
😃
The company announced a deal that could help significantly expand access to the Covid-19 treatment, but the agreement excludes a number of countries hit hard by the pandemic.
😃
The company announced a deal that could help significantly expand access to the Covid-19 treatment, but the agreement excludes a number of countries hit hard by the pandemic.

In quantum mechanics, counterfactual behaviours are generally associated with particles being affected by events taking place where they can’t be found. Here, the authors consider extended quantum Cheshire cat scenarios where a particle can be influenced in regions where only its disembodied property has entered.
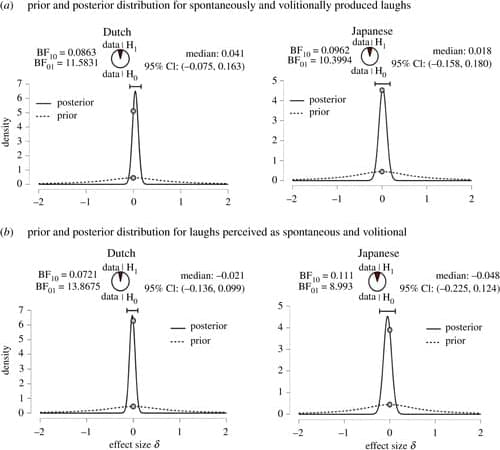
Laughter is a ubiquitous social signal. Recent work has highlighted distinctions between spontaneous and volitional laughter, which differ in terms of both production mechanisms and perceptual features. Here, we test listeners’ ability to infer group identity from volitional and spontaneous laughter, as well as the perceived positivity of these laughs across cultures. Dutch (n = 273) and Japanese (n = 131) participants listened to decontextualized laughter clips and judged (i) whether the laughing person was from their cultural in-group or an out-group; and (ii) whether they thought the laughter was produced spontaneously or volitionally. They also rated the positivity of each laughter clip. Using frequentist and Bayesian analyses, we show that listeners were able to infer group membership from both spontaneous and volitional laughter, and that performance was equivalent for both types of laughter. Spontaneous laughter was rated as more positive than volitional laughter across the two cultures, and in-group laughs were perceived as more positive than out-group laughs by Dutch but not Japanese listeners. Our results demonstrate that both spontaneous and volitional laughter can be used by listeners to infer laughers’ cultural group identity.
This article is part of the theme issue ‘Voice modulation: from origin and mechanism to social impact (Part II)’.
Laughter is a frequently occurring and socially potent nonverbal vocalization, which is frequently used to signal affiliation, reward or cooperative intent, and often helps to maintain and strengthen social bonds [1,2]. A key distinction is whether laughs are spontaneous or volitional [3,4]. Spontaneous and volitional laughs are thought to be generated by different vocal production mechanisms. We often laugh spontaneously with little volitional control, which is thought to typically reflect an internal emotional state. Yet laughter can also be produced with volitional modulation of vocal output, which is more likely to express polite agreement in conversation [5,6]. Recent research has shown that listeners’ ability to differentiate individual speakers is impaired for spontaneous, as compared to volitional, laughter [7,8].
Posted in cosmology

