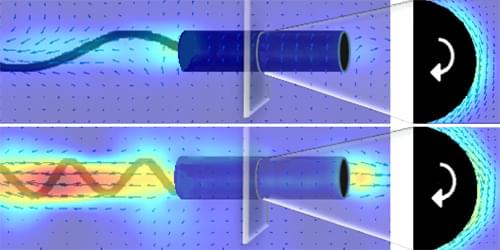
If a helical bacteria’s tail propulsion is strong enough to deform the yield-stress fluid ahead of the swimmer, locomotion proceeds.

A trio of evolutionary biologists, two with Carleton University, the other with Seoul National University, has apparently solved the paradox of aposematism—how animals managed to evolve with bright colors to warn predators of their toxic nature. In their paper study, published in the journal Science, Karl Loeffler-Henry, Changku Kang and Thomas Sherratt, conducted an analysis of the family tree of over 1,000 frog, salamander and newt species.
For many years, evolutionary biologists have puzzled over the seeming paradox of aposematism, in which animals such as frogs develop bright colors to warn potential predators that eating them will make them sick or even kill them. How could such colors have evolved? Animals that stand out tend to be the first caught and eaten, preventing the evolution of even brighter colors from occurring. In this new effort, the research team set out to solve this riddle.
The work involved analyzing the family tree of 1,100 species of frogs, salamanders and newts, looking for evidence of evolution of aposematism in a new way—by breaking them down into more categories than previous efforts—five instead of two: conspicuous, cryptic, partially conspicuous, fully conspicuous and polymorphic.
Two newly discovered genes have been linked to schizophrenia while a previously known gene associated with schizophrenia risk has also been linked to autism in a massive new study.
Scientists say the findings increase our understanding of brain diseases and could lead to new treatment targets.
Importantly, this is the first known investigation to look at the risk of schizophrenia in different groups of people, especially those with African ancestry. It revealed rare harmful variations in gene proteins raise the risk of schizophrenia in all ethnic groups.
These folks engineering a much better way to deliver your basically anything. If you want to engineer your own creations with me every month, just head to https://www.crunchlabs.com where you can get 2 boxes FREE!
Again, this was not sponsored in anyway nor did they pay for any of my travel or accommodations but if you want to learn more about Zipline here is their website-https://www.flyzipline.com/
Ponder — https://soundcloud.com/prodbyponder.
Laura Shigihara — @supershigi.
Andrew Applepie — https://soundcloud.com/andrewapplepie.
Blue Wednesday — https://soundcloud.com/bluewednesday


😗
Martian soil is generally poor for growing plants, but researchers have used CRISPR to create gene-edited rice that might be able to germinate and grow despite the hostile habitat.
By Leah Crane
Year 2022 😗😁
For decades we have dreamed of true holographic displays for entertainment, communication, and education. Star Wars had 3D projections rendered in real-time — the definition wasn’t great, but they were communicating across interplanetary distances — and Avatar had holographic maps showcasing the terrain of Pandora. In reality, we mostly have 2D images which show dimension and depth when viewed from different angles. That might be on the verge of changing.
Pierre-Alexandre Blanche from the Wyant College of Optical Sciences at the University of Arizona recently published a paper in Light: Advanced Manufacturing which acts as a roadmap toward true 3D holographic displays.
“3D movies exist already, and the effects are amazing,” Blanche told SYFY WIRE. “But we’re working toward diffraction-based display that will produce all the human visual cues. That’s what’s missing today in the world of 3D display. They’re always missing one or more visual cues.”
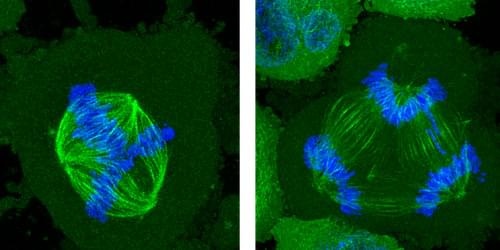
Segregation of chromosomes in dividing cells can be disrupted if the cells are constrained by their surroundings.
One of the aberrant features of cancer cells is a failure to distribute chromosomes properly when the cells divide. Researchers have now found that a specific problem with the chromosome-distribution machinery can become more common in cancer cells confined within shallow microscopic channels—but also that, surprisingly, increasing the physical constraints can suppress these errors [1]. Such confinement mimics the effects of crowding by surrounding cells in a tumor, and the researchers believe the results might help to explain what goes awry in cancers and perhaps offer clues to how it might be put right.
In a healthy, dividing cell, after the genome is replicated, the chromosomes are segregated into two groups. Both groups are bound to the mitotic spindle, a bundle of aligned filaments (called microtubules) that are pinched together at the ends into structures called poles. The chromosomes are then drawn along the microtubules toward the poles. A key cause of improper chromosome segregation in cancer cells is the formation of spindles with more than two poles. Multipolar spindle formation inside living organisms may differ from the phenomenon when observed in cells grown in a dish [2], so it is possible that the confining effect of the surrounding cells in a tissue has some influence on this process.

Astrophysicists in Australia have shed new light on the state of the universe 13 billion years ago by measuring the density of carbon in the gases surrounding ancient galaxies.
The study, published in Monthly Notices of the Royal Astronomical Society, adds another piece to the puzzle of the history of the universe.
“We found that the fraction of carbon in warm gas increased rapidly about 13 billion years ago, which may be linked to large-scale heating of gas associated with the phenomenon known as the Epoch of Reionization,” says Dr. Rebecca Davies, ASTRO 3D Postdoctoral Research Associate at Swinburne University of Technology, Australia and lead author of the paper describing the discovery.
Saturn ’s giant moon, Titan, is due to launch in 2027. When it arrives in the mid-2030s, it will begin a journey of discovery that could bring about a new understanding of the development of life in the universe. This mission, called Dragonfly, will carry an instrument called the Dragonfly Mass Spectrometer (DraMS), designed to help scientists hone in on the chemistry at work on Titan. It may also shed light on the kinds of chemical steps that occurred on Earth that ultimately led to the formation of life, called prebiotic chemistry.
Titan’s abundant complex carbon-rich chemistry, interior ocean, and past presence of liquid water on the surface make it an ideal destination to study prebiotic chemical processes and the potential habitability of an extraterrestrial environment.
DraMS will allow scientists back on Earth to remotely study the chemical makeup of the Titanian surface. “We want to know if the type of chemistry that could be important for early pre-biochemical systems on Earth is taking place on Titan,” explains Dr. Melissa Trainer of NASA’s Goddard Space Flight Center, Greenbelt, Maryland.