A new study reveals that Earth’s North and South Poles are shifting faster than ever before.




Prevost, Robert] on Amazon.com. *FREE* shipping on qualifying offers.
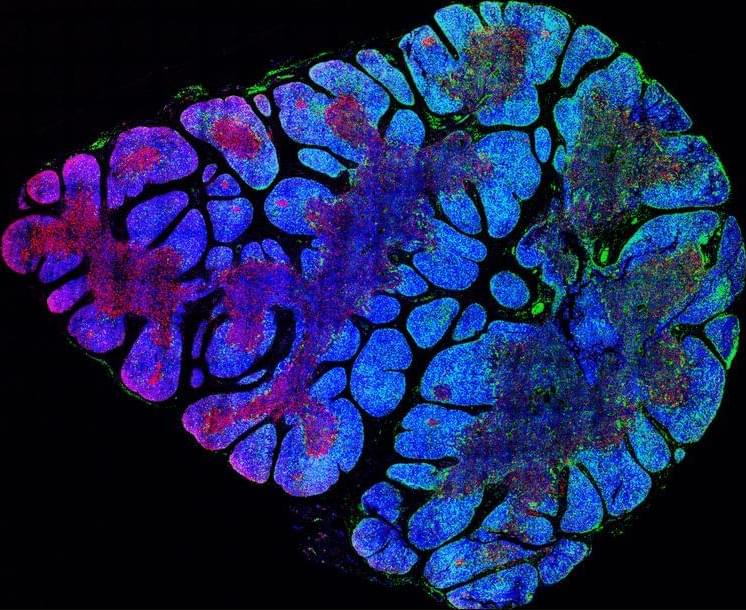
2024, for all of its challenges, has seen a remarkable amount of scientific discoveries by Israeli researchers across various disciplines.
From novel approaches to treating cancer to unraveling the intricacies of the human gut biome, these findings not only expand our understanding of the world but also pave the way for groundbreaking advancements in the future.
Let’s delve into 24 of the most fascinating discoveries made by Israeli scientists in 2024.
Take a look at these groundbreaking discoveries by Israeli researchers that are shaping our understanding of the world and its complexities.
Patreon: https://www.patreon.com/mattbatwings.
Discord: https://discord.gg/V5KFaF63mV
My socials: https://linktr.ee/mattbatwings.
Mario video: https://youtu.be/bqgNTR7VY4k.
Want to get more involved in the logical redstone community?
Learn Logical Redstone! https://youtube.com/playlist?list=PL5LiOvrbVo8keeEWRZVaHfprU4zQTCsV4
Open Redstone Engineers (ORE): https://openredstone.org/
Outro Music:
Helynt — Continue https://youtu.be/NQVdo_sKyFo