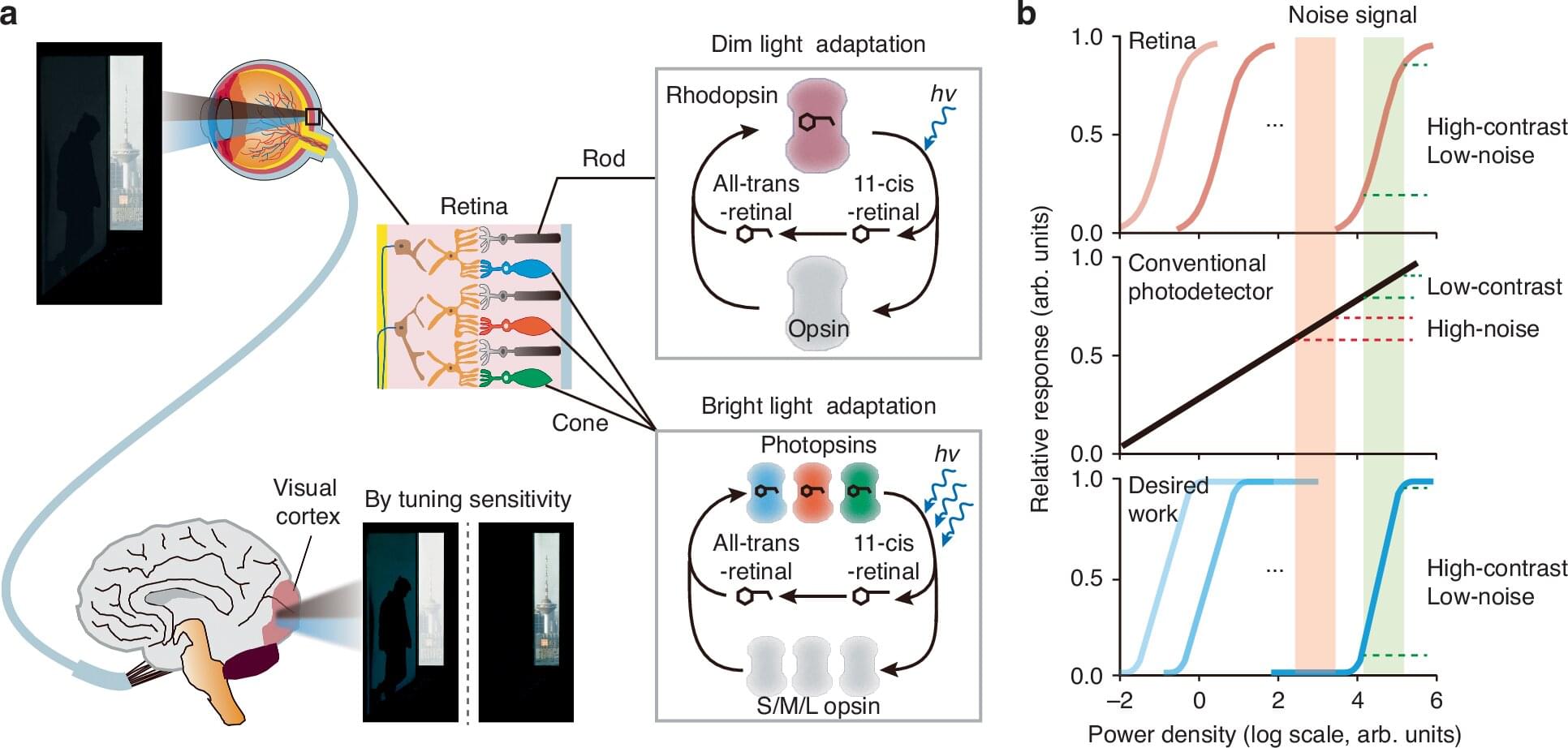
Drawing inspiration from the remarkable adaptability of the human eye, researchers from the Institute of Metal Research (IMR) of the Chinese Academy of Sciences have developed a novel phototransistor with tunable sensitivity.
This breakthrough provides an efficient solution for detecting low-contrast targets in complex visual environments, which is a critical challenge for advanced machine vision systems in applications such as precision guidance and smart surveillance.
The results are published in Light: Science & Applications.







{kind=link}