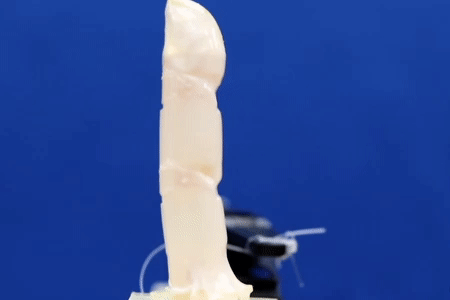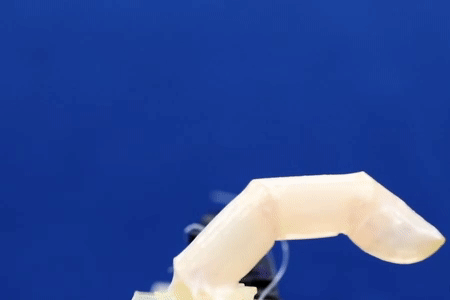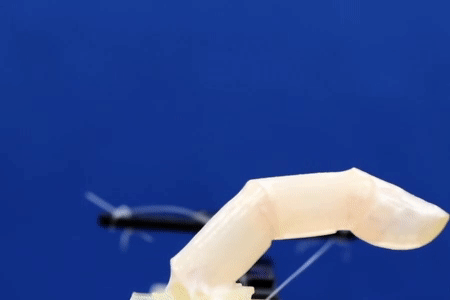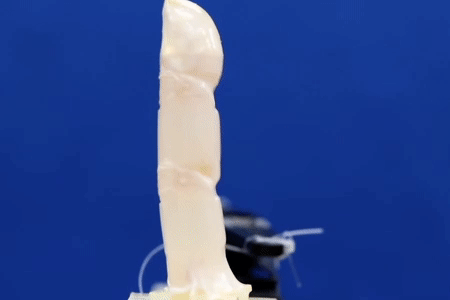
There are moments when scientists come close to creating the future artists envision for us. Researchers at the University of Tokyo have taken a step closer to bringing a sci-fi standard into reality: living human skin for robots.
Made from real cells, the living skin not only has the realistic texture that faux skin has difficulty mimicking, but also the ability to keep out water and heal itself.
“I think living skin is the ultimate solution to give robots the look and touch of living creatures since it is exactly the same material that covers animal bodies,” said Shoji Takeuchi, first author of the study and a project professor at the University of Tokyo who works on biohybrid systems.
A new navigation system that tracks subatomic particles constantly bombarding Earth could help us get around indoors, underground, and underwater — all the places GPS fails.
The challenge: GPS (the Global Positioning System) is a group of 31 satellites, constantly transmitting radio signals from about 12,500 miles above Earth’s surface. Receivers in phones, cars, planes, and ships then use data from multiple satellites’ signals to calculate their own locations on Earth.
While GPS has revolutionized surface transportation, satellite signals can reflect off solid surfaces, making the navigation system incapable of accurately pinpointing the locations of receivers indoors, underground, and underwater.
Two studies report new methods for using metasurfaces to create and control dark areas called “optical singularities.”
Optical devices and materials allow scientists and engineers to harness light for research and real-world applications, like sensing and microscopy. Federico Capasso’s group at the Harvard John A. Paulson School of Engineering Applied Sciences (SEAS) has dedicated years to inventing more powerful and sophisticated optical methods and tools. Now, his team has developed new techniques to exert control over points of darkness, rather than light, using metasurfaces.
“Dark regions in electromagnetic fields, or optical singularities, have traditionally posed a challenge due to their complex structures and the difficulty in shaping and sculpting them. These singularities, however, carry the potential for groundbreaking applications in fields such as remote sensing and precision measurement,” said Capasso, the Robert L. Wallace Professor of Applied Physics and Vinton Hayes Senior Research Fellow in Electrical Engineering at SEAS and senior corresponding author on two new papers describing the work.
Nature research paper: A method is presented to harness the paper-folding mechanism of reconfigurable macroscale systems to create reconfigurable DNA origami structures, in anticipation that it will advance the development of complex molecular systems.
Researchers from the University of Tokyo pool knowledge of robotics and tissue culturing to create a controllable robotic finger covered with living skin tissue. The robotic digit has living cells and supporting organic material grown on top of it for ideal shaping and strength. As the skin is soft and can even heal itself, the finger could be useful in applications that require a gentle touch but also robustness. The team aims to add other kinds of cells into future iterations, giving devices the ability to sense as we do.
Professor Shoji Takeuchi is a pioneer in the field of biohybrid robots, the intersection of robotics and bioengineering. Together with researchers from around the University of Tokyo, he explores things such as artificial muscles, synthetic odor receptors, lab-grown meat, and more. His most recent creation is both inspired by and aims to aid medical research on skin damage such as deep wounds and burns, as well as help advance manufacturing.
