A faction of scribes is putting guardrails around AI’s encroachment on their work. The effects will echo in industries far beyond Hollywood.


Source: allgord/iStock.
Scientists have developed a new artificial neural network that mimics the brain structures of ants and helps robots recognize and remember routes in complex natural environments, such as cornfields. The approach could improve the performance of agricultural robots that need to move through dense and plant-filled landscapes.
Bill Gates is a staunch advocate for nuclear energy, and although he no longer oversees day-to-day operations at Microsoft, its business strategy still mirrors the sentiment. According to a new job listing first spotted on Tuesday by The Verge, the tech company is currently seeking a “principal program manager” for nuclear technology tasked with “maturing and implementing a global Small Modular Reactor (SMR) and microreactor energy strategy.” Once established, the nuclear energy infrastructure overseen by the new hire will help power Microsoft’s expansive plans for both cloud computing and artificial intelligence.
Among the many, many, (many) concerns behind AI technology’s rapid proliferation is the amount of energy required to power such costly endeavors—a worry exacerbated by ongoing fears pertaining to climate collapse. Microsoft believes nuclear power is key to curtailing the massive amounts of greenhouse emissions generated by fossil fuel industries, and has made that belief extremely known in recent months.
[Related: Microsoft thinks this startup can deliver on nuclear fusion by 2028.].


And that is just health care. In 1940, there were 42 workers per beneficiary of Social Security. Today, there are only 2.8 workers per beneficiary, and that number is getting smaller. We are going broke, and the young men who will play a huge role in determining our nation’s future are going there with AI girlfriends in their pockets.
While the concept of an AI girlfriend may seem like a joke, it really isn’t that funny. It is enabling a generation of lonely men to stay lonely and childless, which will have devastating effects on the U.S. economy in less than a decade.
Professor Nita Farahany reveals to Azeem Azhar the startling advancements of brain-scanning technology and the extraordinary implications this tech has for privacy and humanity.
——-
Like this video? Subscribe: https://www.youtube.com/Bloomberg?sub_confirmation=1
Become a Quicktake Member for exclusive perks: https://www.youtube.com/bloomberg/join.
Bloomberg Originals offers bold takes for curious minds on today’s biggest topics. Hosted by experts covering stories you haven’t seen and viewpoints you haven’t heard, you’ll discover cinematic, data-led shows that investigate the intersection of business and culture. Exploring every angle of climate change, technology, finance, sports and beyond, Bloomberg Originals is business as you’ve never seen it.
Subscribe for business news, but not as you’ve known it: exclusive interviews, fascinating profiles, data-driven analysis, and the latest in tech innovation from around the world.
Visit our partner channel Bloomberg Quicktake for global news and insight in an instant.
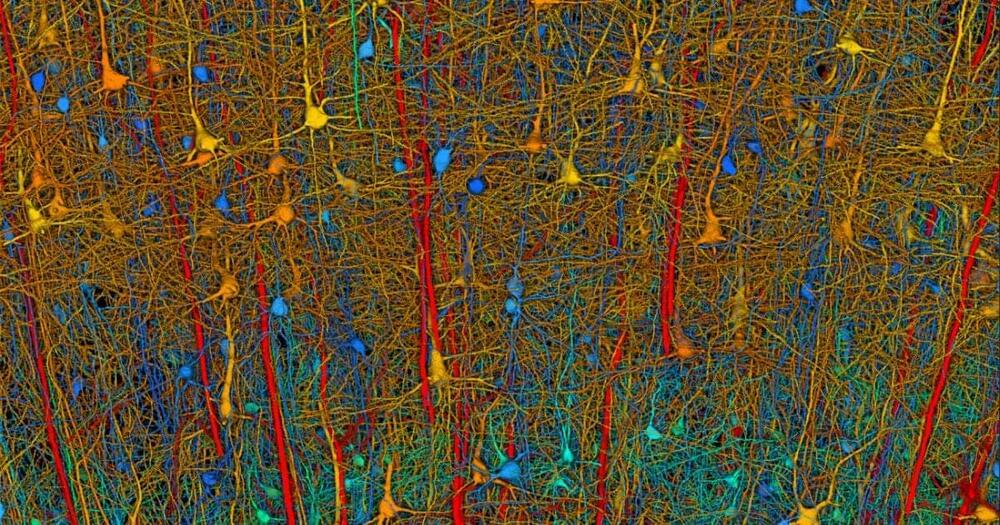
Would hope this means we dont Need to reverse engineer and are done w/ the brains of insects. From here, id like to see done in about following order, reverse engineer brains of: 1. Mice, 2. Lab Rats, 3. Crows (small brains, but supposedly smarter than chimps) 4. Octopi, 5. Pigs, 6. Chimps, and 7. and end on the human brain. Would hope we can do work on each in the build up to human brains, mainly tec it will require to reverse engineer all mentioned. Maybe it leads no where, or maybe we need it all to solve Agi. Also, aim for completion by 12/31/2029. Wanted to add, i believe should be an international effort: US, Canada, EU, Israel, Korea, Japan, etc… instead of just being a US project.
By Anne J. Manning Harvard Staff Writer.
Date September 26, 2023 September 27, 2023.

{kind=link}
{kind=link}
{kind=link}