CISA warns of VMware zero-day exploited by China-linked hackers before Broadcom patch.



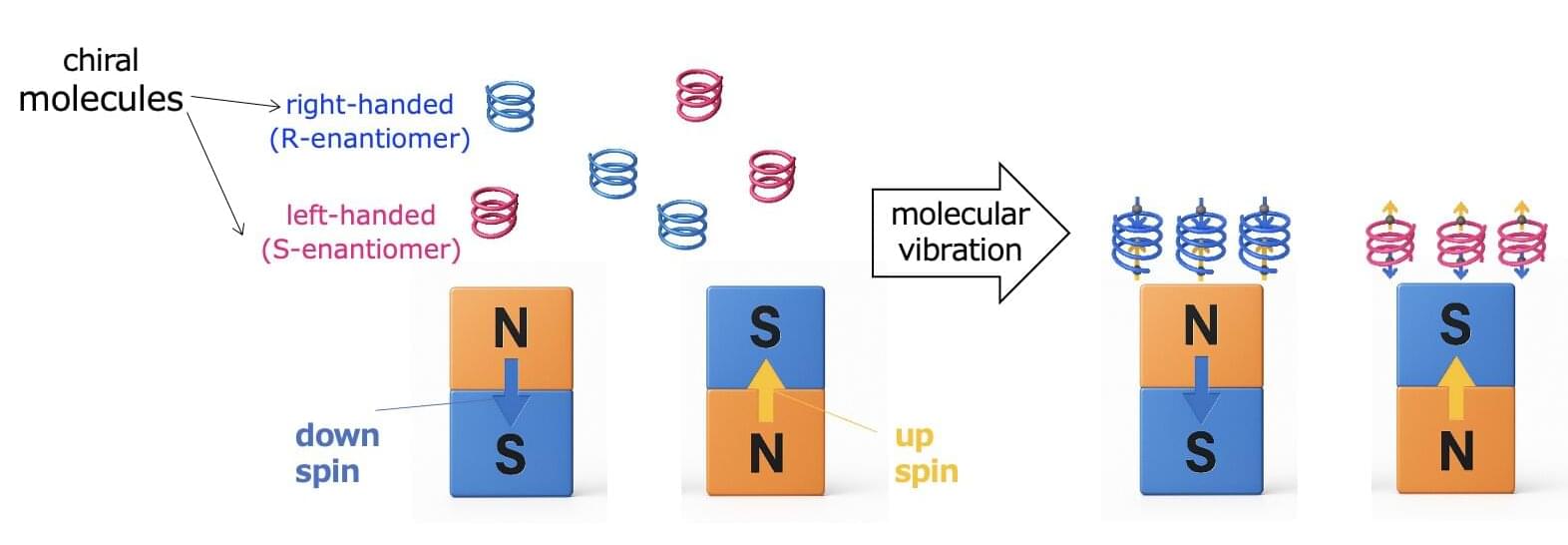
A research group at The University of Tokyo has discovered a new principle by which helical chiral molecules acquire spin through molecular vibrations, enabling them to adhere to magnets. Until now, it was believed that chiral molecules could only exhibit magnetic properties when an electric current was applied. This discovery overturns that conventional understanding.
Chiral molecules, which have a helical structure, are known to interact with magnets in a phenomenon known as chirality-induced spin selectivity (CISS). For instance, when a chiral molecule is connected to a magnet and an electric current is applied, magnetoresistance effects can be observed. It has also been reported that magnets can be used to separate right-handed and left-handed chiral molecules.
The prevailing explanation is that the flow of current through a chiral molecule induces magnetic properties, similar to an electromagnet. However, this explanation has limitations, as it does not fully account for the large magnetoresistance effects or CISS phenomena observed even in the absence of an electric current.


“don’t try to read the glyphs”. Yes, Gemini is pretty dyslexic. Grok Imagine is a little better but I often have to fix 2 or 3 letters on something from Grok that has 20 words, etc.
Removing watermarks no longer needs hours. With WatermarkRemover.io, you can remove watermarks in seconds without any editing or touch-ups, preserving image quality. All of it without a sign-up or subscription fee.

XTR-0 is the first way Extropic chips will be integrated with conventional computers. We intend to build more advanced systems around future TSUs that allow them to more easily integrate with conventional AI accelerators like GPUs. This could take the form of something simple like a PCIe card, or could in principle be as complicated as building a single chip that contains both a GPU and a TSU.
X0 houses a family of circuits that generate samples from primitive probability distributions. Our future chips will combine millions of these probabilistic circuits to run EBMs efficiently.
The probabilistic circuits on X0 output random continuous-time voltage signals. Repeatedly observing the signals (waiting sufficiently long between observations) allows a user to generate approximately independent samples from the distribution embodied by the circuit. These circuits are used to generate the random output voltage, making them much more energy efficient than their counterparts on deterministic digital computers.
Year 2015 face_with_colon_three
Researchers from MIT have created a 3D printer that is able to create objects out of glass.
