I found this on NewsBreak: A new physics paper suggests that we may all be living in the ultimate 4X strategy game after all.
My money’s on the universe being like Civ 6, with its borked-n-bonkers AI.
The world’s first fully AI-generated movie has been announced with the trailer for Next Stop Paris predictably containing one too many fingers.
TCLtv+ Studios is a brand new production team and its first release will be a short AI-generated romcom featuring professional voice actors and an original script but the imagery will be generated with AI tools.
The studio is a brand of TCL (which stands for Technology Group Corp.), a partially state-owned Chinese company that predominantly sells consumer electronics including televisions, mobile phones, air conditioners, and more.


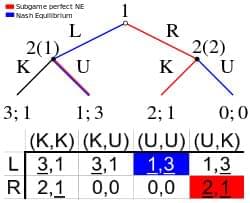
J. V. Neumann, Zur Theorie der Gesellschaftsspiele, 1928. Proved the existence of equilibrium in 2 players’ zero-sum games.
The birth of game theory.
The modern concept of Nash equilibrium is instead defined in terms of mixed strategies, where players choose a probability distribution over possible pure strategies (which might put 100% of the probability on one pure strategy; such pure strategies are a subset of mixed strategies). The concept of a mixed-strategy equilibrium was introduced by John von Neumann and Oskar Morgenstern in their 1944 book The Theory of Games and Economic Behavior, but their analysis was restricted to the special case of zero-sum games. They showed that a mixed-strategy Nash equilibrium will exist for any zero-sum game with a finite set of actions.[13] The contribution of Nash in his 1951 article “Non-Cooperative Games” was to define a mixed-strategy Nash equilibrium for any game with a finite set of actions and prove that at least one (mixed-strategy) Nash equilibrium must exist in such a game. The key to Nash’s ability to prove existence far more generally than von Neumann lay in his definition of equilibrium. According to Nash, “an equilibrium point is an n-tuple such that each player’s mixed strategy maximizes his payoff if the strategies of the others are held fixed. Thus each player’s strategy is optimal against those of the others.” Putting the problem in this framework allowed Nash to employ the Kakutani fixed-point theorem in his 1950 paper to prove existence of equilibria. His 1951 paper used the simpler Brouwer fixed-point theorem for the same purpose.[14]
Game theorists have discovered that in some circumstances Nash equilibrium makes invalid predictions or fails to make a unique prediction. They have proposed many solution concepts (‘refinements’ of Nash equilibria) designed to rule out implausible Nash equilibria. One particularly important issue is that some Nash equilibria may be based on threats that are not ‘credible’. In 1965 Reinhard Selten proposed subgame perfect equilibrium as a refinement that eliminates equilibria which depend on non-credible threats. Other extensions of the Nash equilibrium concept have addressed what happens if a game is repeated, or what happens if a game is played in the absence of complete information. However, subsequent refinements and extensions of Nash equilibrium share the main insight on which Nash’s concept rests: the equilibrium is a set of strategies such that each player’s strategy is optimal given the choices of the others.
A strategy profile is a set of strategies, one for each player. Informally, a strategy profile is a Nash equilibrium if no player can do better by unilaterally changing their strategy. To see what this means, imagine that each player is told the strategies of the others. Suppose then that each player asks themselves: “Knowing the strategies of the other players, and treating the strategies of the other players as set in stone, can I benefit by changing my strategy?”

A new study, published in the British Psychological Society’s British Journal of Psychology, reveals that regular gamers exhibit enhanced performance in tasks assessing cognitive functions, including attention and memory.
The study, which took place at the Lero Esports Science Research Lab at the University of Limerick, involved 88 young adults, half of whom regularly played more than seven hours of action-based video games each week.
Participants were tested with three tasks measuring different aspects of their cognitive performance – a simple reaction time test, a task that involved switching between responding to combinations of numbers and letters to evaluate executive function and working memory, and a maze-based activity to assess visuospatial memory.

Problems with the future of gaming.
A strange bug is removing people’s games on PlayStation 4 and 5, and Vita, and Sony doesn’t have a fix.
It wasn’t long ago that PlayStation sparked fan outrage when it said it would remove Discovery video content from people’s libraries, even though they had paid for it.
PlayStation later backtracked, but a similar, unintentional, issue has now come up: a random bug that’s wiping digital games from people’s libraries.

@OpenAI #sora #sorai #openai #openaisora
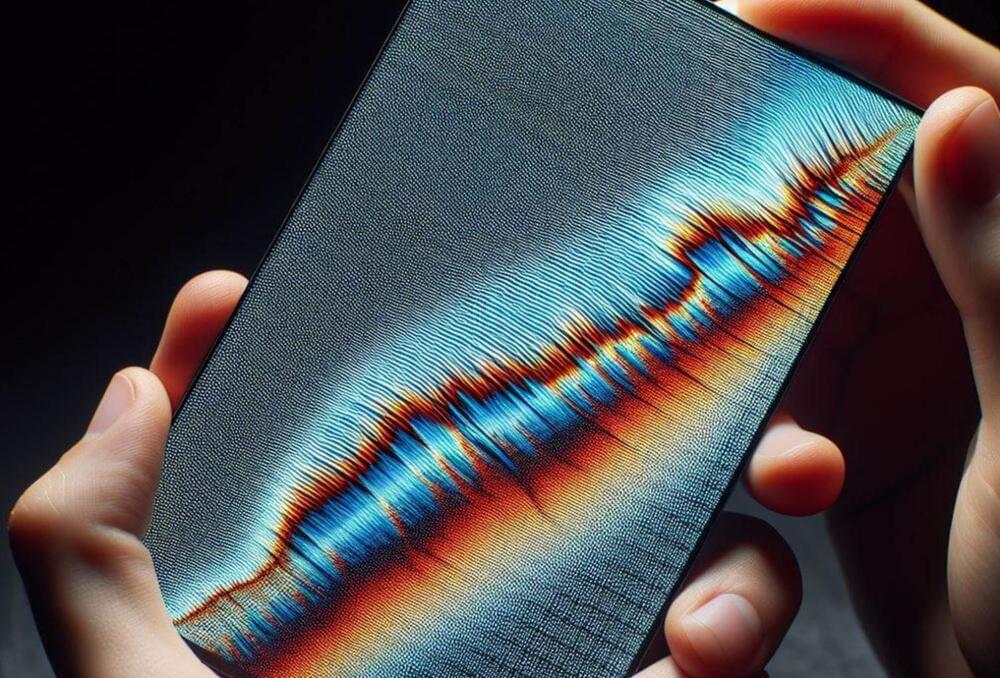
OLED panels have been around for quite some time, but now we are starting to see them come to gaming monitors, raising concerns about burn-in issues.
OLED pixel technology has been used in smartphones and TVs for many years now, and with each iteration of the technology, improvements are being made to the quality of the panel, particularly with the reduction of known problems. But now we are starting to see the gaming industry be blessed with gorgeous QD-OLED panels, and the brands behind these new gaming monitors are rolling out features such as MSI’s OLED Care technology to reduce the chances of debilitating issues such as burn-in.