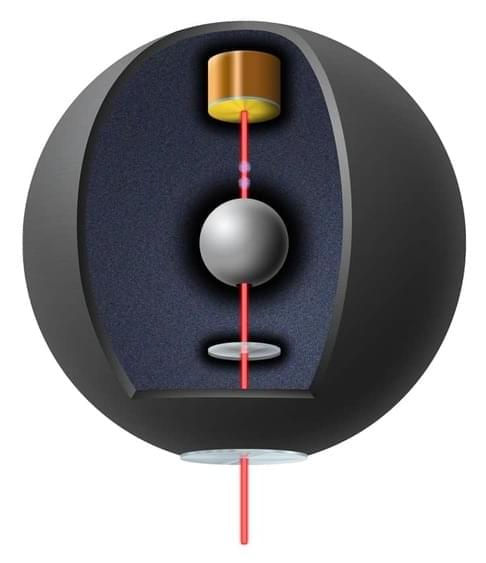
Exploring quantum gravity—for whom the pendulum swings.

Wageningen is one of a clutch of research institutions globally that hold patents on CRISPR, a technique that enables precise changes to be made to genomes, at specific locations. Other institutions — including the Broad Institute in Cambridge, Massachusetts, and the University of California, Berkeley, which have some of the largest portfolios of patents on the subject — also provide CRISPR tools and some intellectual property (IP) for free for non-profit use. But universities could do better to facilitate access to CRISPR technologies for research.
Universities hold the majority of CRISPR patents. They are in a strong position to ensure that the technology is widely shared for education and research.


The James Webb Space Telescope is scheduled for launch December 18. It will help scientists hunt for alien life on exoplanets and look to the beginning of time.

Circa 2000
A 1940 paper by Gamow and Mario Schoenberg was the first in a subject we now call particle astrophysics. The two authors presciently speculated that neutrinos could play a role in the cooling of massive collapsing stars. They named the neutrino reaction the Urca process, after a well known Rio de Janeiro casino. This name might seem a strange choice, but not to Gamow, a legendary prankster who once submitted a paper to Nature in which he suggested that the Coriolis force might account for his observation that cows chewed clockwise in the Northern Hemisphere and counterclockwise in the Southern Hemisphere.
In the 1940s Gamow began to attack, with his colleague Ralph Alpher, the problem of the origin of the chemical elements. Their first paper on the subject appeared in a 1948 issue of the Physical Review. At the last minute Gamow, liking the sound of ‘alpha, beta, gamma’, added his old friend Hans Bethe as middle author in absentia (Bethe went along with the joke, but the editors did not). Gamow and Alpher, with Robert Herman, then pursued the idea of an extremely hot neutron-dominated environment. They envisioned the neutrons decaying into protons, electrons and anti-neutrinos and, when the universe had cooled sufficiently, the neutrons and protons assembling heavier nuclei. They even estimated the photon background that would be necessary to account for nuclear abundances, suggesting a residual five-degree background radiation.
We now realize that their scheme was incorrect. The Universe began with roughly equal numbers of protons and neutrons. Collisions with electrons, positrons, neutrinos and anti-neutrinos are more important than neutron decay, and the absence of stable nuclei with atomic numbers of five and eight creates a barrier to further fabrication in the early Universe. Nevertheless Alpher, Gamow and Herman’s work was the first serious attempt to discuss the observable consequences of a big bang and the basic framework was correct. Ironically, the term ‘Big Bang’ was coined by Fred Hoyle, an advocate of a steady-state model of the universe, to make fun of Gamow’s efforts.

One of the U.S. Defense Department’s two prototype robot warships just fired its first missile.
The military on Friday hailed the test-launch of an SM-6 missile from the Unmanned Surface Vessel Ranger, sailing off the California coast, as “game-changing.”
It’s one thing for an unmanned vessel to launch a missile, however. It’s quite another for the same vessel autonomously to find and fix targets.

COPENHAGEN, Sept 8 (Reuters) — The world’s largest plant that sucks carbon dioxide directly from the air and deposits it underground is due to start operating on Wednesday, the company behind the nascent green technology said.
Swiss start-up Climeworks AG, which specialises in capturing carbon dioxide directly from the air, has partnered with Icelandic carbon storage firm Carbfix to develop a plant that sucks out up to 4,000 tons of CO2 per year.
