Researchers achieve the first complete 2D flash chip, which can be programmed in 20 nanoseconds with minimal energy consumption.
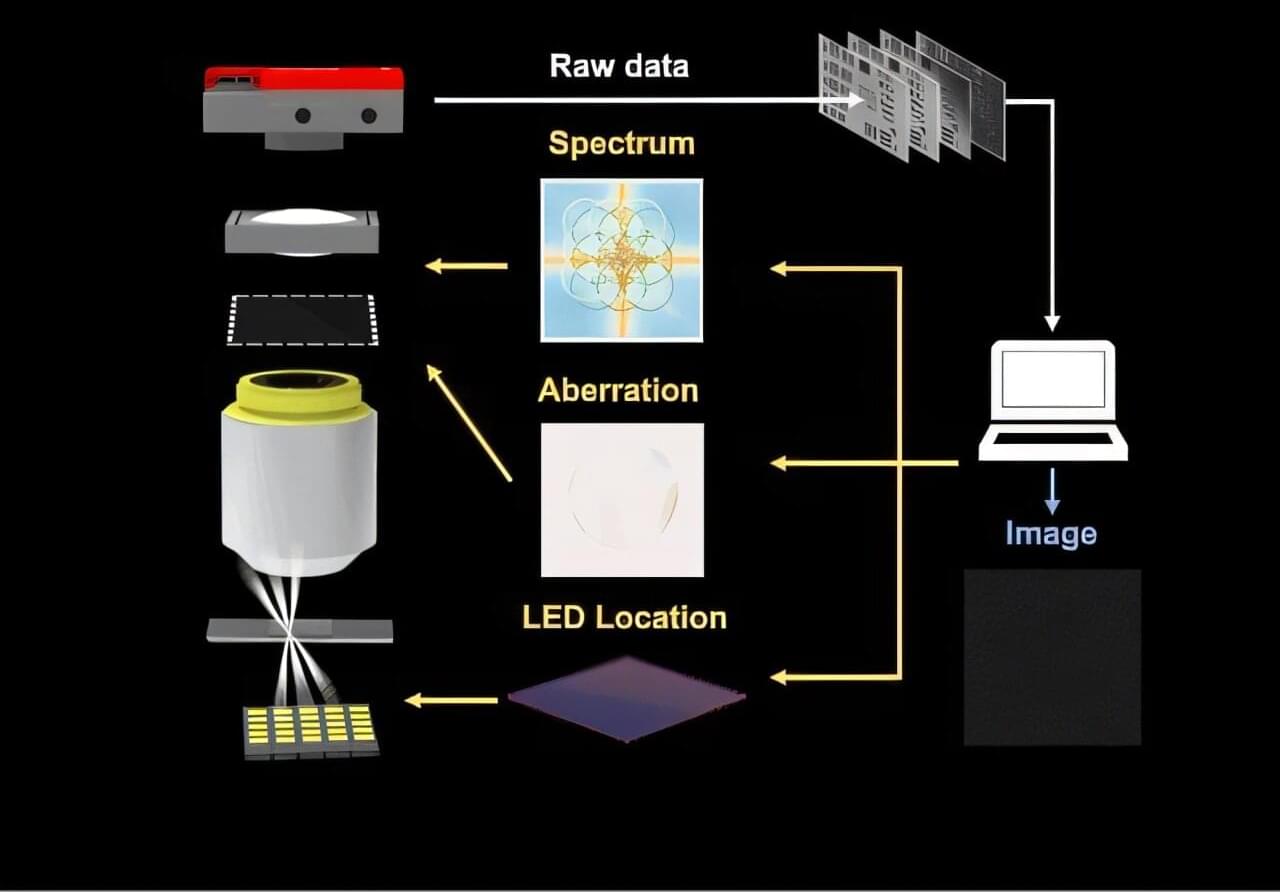
Professor Edmund Lam, Dr. Ni Chen and their research team from the Department of Electrical and Electronic Engineering under the Faculty of Engineering at the University of Hong Kong (HKU) have developed a novel uncertainty-aware Fourier ptychography (UA-FP) technology that significantly enhances imaging system stability in complex real-world environments. The research has been published in Light: Science & Applications.
Fourier ptychography, widely regarded as a cornerstone of computational imaging, enables wide field-of-view and high-resolution imaging with broad applications ranging from microscopy to X-ray and remote sensing. However, its practical implementation has long been hindered by misalignments, optical aberrations, and poor data quality—challenges common across computational imaging fields.
