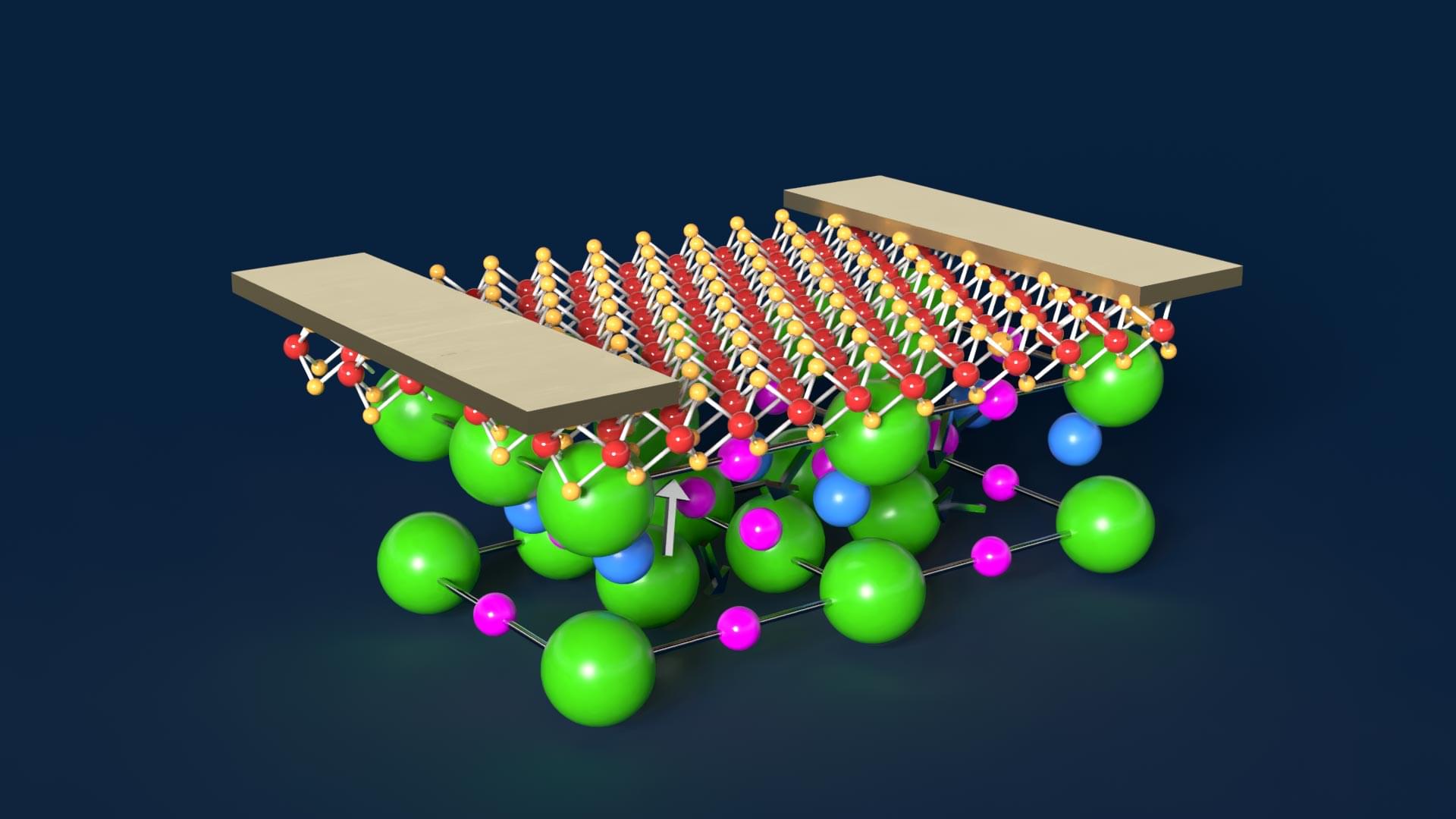
The National Synchrotron Light Source II (NSLS-II)—a U.S. Department of Energy (DOE) Office of Science user facility at DOE’s Brookhaven National Laboratory—is among the world’s most advanced synchrotron light sources, enabling and supporting science across various disciplines. Advances in automation, robotics, artificial intelligence (AI), and machine learning (ML) are transforming how research is done at NSLS-II, streamlining workflows, enhancing productivity, and alleviating workloads for both users and staff.
