Sound can do more than just provide a nice beat. Sound waves have been used for everything from mapping the seafloor to breaking apart kidney stones. Thanks to a unique material structure, researchers can now move and position objects underwater without ever touching them directly.
A metamaterial is a composite material that exhibits unique properties due to its structure. Zhang’s metamaterial features a small sawtooth pattern on its surface, which allows adjacent speakers to exert different forces on the material based on how the sound waves reflect off it. By carefully targeting the floating or submerged metamaterial with precise sound waves, Zhang can push and rotate any object attached to it exactly as much as he wants.
Launched on March 11, NASA’s SPHEREx space observatory has spent the last six weeks undergoing checkouts, calibrations, and other activities to ensure it is working as it should. Now it’s mapping the entire sky—not just a large part of it—to chart the positions of hundreds of millions of galaxies in 3D to answer some big questions about the universe.
On May 1, the spacecraft began regular science operations, which consist of taking about 3,600 images per day for the next two years to provide new insights about the origins of the universe, galaxies, and the ingredients for life in the Milky Way.
“Thanks to the hard work of teams across NASA, industry, and academia that built this mission, SPHEREx is operating just as we’d expected and will produce maps of the full sky unlike any we’ve had before,” said Shawn Domagal-Goldman, acting director of the Astrophysics Division at NASA Headquarters in Washington.
White light-emitting diodes (LEDs), the semiconductor devices underpinning the functioning of countless lighting technologies on the market today, were first released to the public in 1996. Following their commercial debut, these devices have fueled significant advancements within the electronics and lighting industry, due to their remarkable energy efficiencies and extended lifespans.
Researchers at the University of Cambridge and ETH Zurich recently carried out a study aimed at re-tracing the development of white LEDs over the past three decades, as well as trends in their costs and innovations in other engineering fields that fueled their advancement. Their paper, published in Nature Energy, was part of a larger research project that investigated the factors driving innovation in the clean energy sector.
“As part of our research, we looked at three key technologies at the forefront of the ongoing energy transition: solar photovoltaics for energy generation, lithium-ion batteries for energy storage, and white LEDs for efficient energy use in lighting,” Michael P. Weinold, first author of the paper, told Tech Xplore.
When zebrafish are relocated to a new environment, they seek protection by diving and staying at the safety home, until they feel safe enough to explore the unfamiliar environment (26). The swimming trajectories showed that zebrafish in the control group can swiftly explore and adapt to the novel environment, but chronic exposure to acrylamide reduces the ability to adapt to the unfamiliar environment (Fig. 3 A). Visualized heatmaps showed significant changes in swimming trajectories of zebrafish in the acrylamide exposure groups compared with those in the control group (Fig. 3 B). Furthermore, we found the swimming time and distance ratios in Zone 1 exhibited a dose-dependent decreasing trend in acrylamide exposure groups. Chronic exposure to acrylamide (0.5 mM) significantly decreased both swimming time and distance in Zone 1 and increased those in Zone 2 (Fig. 3 C and D). We recorded the novel object exploration test to visualize the behavioral alteration between the control and each acrylamide-treated group (Movie S3). The movie displays that zebrafish in the control group could swiftly explore and adapt to the novel environment, but chronic exposure to acrylamide reduced the ability to adapt to the unfamiliar environment, which indicated that acrylamide induces anxiety-and depressive-like behaviors by reducing exploration ability of zebrafish.
Moreover, the social preference test was used to assess sociality of zebrafish. Since the zebrafish are a group preference species, they frequently swim by forming a school and swim closely to one another (27). In the current social preference test, representative radar maps and visualized heatmaps exhibited significant changes of preference in swimming trajectories of zebrafish in acrylamide exposure groups compared to those in the control group, indicating that chronic exposure to acrylamide remarkably impairs the sociality of zebrafish (Fig. 3 E–G). For detailed parameters of behavioral trajectories, chronic exposure to acrylamide (0.5 mM) significantly increased both swimming time and distance ratios in the left zone and decreased those in the right zone (Fig. 3 H and I). Notably, chronic exposure to acrylamide (0.5 mM) significantly elevated traversing times and number of crossing the middle line (Fig. 3 J and K).
AI surveillance, AI surveillance systems, AI surveillance technology, AI camera systems, artificial intelligence privacy, AI tracking systems, AI in public surveillance, smart city surveillance, facial recognition technology, real time surveillance ai, AI crime prediction, predictive policing, emotion detecting ai, AI facial recognition, privacy in AI era, AI and data collection, AI spying tech, surveillance capitalism, government surveillance 2025, AI monitoring tools, AI tracking devices, AI and facial data, facial emotion detection, emotion recognition ai, mass surveillance 2025, AI in smart cities, china AI surveillance, skynet china, AI scanning technology, AI crowd monitoring, AI face scanning, AI emotion scanning, AI powered cameras, smart surveillance system, AI and censorship, privacy and ai, digital surveillance, AI surveillance dangers, AI surveillance ethics, machine learning surveillance, AI powered face id, surveillance tech 2025, AI vs privacy, AI in law enforcement, AI surveillance news, smart city facial recognition, AI and security, AI privacy breach, AI threat to privacy, AI prediction tech, AI identity tracking, AI eyes everywhere, future of surveillance, AI and human rights, smart cities AI control, AI facial databases, AI surveillance control, AI emotion mapping, AI video analytics, AI data surveillance, AI scanning behavior, AI and behavior prediction, invisible surveillance, AI total control, AI police systems, AI surveillance usa, AI surveillance real time, AI security monitoring, AI surveillance 2030, AI tracking systems 2025, AI identity recognition, AI bias in surveillance, AI surveillance market growth, AI spying software, AI privacy threat, AI recognition software, AI profiling tech, AI behavior analysis, AI brain decoding, AI surveillance drones, AI privacy invasion, AI video recognition, facial recognition in cities, AI control future, AI mass monitoring, AI ethics surveillance, AI and global surveillance, AI social monitoring, surveillance without humans, AI data watch, AI neural surveillance, AI surveillance facts, AI surveillance predictions, AI smart cameras, AI surveillance networks, AI law enforcement tech, AI surveillance software 2025, AI global tracking, AI surveillance net, AI and biometric tracking, AI emotion AI detection, AI surveillance and control, real AI surveillance systems, AI surveillance internet, AI identity control, AI ethical concerns, AI powered surveillance 2025, future surveillance systems, AI surveillance in cities, AI surveillance threat, AI surveillance everywhere, AI powered recognition, AI spy systems, AI control cities, AI privacy vs safety, AI powered monitoring, AI machine surveillance, AI surveillance grid, AI digital prisons, AI digital tracking, AI surveillance videos, AI and civilian monitoring, smart surveillance future, AI and civil liberties, AI city wide tracking, AI human scanner, AI tracking with cameras, AI recognition through movement, AI awareness systems, AI cameras everywhere, AI predictive surveillance, AI spy future, AI surveillance documentary, AI urban tracking, AI public tracking, AI silent surveillance, AI surveillance myths, AI surveillance dark side, AI watching you, AI never sleeps, AI surveillance truth, AI surveillance 2025 explained, AI surveillance 2025, future of surveillance technology, smart city surveillance, emotion detecting ai, predictive AI systems, real time facial recognition, AI and privacy concerns, machine learning surveillance, AI in public safety, neural surveillance systems, AI eye tracking, surveillance without consent, AI human behavior tracking, artificial intelligence privacy threat, AI surveillance vs human rights, automated facial ID, AI security systems 2025, AI crime prediction, smart cameras ai, predictive policing technology, urban surveillance systems, AI surveillance ethics, biometric surveillance systems, AI monitoring humans, advanced AI recognition, AI watchlist systems, AI face tagging, AI emotion scanning, deep learning surveillance, AI digital footprint, surveillance capitalism, AI powered spying, next gen surveillance, AI total control, AI social monitoring, AI facial mapping, AI mind reading tech, surveillance future cities, hidden surveillance networks, AI personal data harvesting, AI truth detection, AI voice recognition monitoring, digital surveillance reality, AI spy software, AI surveillance grid, AI CCTV analysis, smart surveillance networks, AI identity tracking, AI security prediction, mass data collection ai, AI video analytics, AI security evolution, artificial intelligence surveillance tools, AI behavioral detection, AI controlled city, AI surveillance news, AI surveillance system explained, AI visual tracking, smart surveillance 2030, AI invasion of privacy, facial detection ai, AI sees you always, AI surveillance rising, future of AI spying, next level surveillance, AI technology surveillance systems, ethical issues in AI surveillance, AI surveillance future risks.
*An S, Zhang S, Guo T, Lu S, Zhang W, Cai Z (2025) Impacts of generative AI on student teachers’ task performance and collaborative knowledge construction process in mind mapping-based collaborative environment. Comput Educ 227. https://doi.org/10.1016/j.compedu.2024.105227.
Researchers demonstrate an active-fluid system whose behaviors map directly to predictions of the six-vertex model—an exactly solvable model that was originally developed to explain the behavior of ice.