The team’s UA-FP framework innovatively incorporates uncertainty parameters into a fully differentiable computational model, enabling simultaneous system uncertainty quantification and correction and significant enhancement of imaging performance—even under suboptimal or interference-prone conditions. This advancement represents not only an advance in ptychography but also a transformative development for computational imaging as a whole.
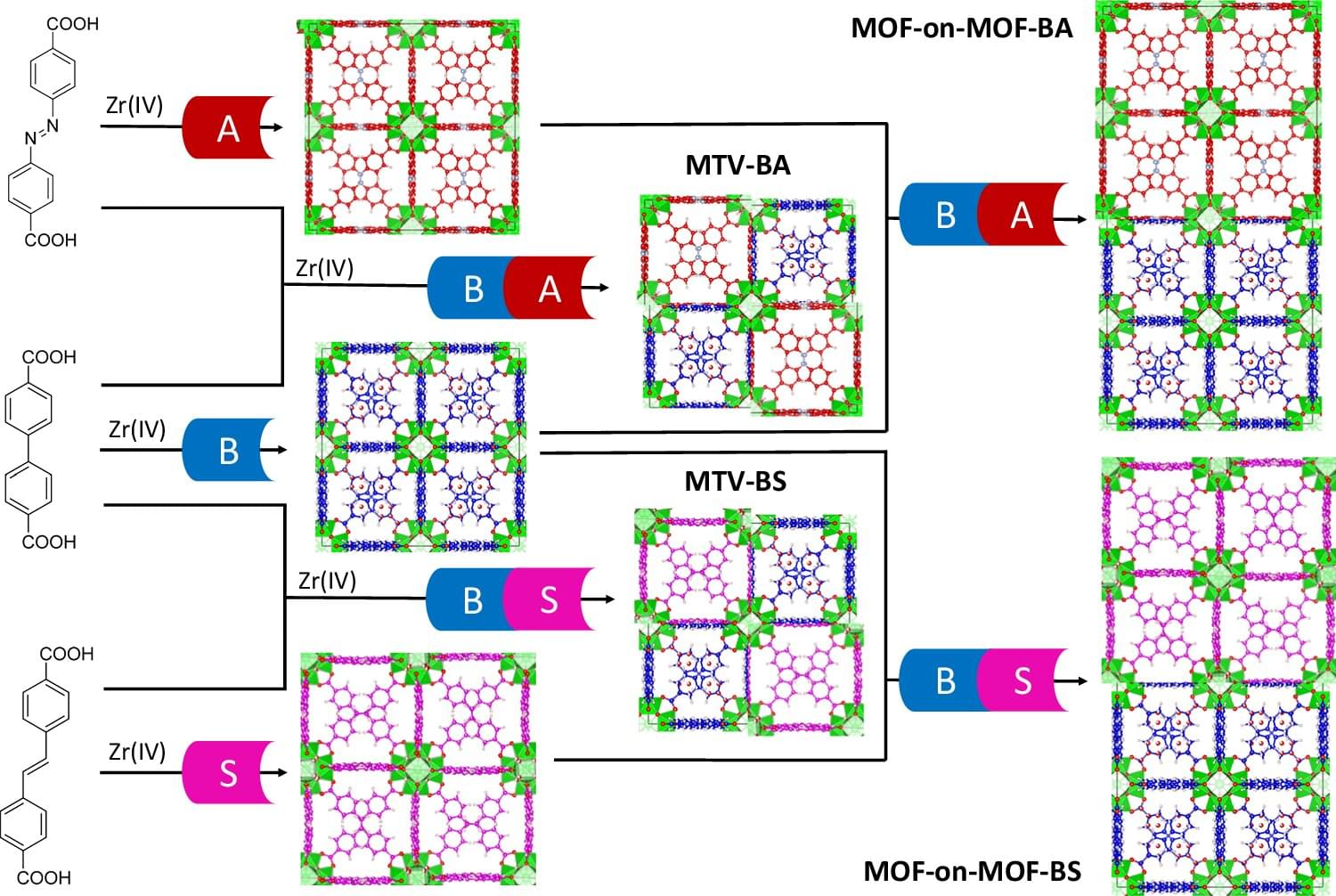
Scientists at Oregon State University have taken a big step toward lighting and display technologies that are more energy efficient and better for the planet. The work centers around crystalline, porous materials known as metal organic frameworks, often abbreviated as MOFs, and points toward next-generation materials that may end reliance on rare earth metals.
