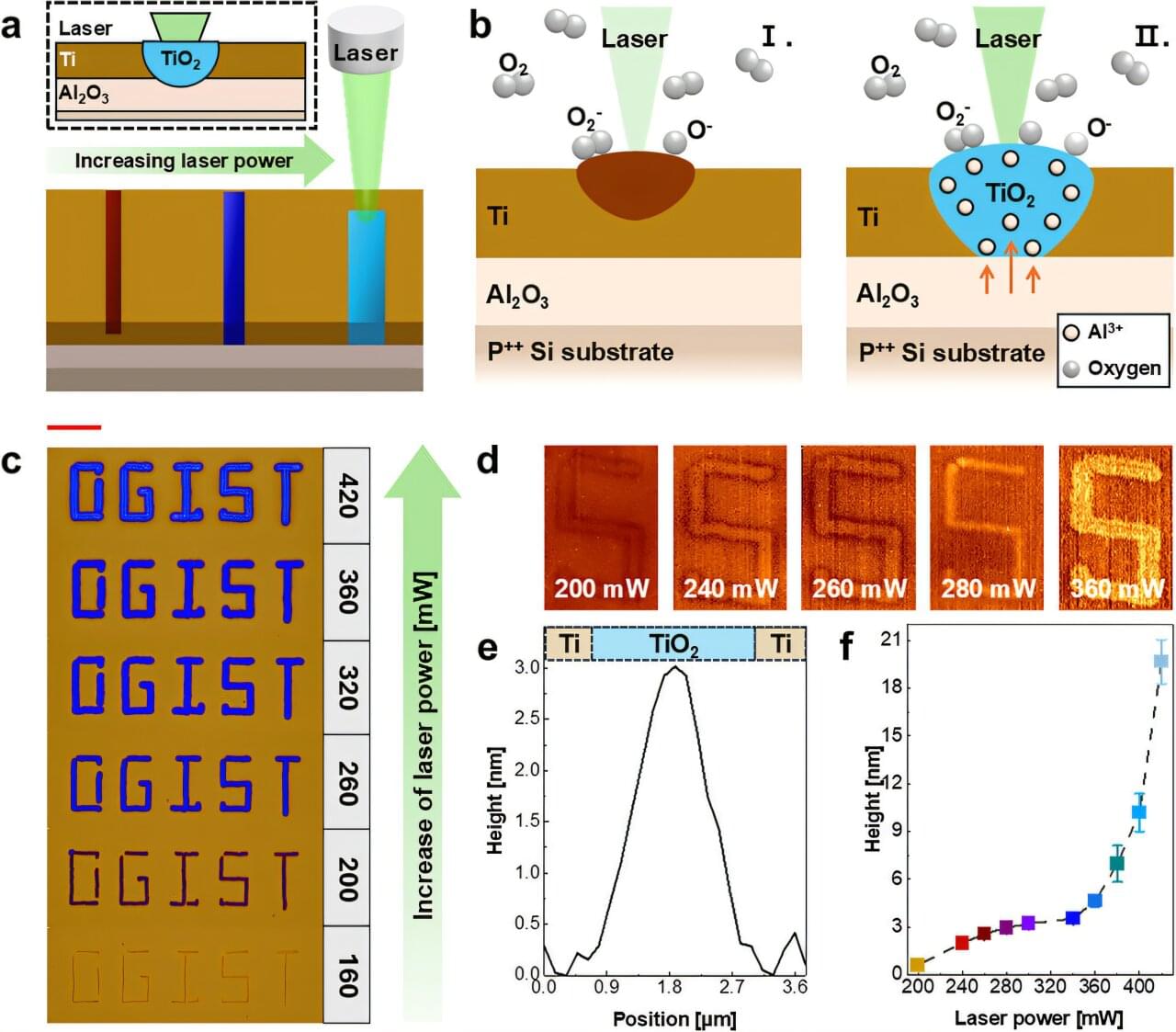
The research team successfully converted titanium oxide (TiO2), which conventionally works based on electrons, into a hole-based p-type semiconductor. The Laser-Induced Oxidation and Doping Integration (LODI) technology developed by the research team can simultaneously execute oxidation and doping with just one laser irradiation, and it is noted as a novel conversion technology that can drastically streamline the traditional complex process.
