Circa 2008 face_with_colon_three
Adult bone marrow (BM) houses a tiny pool of hematopoietic stem cells (HSCs) that have the ability to maintain not only themselves but also all the rest of highly turning over blood lineages throughout the mammalian life (1, 2). Hence, the ability to sustain HSC in tissue culture would allow serial introduction of gain or loss of function mutations efficiently in hematopoietic system. However, our failure to expand HSC in culture has hampered the use of this approach. In fact, BM suspension cultures lose rapidly their HSC content despite vigorous growth of progenitors and more differentiated cells at least for 3 weeks even in optimal cytokine milieu (3, 4). Therefore, the phenomenon of stem cell exhaustion or senescence may set the limits that make it impossible even in principle to expand HSC in culture for longer periods (5–7).
Mouse HSC do expand in vivo (8, 9), at least up to 8000-fold, as shown by Iscove and Nawa (9) through serial transplantation experiments that assessed carefully the input and output contents of HSC in each transfer generation. Recently also in vitro approaches have been improved and refined culture conditions with new growth factors can now support up to 30-fold expansion of mouse HSC ex vivo (10). However, since it is not clear to what extent external culture conditions can be improved, alternative but not mutually exclusive efforts to change the intrinsic properties of HSC have been taken. Seminal experiments in this respect by Humphries, Savageau and their colleagues have shown that ectopic expression of HOXB4 transcription factor in BM cells support the survival and expansion of HSC in vivo and importantly also in vitro (11–13). By rigorously monitoring the HSC content in their cultures of HOXB4-transduced BM cells, they found that HSC could be expanded up to 41-fold in the 2-week liquid cultures (13). HOXB4 belongs to a large family of HOX transcription factors that are crucial for the basic developmental processes in addition to their role in maintenance of different stem cell compartments.
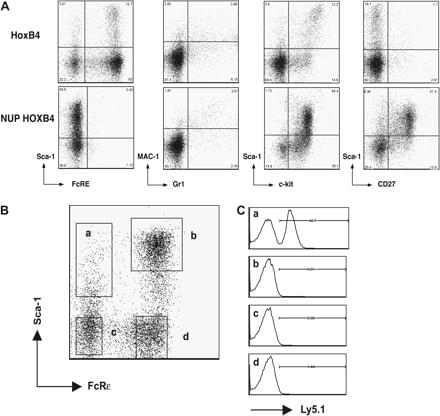
Capitalizing on the findings of Humphries, Savageau and their colleagues, we have established long-term murine BM cultures of HOXB4-transduced cells (HOX cells) and monitored their stem cell content to find out how extensively genetically modified HSC and their multipotent primitive progenitors (MPPs) can be expanded in culture for experimental purposes. In addition and for comparison, we established BM cultures transduced with constructs encoding for Nucleoporin 98 (NUP)–HOXB4 (NUP cells) fusion protein again following the lead of Humphries et al. (14) who showed that ectopic expression of similar fusions promoted in vivo even more robust expansion and survival of HSC.