Just a week after the ChatGPT Browse feature went live on the iOS app, OpenAI had to deactivate it due to displaying content “in ways we don’t want,” according to a tweet from the company that created the AI chatbot.
The feature enabled users to bypass paywalls to access subscription-based content without subscriptions. “If a user specifically asks for a URL’s full text, it may inadvertently fulfill this request. We are disabling Browse while we fix this — want to do right by content owners,” the company’s tweet continued.
University of British Columbia (UBC) and BC Children’s Hospital scientists discovered that disease-causing bacteria in the gut feed on sialic acid, a sugar found in the intestinal mucus layer.
Michael Levin, a developmental biologist at Tufts University, has a knack for taking an unassuming organism and showing it’s capable of the darnedest things. He and his team once extracted skin cells from a frog embryo and cultivated them on their own. With no other cell types around, they were not “bullied,” as he put it, into forming skin tissue. Instead, they reassembled into a new organism of sorts, a “xenobot,” a coinage based on the Latin name of the frog species, Xenopus laevis. It zipped around like a paramecium in pond water. Sometimes it swept up loose skin cells and piled them until they formed their own xenobot—a type of self-replication. For Levin, it demonstrated how all living things have latent abilities. Having evolved to do one thing, they might do something completely different under the right circumstances.
Slime mold grows differently depending on the music playing.
Not long ago I met Levin at a workshop on science, technology, and Buddhism in Kathmandu. He hates flying but said this event was worth it. Even without the backdrop of the Himalayas, his scientific talk was one of the most captivating I’ve ever heard. Every slide introduced some bizarre new experiment. Butterflies retain memories from when they were caterpillars, even though their brains turned to mush in the chrysalis. Cut off the head and tail of a planarian, or flatworm, and it can grow two new heads; if you amputate again, the worm will regrow both heads. Levin argues the worm stores the new shape in its body as an electrical pattern. In fact, he thinks electrical signaling is pervasive in nature; it is not limited to neurons. Recently, Levin and colleagues found that some diseases might be cured by retraining the gene and protein networks as one might train a neural network.
A new way of 3D printing wood that takes advantage of warping could change how we build things in the future — an innovation that could potentially save us all time and money.
The challenge: Wood is made of fibers that absorb moisture like a sponge. If lumber isn’t dried properly, the wood will eventually shrink — bending or twisting in different directions depending on the orientation of the fibers.
That’s called “warping,” and it’s usually something we try to avoid — a warped door won’t close properly, and a warped floor will look wavy rather than flat.
Dr. Robert Floyd, Ph.D. is Executive Secretary of the Comprehensive Nuclear-Test-Ban Treaty Organization (CTBTO — https://www.ctbto.org/), the organization tasked with building up the verification regime of the Comprehensive Nuclear-Test-Ban Treaty, a multilateral treaty opened for signature in 1996 by which states agree to ban all nuclear explosions in all environments, for military or civilian purposes.
Prior to joining CTBTO, Dr. Floyd was the Director General of the Australian Safeguards and Non-proliferation Office (ASNO), where he was responsible for Australia’s implementation of and compliance with various international treaties and conventions including the Comprehensive Nuclear-Test-Ban Treaty, Nuclear Non-Proliferation Treaty, Convention on the Physical Protection of Nuclear Material (CPPNM) and the Chemical Weapons Convention.
During his time as Director General of ASNO, Dr. Floyd also chaired the advisory group to the Director General of the International Atomic Energy Agency on safeguards implementation (SAGSI), co-chaired the Preparatory Committee for the review of the amended CPPNM, co-chaired one of the working groups of the International Partnership for Nuclear Disarmament Verification, was the lead official for Australia in the Nuclear Security Summit process, and chaired the Asia-Pacific Safeguards Network.
Prior to his appointment with ASNO, Dr. Floyd served for more than seven years in the Department of the Prime Minister and Cabinet where he held a number of senior executive positions providing advice to the Prime Minister on policy issues covering counter-terrorism, counter-proliferation, emergency management, and homeland and border security.
Dr. Floyd was awarded a commemorative medal on the 30th anniversary of Kazakhstan’s independence in recognition of the strong and enduring partnership between the CTBTO and Kazakhstan on nuclear non-proliferation, disarmament, peace, and security. Dr. Floyd also received the Australian Nuclear Association (ANA) award for 2021 in recognition of his outstanding leadership role as Director General of the ASNO.
With a Ph.D. in population ecology, Dr. Floyd spent the first 20 years of his career as a research scientist with the Commonwealth Scientific and Industrial Research Organization (CSIRO).