The study by Kyriakos Stylianou, associate professor of chemistry in the OSU College of Science, and graduate students Kyle Smith and Ankit Yadav appears in Nature Communications.
The findings are important because displays—ubiquitous in communications, computing, medical monitoring and many other aspects of everyday life—and lighting contribute heavily to global energy consumption and greenhouse gas emissions. The rare earth metals that underpin those technologies—europium, terbium, yttrium, cerium, gadolinium and others—are expensive and environmentally hazardous to mine and process.

A team of physicists has discovered a method to temporarily halt the ultrafast melting of silicon using a carefully timed sequence of laser pulses. This finding opens new possibilities for controlling material behavior under extreme conditions and could improve the accuracy of experiments that study how energy moves through solids.
The research, published in the journal Communications Physics, was led by Tobias Zier and David A. Strubbe of the University of California, Merced, in collaboration with Eeuwe S. Zijlstra and Martin E. Garcia from the University of Kassel in Germany. Their work focuses on how intense, ultrashort laser pulses affect the atomic structure of silicon—a material widely used in electronics and solar cells.
Using advanced computer simulations, the researchers showed that a single, high-energy laser pulse typically causes silicon to melt in a fraction of a trillionth of a second.

What occurs during the melting process in two-dimensional systems at the microscopic level? Researchers at Johannes Gutenberg University Mainz (JGU) have explored this phenomenon in thin magnetic layers.
“By utilizing skyrmions, i.e., miniature magnetic vortices, we were able to directly observe, for the first time, the transition of a two-dimensional ordered lattice structure into a disordered state at the microscopic level in real time,” explained Raphael Gruber, who conducted the research within the working group of Professor Mathias Kläui at the JGU Institute of Physics.
The findings, published in Nature Nanotechnology, are fundamental to a deeper understanding of melting processes in two dimensions and the behavior of skyrmions, which may revolutionize future data storage technologies.
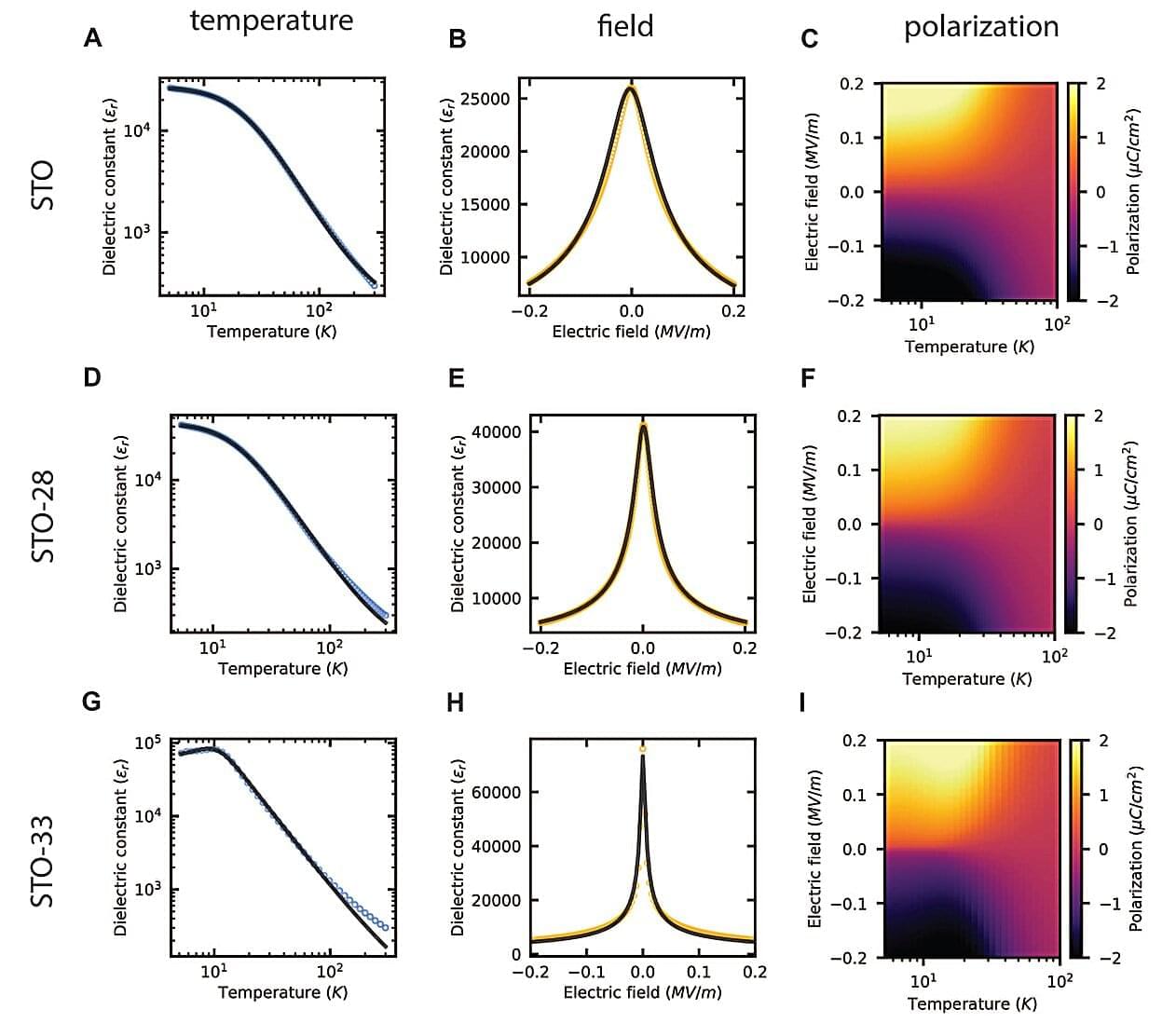
Superconductivity and quantum computing are two fields that have seeped from theoretical circles into popular consciousness. The 2025 Nobel Prize in physics was awarded for work in superconducting quantum circuits that could drive ultra-powerful computers. But what may be less well known is that these promising technologies are often possible only at cryogenic temperatures—near absolute zero. Unfortunately, few materials can handle such extremes. Their cherished physical properties disappear when the chill is on.
In a new paper published in Science, however, a team of engineers at Stanford University spotlights a promising material—strontium titanate, or STO for short—where the optical and mechanical characteristics do not decline at extreme low temperatures, but actually get significantly better, outperforming existing materials by a wide margin.