The study is published in the journal Small. The team was led by Professor Hyukjun Kwon from the Department of Electrical Engineering and Computer Science, Daegu Gyeongbuk Institute of Science and Technology.
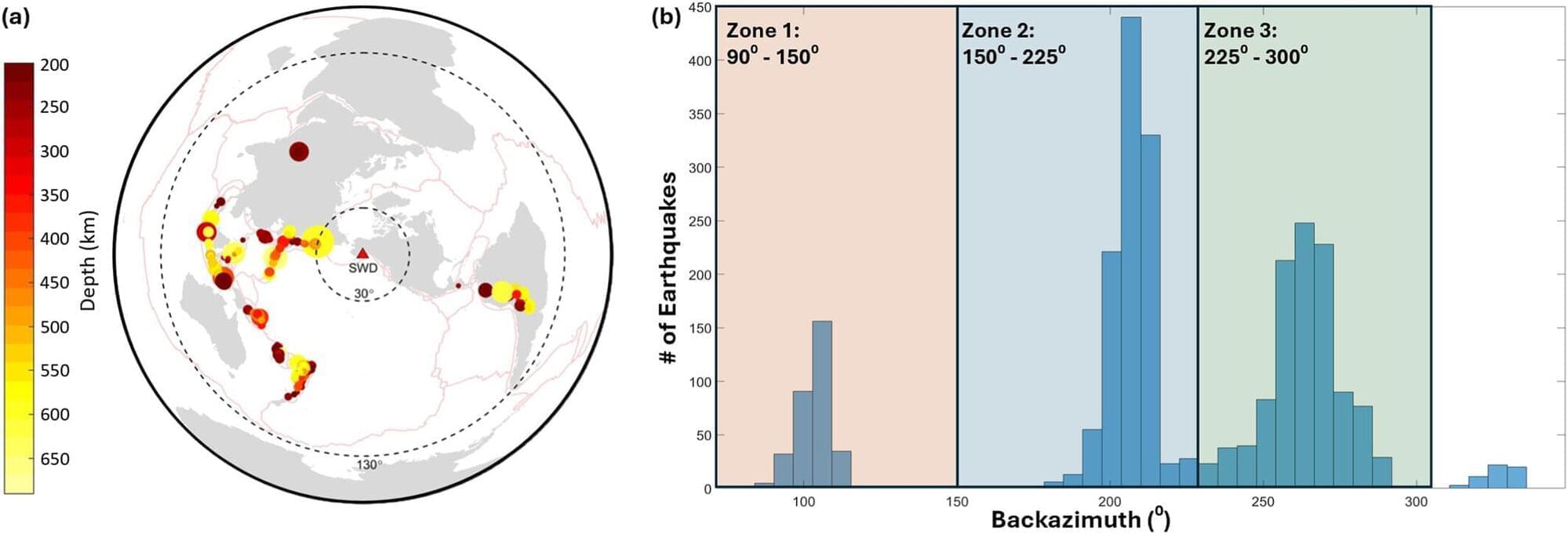
When a slab slides beneath an overriding plate in a subduction zone, the slab takes on a property called anisotropy, meaning its strength is not the same in all directions. Anisotropy is what causes a wooden board to break more easily along the grain than in other directions. In rock, the alignment of minerals such as clay, serpentine, and olivine can lead to anisotropy. Pockets of water in rock can also cause and enhance anisotropy, as repeated dehydration and rehydration commonly occur at depth in a subducting slab.
It is well known that an earthquake generates both a compressional wave and a shear wave. If the shear wave passes through anisotropic rock, it can split into a faster shear wave and a slower one with different polarizations.
Although seismologists routinely measure the shear wave splitting in subduction zones by analyzing recorded seismic waveform data, it is challenging to pinpoint where splitting occurs along the wave propagation path.

{kind=link}