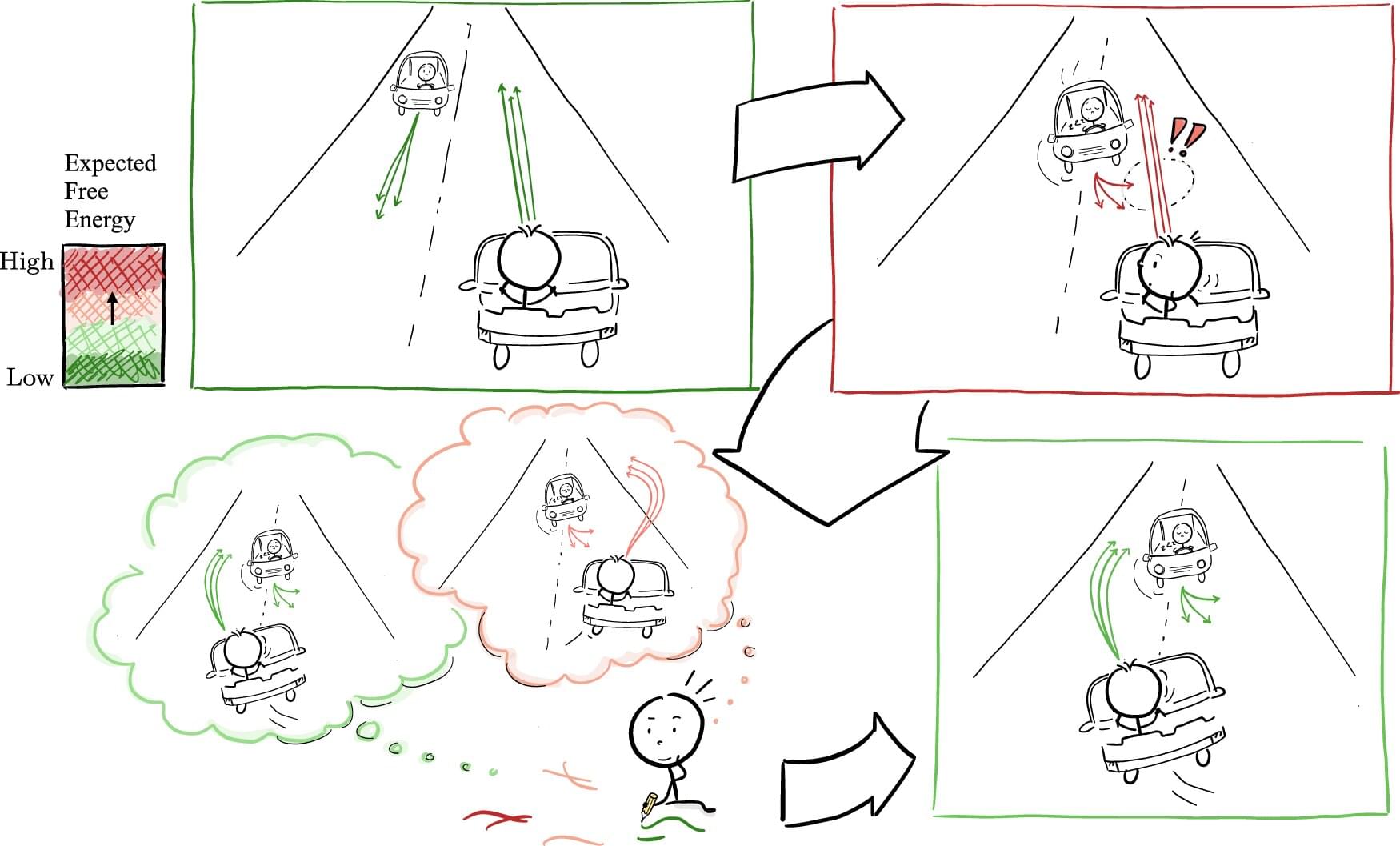
Chinese researchers from Tianjin University and the Southern University of Science and Technology have created a groundbreaking robot powered by a tiny organoid derived from human stem cells grafted to a neural interface. This breakthrough system allows the robot to learn tasks like obstacle avoidance and object manipulation.
Described as the “world’s first open-source brain-on-chip intelligent complex information interaction system,” the technology marks a significant advancement in brain-computer interfaces (BCIs) – devices that translate between neural and computational signals.
The South China Morning Post notes that the scientists grew the organoids from human pluripotent stem cells, which can develop into various cell types, including neural tissue. These synthetic-organic (pardon the oxymoron) brain cells are linked to the robot’s neural interface, enabling communication between the neural tissue and the robot’s systems. Although the presented images of pink brain matter are merely mockups (below), the actual organoids are much smaller.