They believe these findings suggest that STO could become the building block for new light-based and mechanical cryogenic devices that push quantum computing, space exploration, and other fields to the next level.

University of Queensland researchers have created a microscopic “ocean” on a silicon chip to miniaturize the study of wave dynamics. The device, made at UQ’s School of Mathematics and Physics, uses a layer of superfluid helium only a few millionths of a millimeter thick on a chip smaller than a grain of rice.
The work is published in the journal Science.
Dr. Christopher Baker said it was the world’s smallest wave tank, with the quantum properties of superfluid helium allowing it to flow without resistance, unlike classical fluids such as water, which become immobilized by viscosity at such small scales.
Carbon nanotubes (CNTs), cylindrical nanostructures made of carbon atoms arranged in a hexagonal lattice, have proved to be promising for the fabrication of various electronic devices. In fact, these structures exhibit outstanding electrical conductivity and mechanical strength, both of which are highly favorable for the development of transistors (i.e., the devices that control the flow of current in electronics).
In recent years, several electronics engineers have started using CNTs to develop various electronics, including metal-oxide-semiconductor field-effect transistors (MOSFETs). MOSFETs are transistors that control the flow of current through a semiconducting channel utilizing an electric field applied to a gate electrode.
Notably, when arrays of CNTs are used to develop MOSFETs, they can operate at radio frequencies (RF), the range of electromagnetic waves that support wireless communication. The resulting MOSFETs could thus be particularly advantageous for the advancement of wireless communication systems and technologies.

Photo-induced force microscopy began as a concept in the mind of Kumar Wickramasinghe when he was employed by IBM in the early years of the new millennium. After he came to the University of California, Irvine in 2006, the concept evolved into an invention that would revolutionize research by enabling scientists to study the fundamental characteristics of matter at nanoscale resolution.
Since the earliest experimental uses of PiFM around 2010, the device, which reveals the chemical composition and spatial organization of materials at the molecular level, has become a tool of choice for researchers in fields as diverse as biology, geology, materials science and even advanced electronics manufacturing.
“This is the story of a technology that was inspired by work at IBM, was invented and developed at UC Irvine, then got spun off, and now we have instruments on all continents across the world except for Antarctica,” says Wickramasinghe, Henry Samueli Endowed Chair and Distinguished Professor emeritus of electrical engineering and computer science who now holds the title of UC Irvine Distinguished Research Professor. “Almost anywhere serious research is happening, there are people out there who are using PiFM to discover new things.”