That’s the equivalent of the annual emissions from about 790 cars. Last year, global CO2-emissions totalled 31.5 billion tonnes, according to the International Energy Agency.
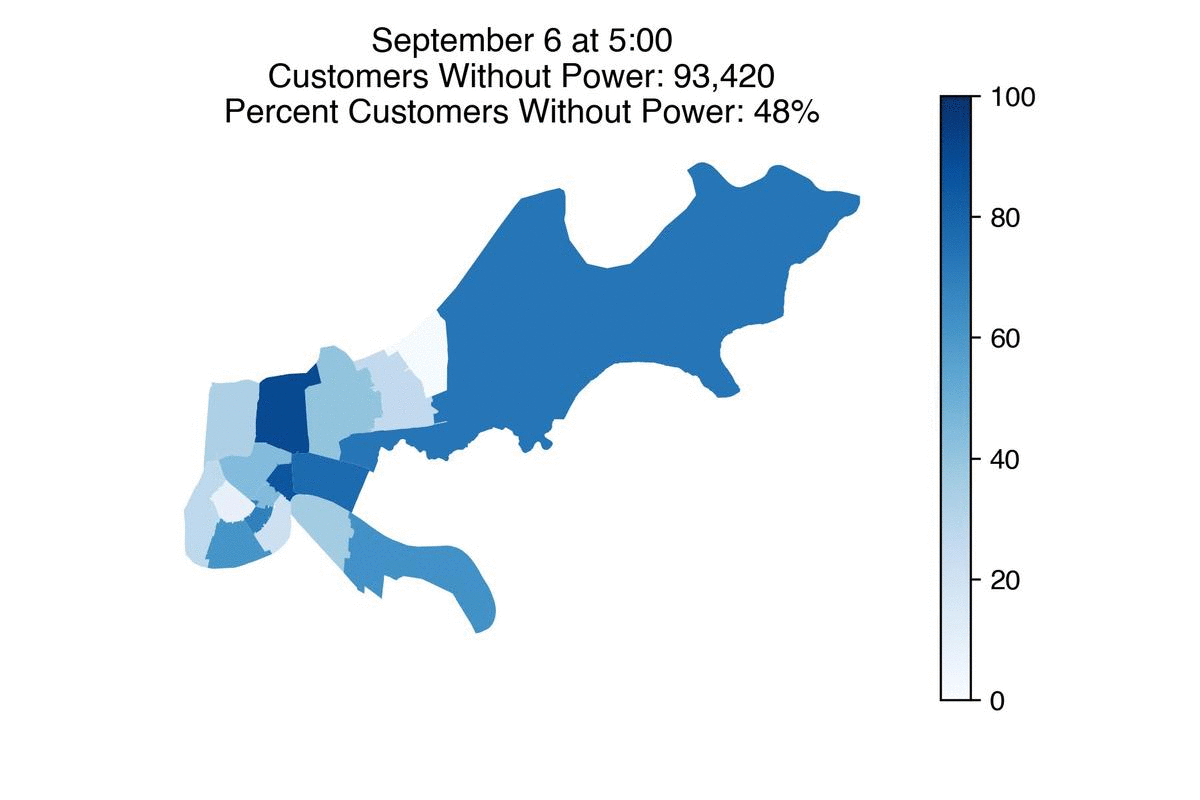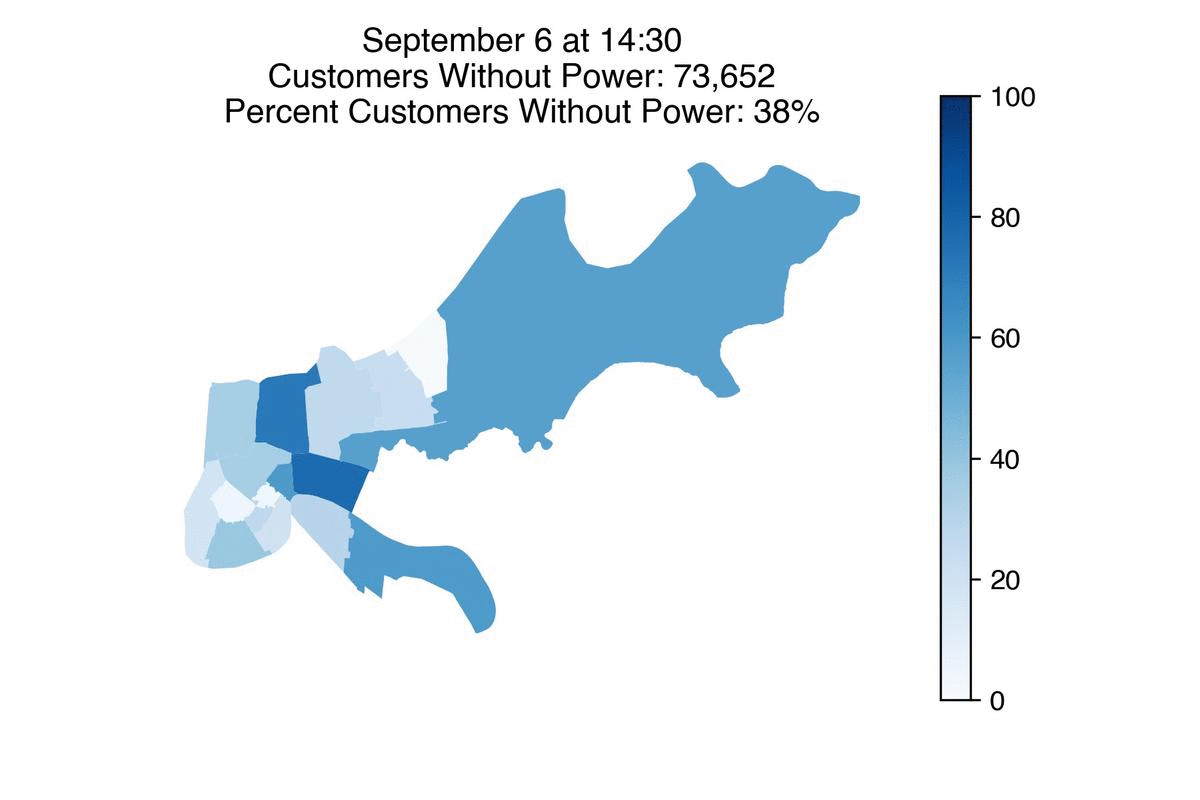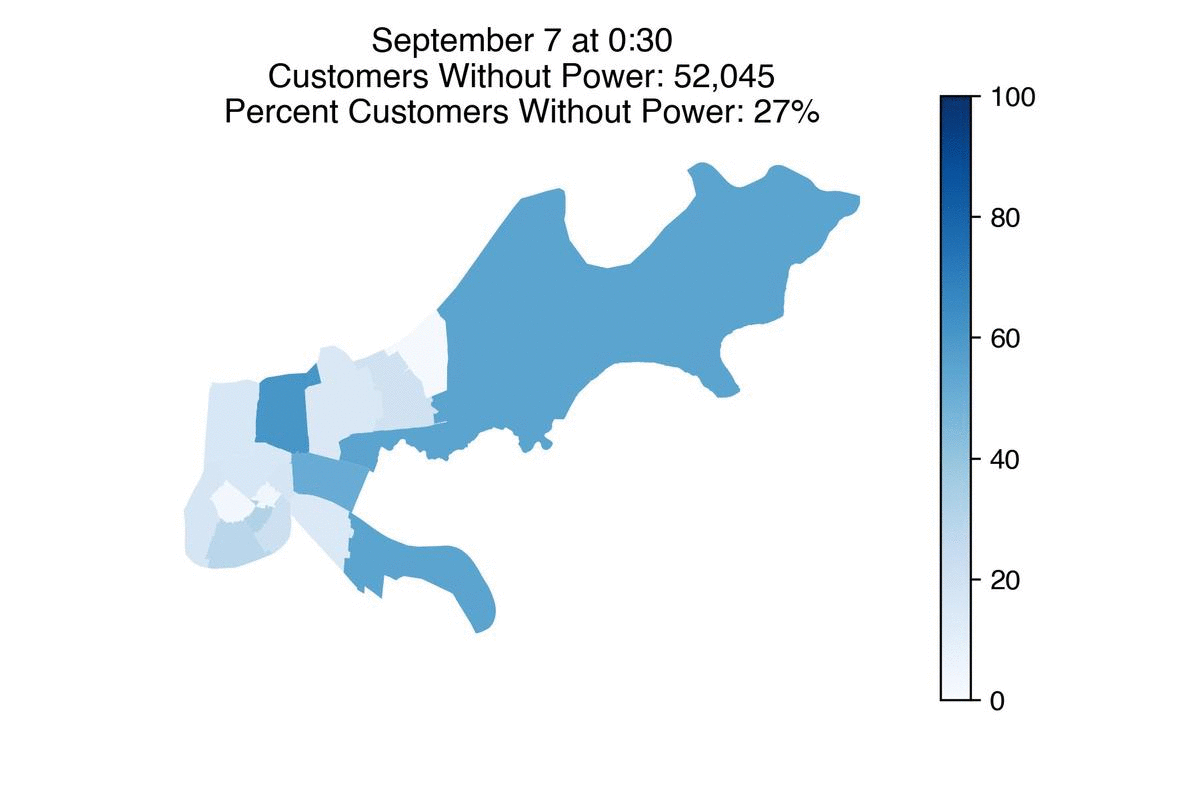