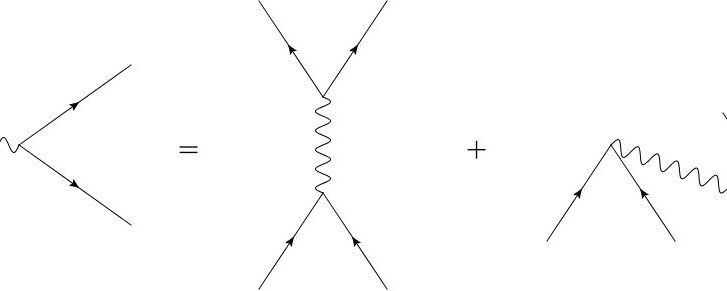
Biology encodes information in DNA and RNA, which are complex molecules finely tuned to their functions. But are they the only way to store hereditary molecular information? Some scientists believe life as we know it could not have existed before there were nucleic acids, thus understanding how they came to exist on the primitive Earth is a fundamental goal of basic research. The central role of nucleic acids in biological information flow also makes them key targets for pharmaceutical research, and synthetic molecules mimicking nucleic acids form the basis of many treatments for viral diseases, including HIV. Other nucleic acid-like polymers are known, yet much remains unknown regarding possible alternatives for hereditary information storage. Using sophisticated computational methods, scientists from the Earth-Life Science Institute (ELSI) at the Tokyo Institute of Technology, the German Aerospace Center (DLR) and Emory University explored the “chemical neighbourhood” of nucleic acid analogues. Surprisingly, they found well over a million variants, suggesting a vast unexplored universe of chemistry relevant to pharmacology, biochemistry and efforts to understand the origins of life. The molecules revealed by this study could be further modified to gives hundreds of millions of potential pharmaceutical drug leads.
Nucleic acids were first identified in the 19th century, but their composition, biological role and function were not understood by scientists until the 20th century. The discovery of DNA’s double-helical structure by Watson and Crick in 1953 revealed a simple explanation for how biology and evolution function. All living things on Earth store information in DNA, which consists of two polymer strands wrapped around each other like a caduceus, with each strand being the complement of the other. When the strands are pulled apart, copying the complement on either template results in two copies of the original. The DNA polymer itself is composed of a sequence of “letters,” the bases adenine (A), guanine (G), cytosine © and thymine (T), and living organisms have evolved ways to make sure during DNA copying that the appropriate sequence of letters is almost always reproduced. The sequence of bases is copied into RNA by proteins, which then is read into a protein sequence.