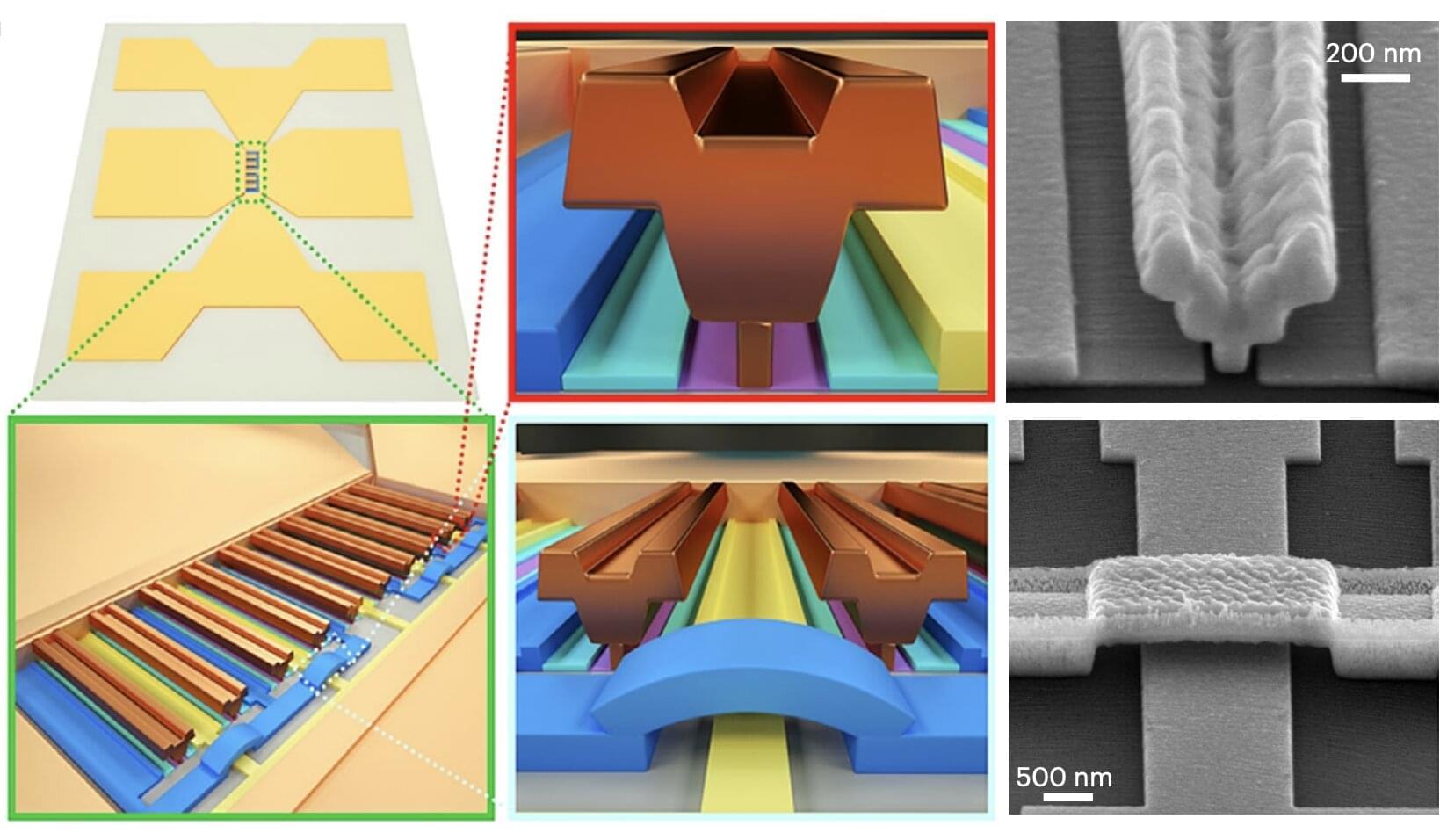
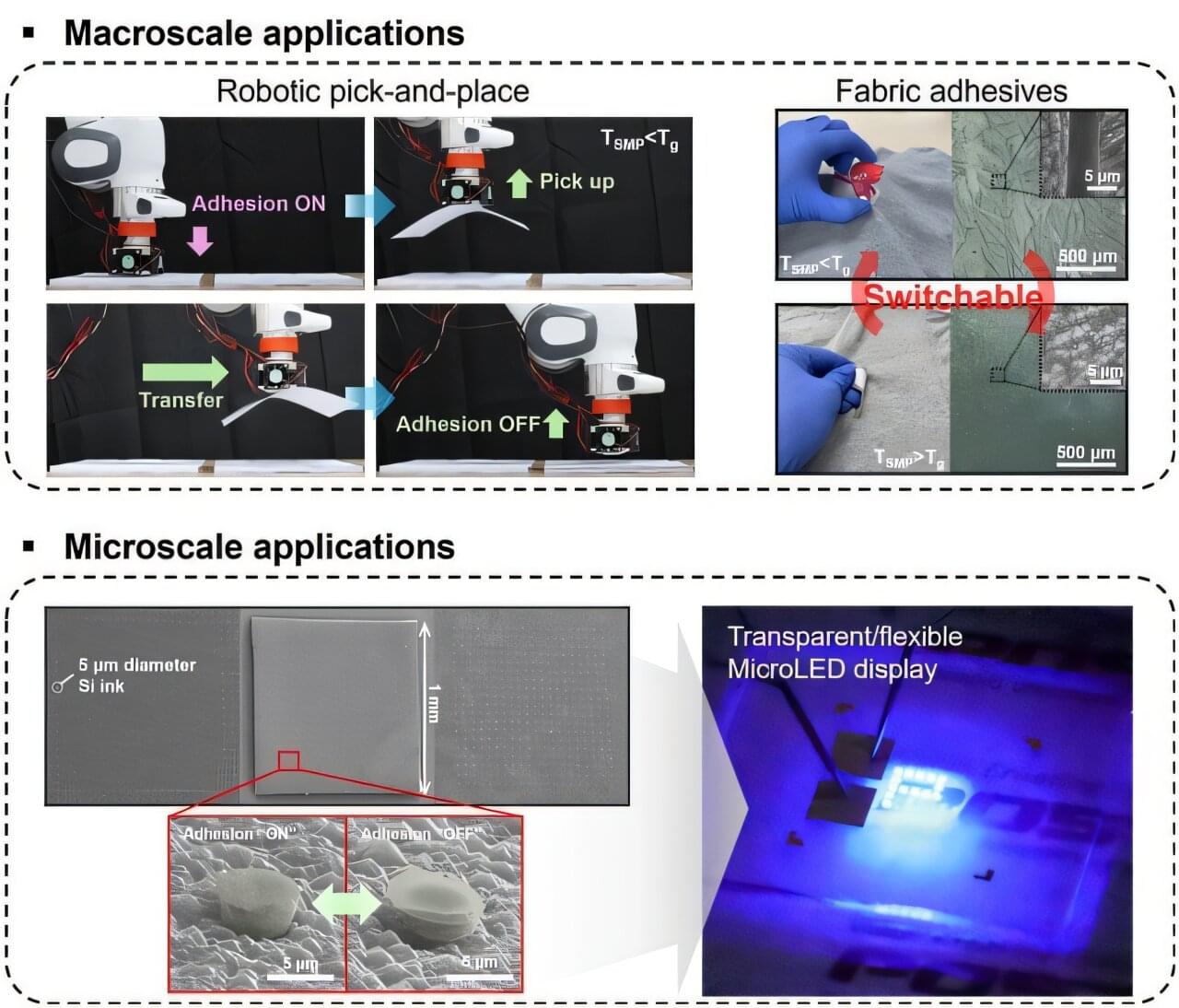
A research team at Pohang University of Science and Technology (POSTECH), has developed a novel dry adhesive technology that allows everything from microscale electronic components to common household materials to be easily attached and detached.
The study was recently published in the journal Nature Communications, and the team was led by Professor Seok Kim in collaboration with Professor Kihun Kim (POSTECH), Professor Namjoong Kim (Gachon University), Professor Haneol Lee (Chonbuk National University), and Dr. Chang-Hee Son (University of Connecticut, U.S.).
Micro-LEDs, a next-generation display technology, offer significant advantages such as higher brightness, longer lifespan, and the ability to enable flexible and transparent displays. However, transferring micro-LED chips—thinner than a strand of hair—onto target substrates with high precision and minimal residue has been a persistent challenge. Conventional methods relying on liquid adhesives or specialized films often result in overly complex processes, poor alignment accuracy, and residual contamination.
{kind=link}
{kind=link}