A new model explains the current density of dark matter by proposing that conventional matter converted to dark matter in the early Universe.
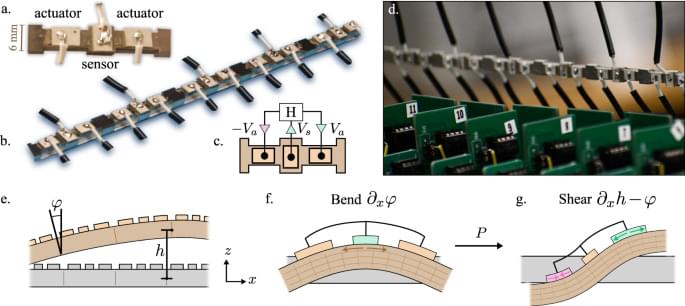
Mechanical metamaterials can be engineered with properties not possible in ordinary materials. Here the authors demonstrate and study an active metamaterial with self-sensing characteristics that enables odd elastic properties not observed in passive media.
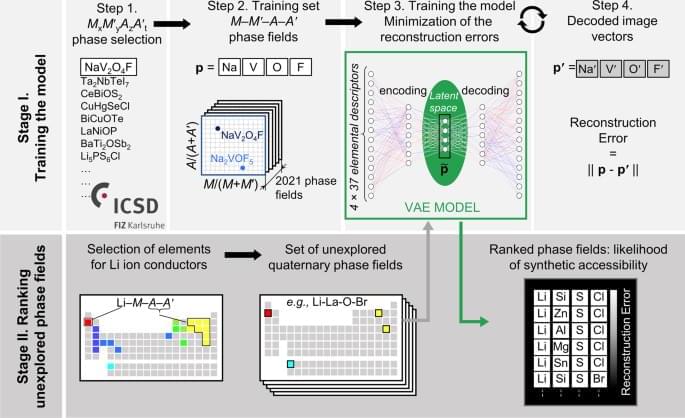
Machine learning (ML) models are powerful tools to study multivariate correlations that exist within large datasets but are hard for humans to identify16,23. Our aim is to build a model that captures the chemical interactions between the element combinations that afford reported crystalline inorganic materials, noting that the aim of such models is efficacy rather than interpretability, and that as such they can be complementary guides to human experts. The model should assist expert prioritization between the promising element combinations by ranking them quantitatively. Researchers have practically understood how to identify new chemistries based on element combinations for phase-field exploration, but not at significant scale. However, the prioritization of these attractive knowledge-based choices for experimental and computational investigation is critical as it determines substantial resource commitment. The collaborative ML workflow24,25 developed here includes a ML tool trained across all available data at a scale beyond that, which humans can assimilate simultaneously to provide numerical ranking of the likelihood of identifying new phases in the selected chemistries. We illustrate the predictive power of ML in this workflow in the discovery of a new solid-state Li-ion conductor from unexplored quaternary phase fields with two anions. To train a model to assist prioritization of these candidate phase fields, we extracted 2021 MxM ′yAzA ′t phases reported in ICSD (Fig. 1, Step 1), and associated each phase with the phase fields M-M ′-A-A′ where M, M ′ span all cations, A, A ′ are anions {N3−, P3−, As3−, O2−, S2−, Se2−, Te2−, F−, Cl−, Br−, and I−} and x, y, z, t denote concentrations (Fig. 1, Step 2). Data were augmented by 24-fold elemental permutations to enhance learning and prevent overfitting (Supplementary Fig. 2).
ML models rely on using appropriate features (often called descriptors)26 to describe the data presented, so feature selection is critical to the quality of the model. The challenge of selecting the best set of features among the multitude available for the chemical elements (e.g., atomic weight, valence, ionic radius, etc.)26 lies in balancing competing considerations: a small number of features usually makes learning more robust, while limiting the predictive power of resulting models, large numbers of features tend to make models more descriptive and discriminating while increasing the risk of overfitting. We evaluated 40 individual features26,27 (Supplementary Fig. 4, 5) that have reported values for all elements and identify a set of 37 elemental features that best balance these considerations. We thus describe each phase field of four elements as a vector in a 148-dimensional feature space (37 features × 4 elements = 148 dimensions).
To infer relationships between entries in such a high-dimensional feature space in which the training data are necessarily sparsely distributed28, we employ the variational autoencoder (VAE), an unsupervised neural network-based dimensionality reduction method (Fig. 1, Step 3), which quantifies nonlinear similarities in high-dimensional unlabelled data29 and, in addition to the conventional autoencoder, pays close attention to the distribution of the data features in multidimensional space. A VAE is a two-part neural network, where one part is used to compress (encode) the input vectors into a lower-dimensional (latent) space, and the other to decode vectors in latent space back into the original high-dimensional space. Here we choose to encode the 148-dimensional input feature space into a four-dimensional latent feature space (Supplementary Methods).
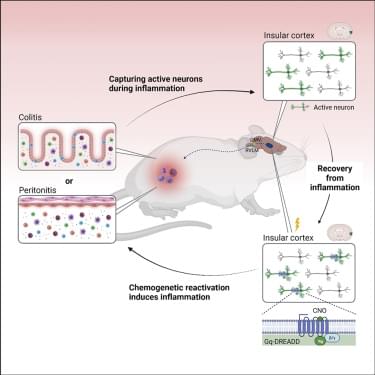
Neuronal ensembles in the mouse insular cortex activated during distinct inflammatory conditions are capable of retrieving or suppressing the associated peripheral immunological responses.

Rich dynamics in a living neuronal system can be considered as a computational resource for physical reservoir computing (PRC). However, PRC that generates a coherent signal output from a spontaneously active neuronal system is still challenging. To overcome this difficulty, we here constructed a closed-loop experimental setup for PRC of a living neuronal culture, where neural activities were recorded with a microelectrode array and stimulated optically using caged compounds. The system was equipped with first-order reduced and controlled error learning to generate a coherent signal output from a living neuronal culture. Our embodiment experiments with a vehicle robot demonstrated that the coherent output served as a homeostasis-like property of the embodied system from which a maze-solving ability could be generated. Such a homeostatic property generated from the internal feedback loop in a system can play an important role in task solving in biological systems and enable the use of computational resources without any additional learning.

The World Food Programme (WFP), the UN’s food assistance arm, outlined how $6.6 billion in investments might prevent 42 million people in 43 countries from becoming hungry. In a tweet outlining the plan, WFP President David Beasley singled out Musk, the world’s wealthiest individual by far.

Is the metaverse going to change life as we know it? What does this mean for our future?