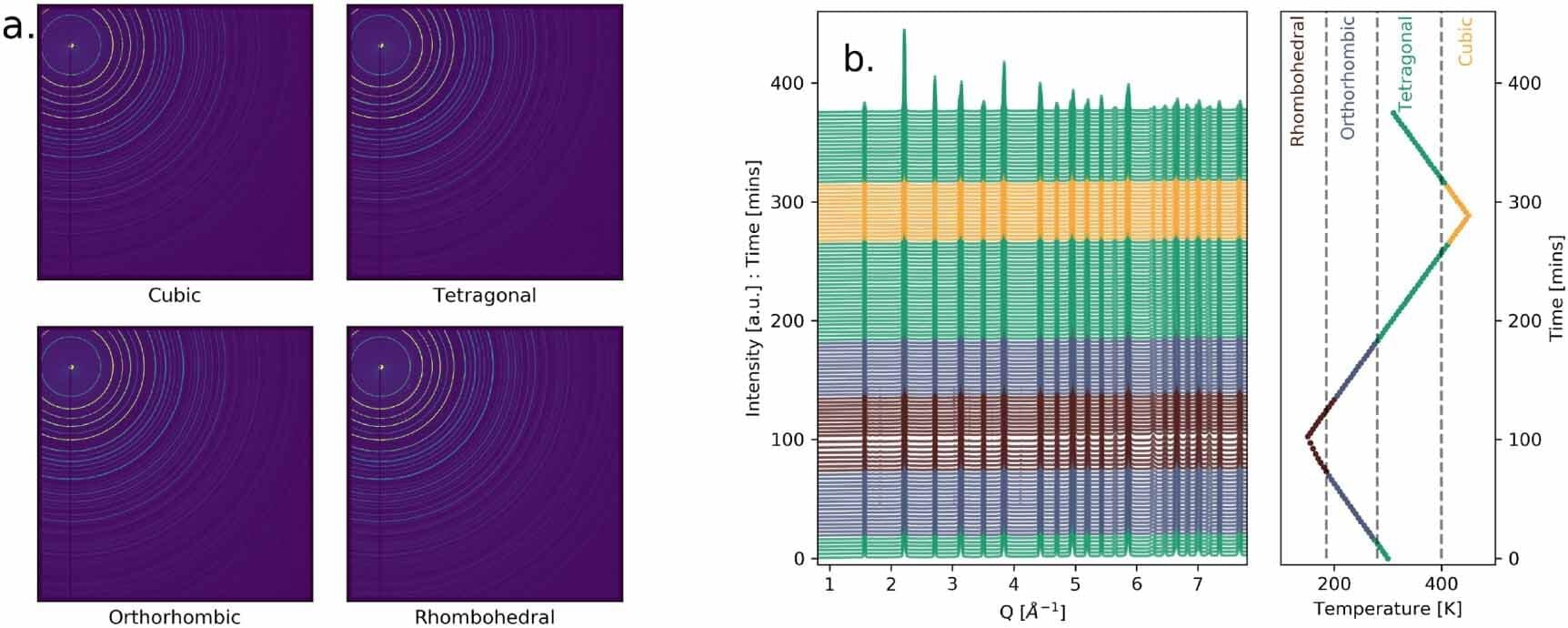
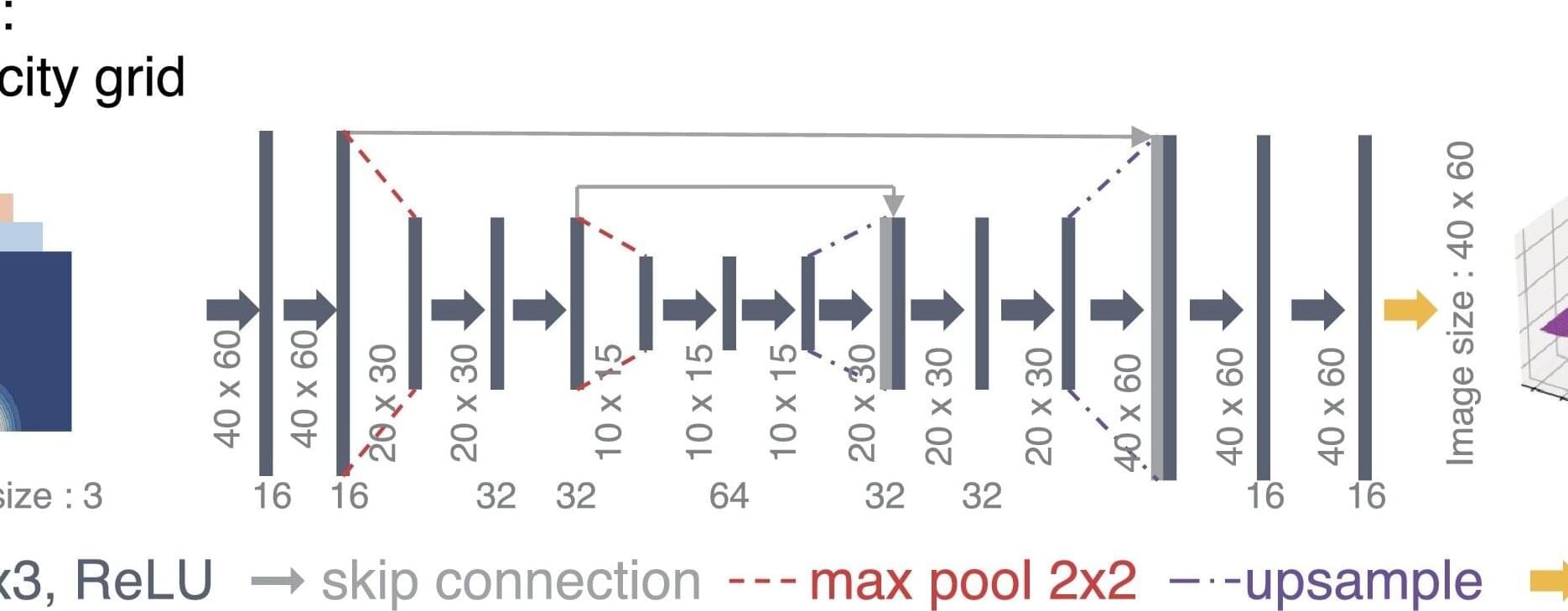
As synchrotron facilities rapidly advance—providing brighter beams, automation, and robotics to accelerate experiments and discovery—the quantity, quality, and speed of data generated during an experiment continues to increase. Visualizing, analyzing, and sorting these large volumes of data can require an impractical, if not impossible, amount of time and attention.
Presenting scientists with real-time analysis is as important as preparing samples for beam time, optimizing the experiment, performing error detection, and remedying anything that may go awry during a measurement.






{kind=link}
{kind=link}