Active fluids—collections of self-propelled agents such as bacteria, cells, or colloids—consume energy to move, flowing without being pushed [1]. These materials break the conventional rules of fluid dynamics, as they can flow spontaneously, switch direction without apparent cause, and organize into complex patterns with no external control. Active fluids were initially studied to understand the collective dynamics observed in biological systems. Now they offer a rich playground for exploring nonequilibrium physics. Yet, in the ever-expanding universe of active-fluid physics, it is rare to find an experimental system that maps precisely onto a mathematically exact model.
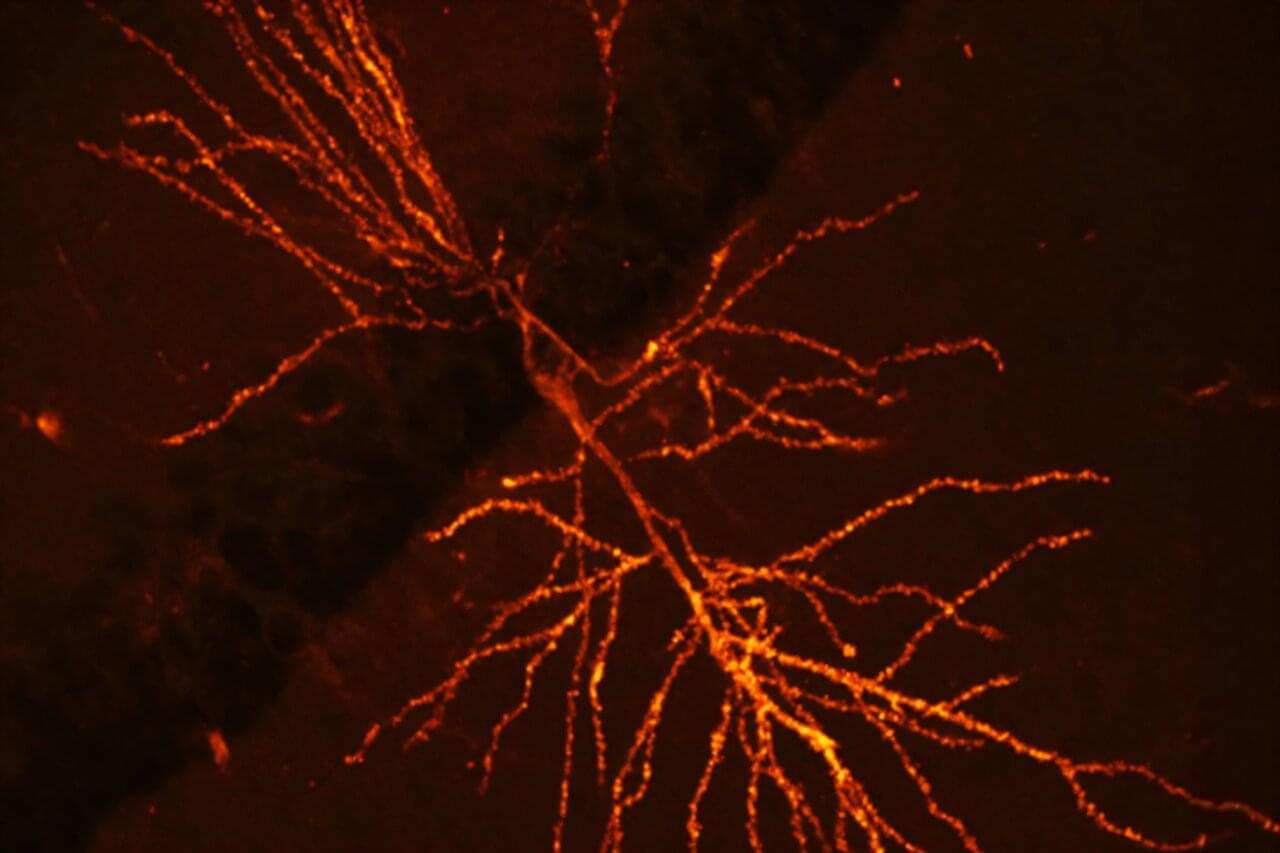
A team of Harvard researchers have unveiled a way to map the molecular underpinnings of how learning and memories are formed, a new technique expected to offer insights that may pave the way for new treatments for neurological disorders such as dementia.
“This technique provides a lens into the synaptic architecture of memory, something previously unattainable in such detail,” said Adam Cohen, professor of chemistry and chemical biology and of physics and senior co-author of the research paper, published in Nature Neuroscience.
Memory resides within a dense network of billions of neurons within the brain. We rely on synaptic plasticity—the strengthening and modulation of connections between these neurons—to facilitate learning and memory.




{kind=link}