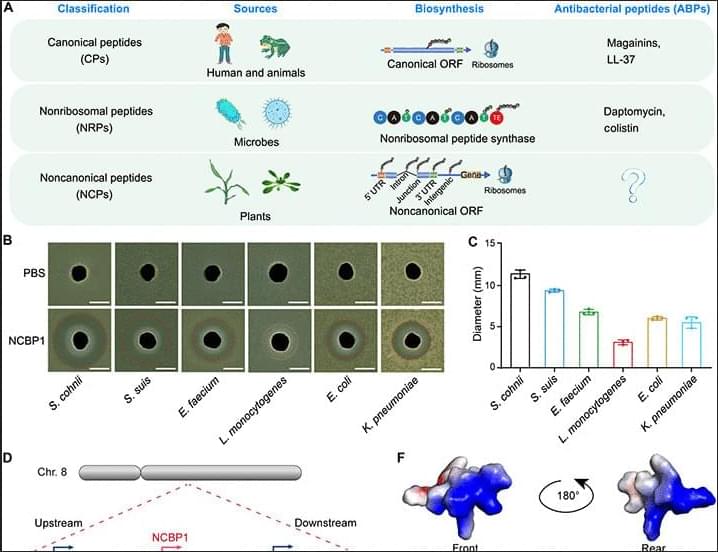
A plant-derived peptide shows antibacterial and antifungal activity, targeting MDR pathogens and enhancing maize resistance.



Inspired by biological cells, the robots are made of water encased in Teflon armor and are each about the size of a grain of rice.
As the world makes more use of renewable energy sources, new battery technology is needed to store electricity for the times when the sun isn’t shining, and the wind isn’t blowing.
“Current lithium batteries have reached their limitations in terms of energy storage capability, life cycle, and safety,” says Xiaolei Wang, a professor of chemical engineering at the University of Alberta in Edmonton. “They’re good for applications like electric vehicles and portable electronics, but they’re not suitable for large-scale grid-level energy storage.”
With the help of the Canadian Light Source at the University of Saskatchewan, Wang and his team are developing new technologies to help make grid-level aqueous batteries that can use seawater as an electrolyte. The study is published in the journal Advanced Materials.
Where do we come from? Why are we here? These perennial questions have echoed across cultures and epochs, from mythological accounts to scientific inquiries. In The Origins of Us, I explore a unified narrative that transcends classical reductionist models

Researchers have developed a new material that, by harnessing the power of sunlight, can clear water of dangerous pollutants. Created through a combination of soft chemistry gels and electrospinning—a technique where electrical force is applied to liquid to craft small fibers—the team constructed thin fiber-like strips of titanium dioxide (TiO₂), a compound often utilized in solar cells, gas sensors and various self-cleaning technologies.
Despite being a great alternative energy source, solar fuel systems that utilize TiO₂ nanoparticles are often power-limited because they can only undergo photocatalysis, or create chemical reactions, by absorbing non-visible UV light. This can cause significant challenges to implementation, including low efficiency and the need for complex filtration systems.
Yet when researchers added copper to the material to improve this process, their new structures, called nanomats, were able to absorb enough light energy to break down harmful pollutants in air and water, said Pelagia-Iren Gouma, lead author of the study and a professor of materials science and engineering at The Ohio State University.
{kind=link}