
Organs are in short supply. About 17 people die each day waiting for a transplant. New experimental methods of growing and tweaking organs could help.
Organs are in short supply. About 17 people die each day waiting for a transplant. New experimental methods of growing and tweaking organs could help.
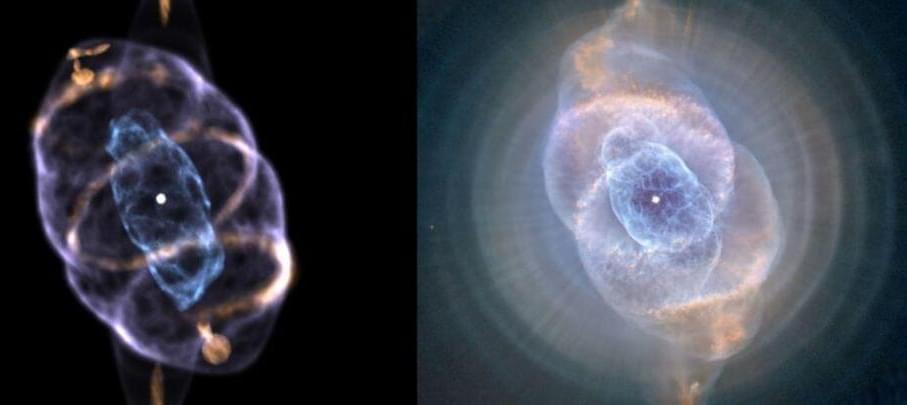
The twisty eruption of a dying star has finally been revealed in all its 3D glory.
A team of scientists led by a high school graduate has reconstructed the complicated and mysterious nebulae that make up one of the most famous stellar ghosts in the sky – the Cat’s Eye Nebula.
Their model revealed the mechanisms that carved out some of the previously unexplained aspects of the nebula’s structure.
Scientists in the UK conducted a trial of an experimental cancer therapy that uses the cold sore virus to make cancer cells explode.
Many technologies are greaty anticipated and predicted, and promise to change our lives. Today we will be looking at some that get less fanfare, but hold the promise to change our lives in profound ways.
Visit our Website: http://www.isaacarthur.net.
Join the Facebook Group: https://www.facebook.com/groups/1583992725237264/
Support the Channel on Patreon: https://www.patreon.com/IsaacArthur.
Visit the sub-reddit: https://www.reddit.com/r/IsaacArthur/
Listen or Download the audio of this episode from Soundcloud: https://soundcloud.com/isaac-arthur-148927746/quiet-revolution.
Cover Art by Jakub Grygier: https://www.artstation.com/artist/jakub_grygier.
Graphics Team:
Edward Nardella.
Jarred Eagley.
Justin Dixon.
Katie Byrne.
Misho Yordanov.
Murat Mamkegh.
Pierre Demet.
Sergio Botero.
Stefan Blandin.
Script Editing:
Andy Popescu.
Connor Hogan.
Edward Nardella.
Eustratius Graham.
Gregory Leal.
Jefferson Eagley.
Luca de Rosa.
Mark Warburton.
Michael Gusevsky.
Mitch Armstrong.
MolbOrg.
Naomi Kern.
Philip Baldock.
Sigmund Kopperud.
Steve Cardon.
Tiffany Penner.
Music:
Dexter Britain, “Seeing the Future“
Kai Engel, “Endless story about Sun and Moon“
Frank Dorittke, “Morninglight“
Lombus, “Hydrogen Sonata“
AJ Prasad, “Aether“
Kevin MacLeod, “Spacial Winds”
Welcome to Thomas Insights — every day, we publish the latest news and analysis to keep our readers up to date on what’s happening in industry. Sign up here to get the day’s top stories delivered straight to your inbox.
In a collaboration between a telecommunications company, a roboticist, a tattoo artist, and a very brave tattoo recipient, a team sponsored by T-Mobile Netherlands successfully conducted the world’s first remote tattooing using a 5G-enabled robotic arm.
As part of a marketing initiative to demonstrate the low latency of 5G, T-Mobile engaged British technologist Noel Drew to build and program the robotic arm to mirror, in real-time, the needlework performed by Dutch tattoo artist Wes Thomas on a mannequin arm.
According to a revealing private intelligence report published by Strider Technologies, at least 154 Chinese scientists who worked on U.S. government-sponsored research at the country’s top national security laboratory have been recruited to perform scientific work in China. They are working on the design and manufacture of nuclear weapons, which is considered a high national security risk.
————————–
#ChinaRevealed #ChinaNews
Posted in futurism, robotics/AI
Get a free month of Curiosity Stream: http://curiositystream.com/isaacarthur.
Artificial Intelligence, while still limited to only the most simplistic computers and robots, is beginning to emerge and will only grow smarter. Can humanity survive it’s own creations and learn to coexist with them?
Visit our Website: http://www.isaacarthur.net.
Support us on Patreon: https://www.patreon.com/IsaacArthur.
SFIA Merchandise available: https://www.signil.com/sfia/
Social Media:
Facebook Group: https://www.facebook.com/groups/1583992725237264/
Reddit: https://www.reddit.com/r/IsaacArthur/
Twitter: https://twitter.com/Isaac_A_Arthur on Twitter and RT our future content.
SFIA Discord Server: https://discord.gg/53GAShE
Listen or Download the audio of this episode from Soundcloud: Episode’s Audio-only version: https://soundcloud.com/isaac-arthur-148927746/coexistence-of-humans-ai.
Episode’s Narration-only version: https://soundcloud.com/isaac-arthur-148927746/coexistence-of…ation-only.
Credits:
Coexistence of Humans & AI
Episode 224a; February 9, 2019
Written by:





