
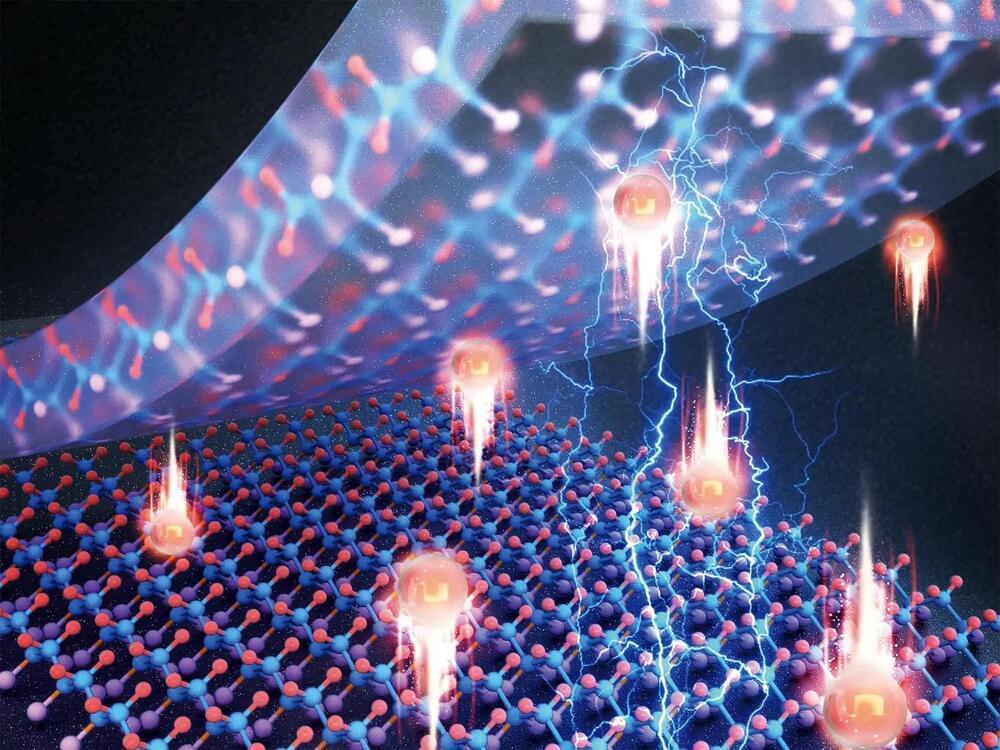
The arrangement of electrons in matter, known as the electronic structure, plays a crucial role in fundamental but also applied research, such as drug design and energy storage. However, the lack of a simulation technique that offers both high fidelity and scalability across different time and length scales has long been a roadblock for the progress of these technologies.
Researchers from the Center for Advanced Systems Understanding (CASUS) at the Helmholtz-Zentrum Dresden-Rossendorf (HZDR) in Görlitz, Germany, and Sandia National Laboratories in Albuquerque, New Mexico, U.S., have now pioneered a machine learning–based simulation method that supersedes traditional electronic structure simulation techniques.
Their Materials Learning Algorithms (MALA) software stack enables access to previously unattainable length scales. The work is published in the journal npj Computational Materials.





{kind=link}