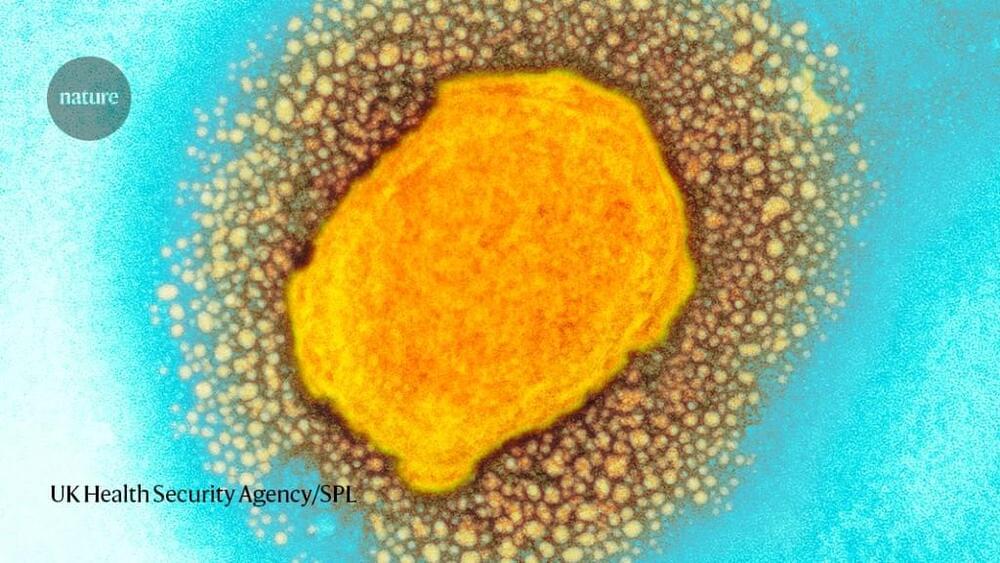
The virus is called monkeypox because researchers first detected it in laboratory monkeys in 1958, but it is thought to transmit to people from wild animals such as rodents or from other infected people. In an average year, a few thousand cases occur in Africa, typically in the western and central parts of the continent. But cases outside Africa have previously been limited to a handful that were associated with travel to Africa or with the importation of infected animals. The number of cases detected outside of Africa in the past week alone — which is almost certain to increase — has already surpassed the total number detected outside the continent since 1970, when the virus was first found to cause disease in humans. This rapid spread is what has scientists on high alert.
But monkeypox is no SARS-CoV-2, the coronavirus responsible for the COVID-19 pandemic, says Jay Hooper, a virologist at the US Army Medical Research Institute of Infectious Diseases in Fort Detrick, Maryland. It doesn’t transmit from person to person as readily, and because it is related to the smallpox virus, there are already treatments and vaccines on hand for curbing its spread. So although scientists are concerned — because any new viral behaviour is worrying — they are not panicked.
Unlike SARS-CoV-2, which spreads through tiny air-borne droplets called aerosols, monkeypox is thought to spread from close contact with bodily fluids, such as saliva from coughing. That means a person with monkeypox is likely to infect far fewer close contacts than someone with SARS-CoV-2, Hooper says. Both viruses can cause flu-like symptoms, but monkeypox also triggers enlarged lymph nodes and, eventually, distinctive fluid-filled lesions on the face, hands and feet. Most people recover from monkeypox in a few weeks without treatment.