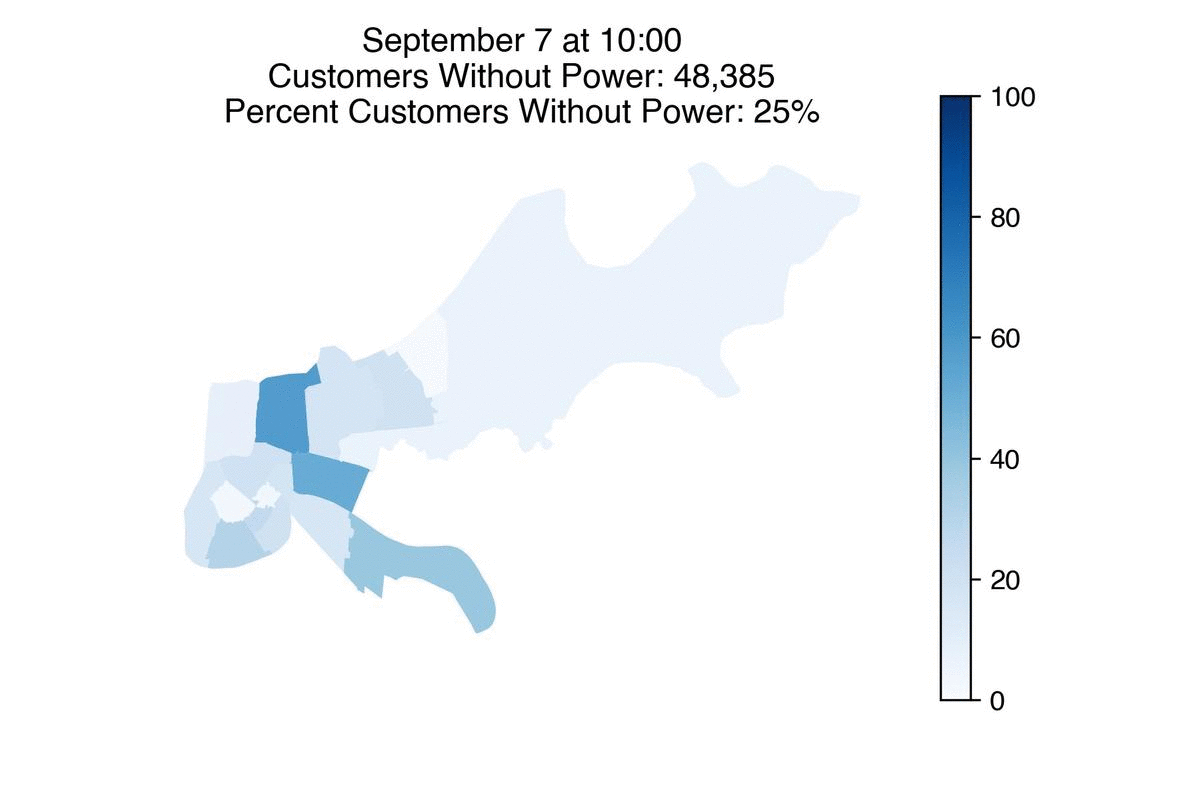
Entergy has restored power to more than half a million of its customers, Louisiana’s largest utility said Tuesday morning.
But there are still roughly 370,000 customers without power across the state, with about 50,000 of them in New Orleans. Entergy expects 90% of its customers in the city to have power back Wednesday.
Some neighborhoods such as Venetian Isles will likely take longer due to more damage in those areas. Details of power restoration timelines for specific neighborhoods in New Orleans can be found here.