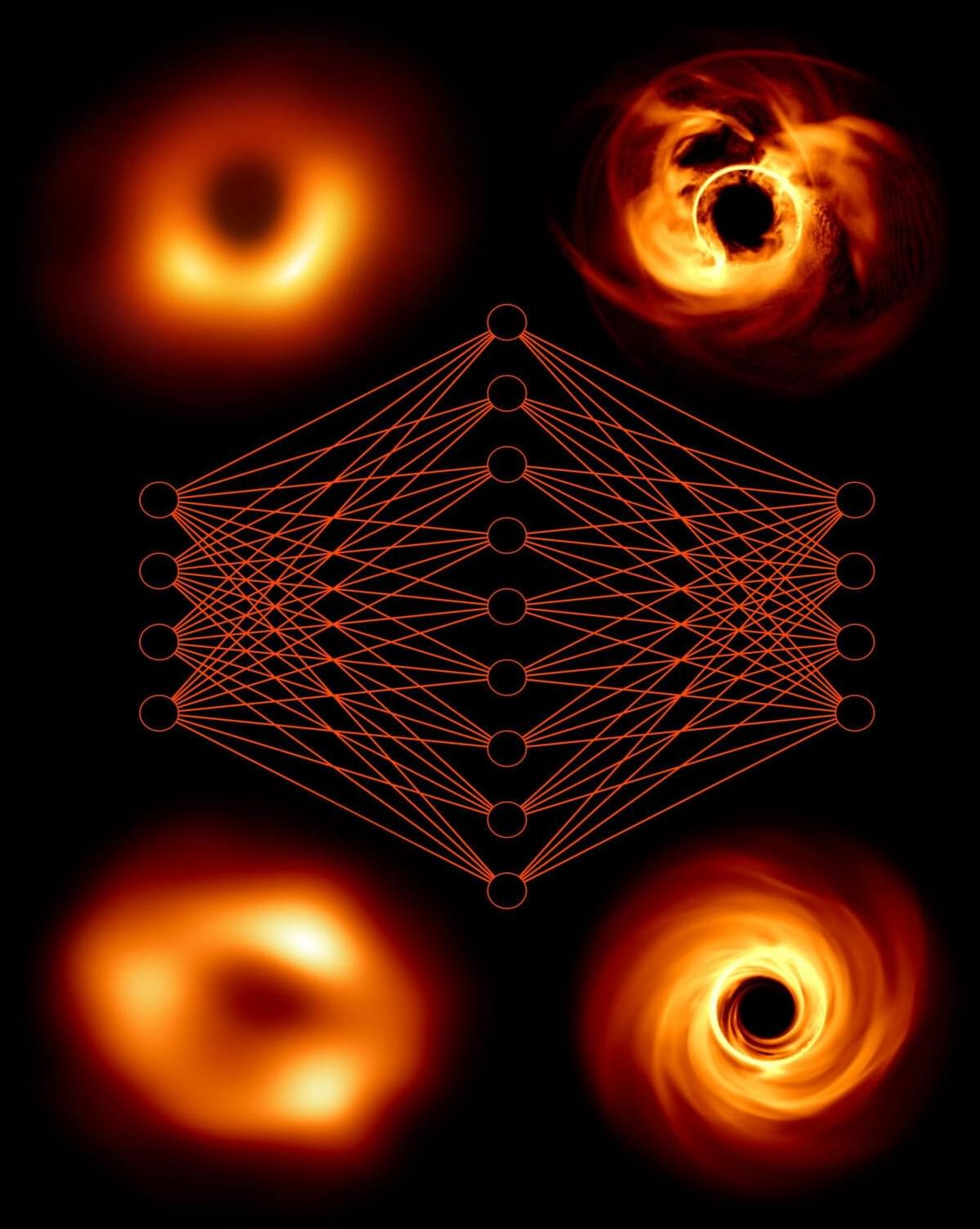
A team of astronomers led by Michael Janssen (Radboud University, The Netherlands) has trained a neural network with millions of synthetic black hole data sets. Based on the network and data from the Event Horizon Telescope, they now predict, among other things, that the black hole at the center of our Milky Way is spinning at near top speed.
The astronomers have published their results and methodology in three papers in the journal Astronomy & Astrophysics.
In 2019, the Event Horizon Telescope Collaboration released the first image of a supermassive black hole at the center of the galaxy M87. In 2022, they presented an image of the black hole in our Milky Way, Sagittarius A*. However, the data behind the images still contained a wealth of hard-to-crack information. An international team of researchers trained a neural network to extract as much information as possible from the data.