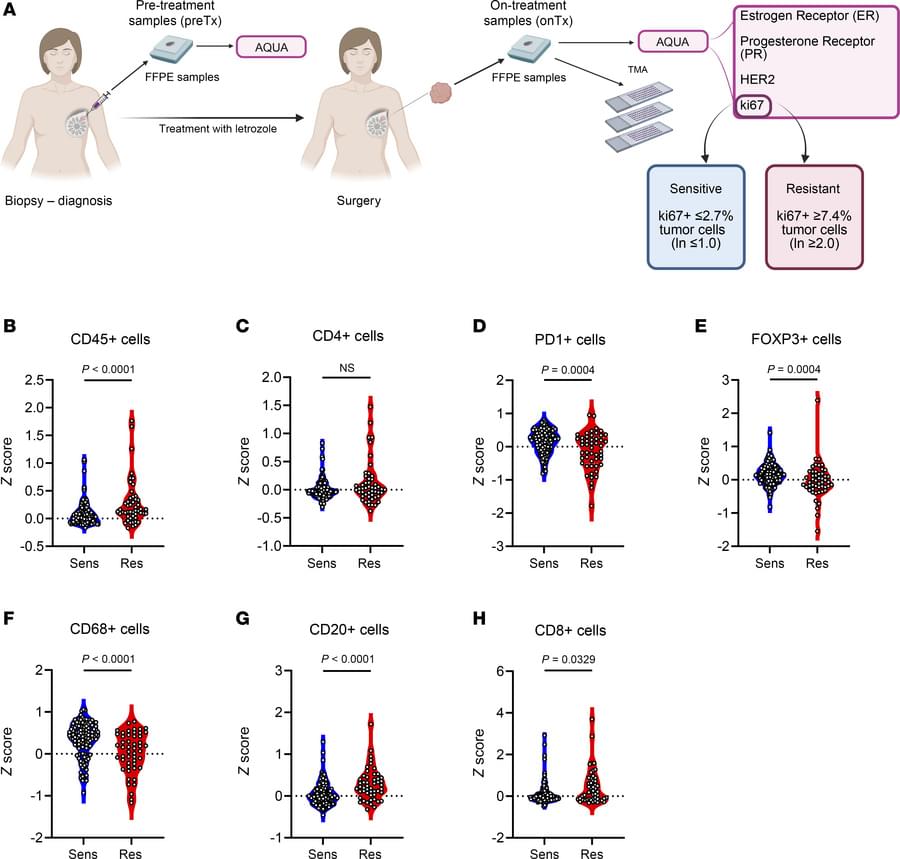
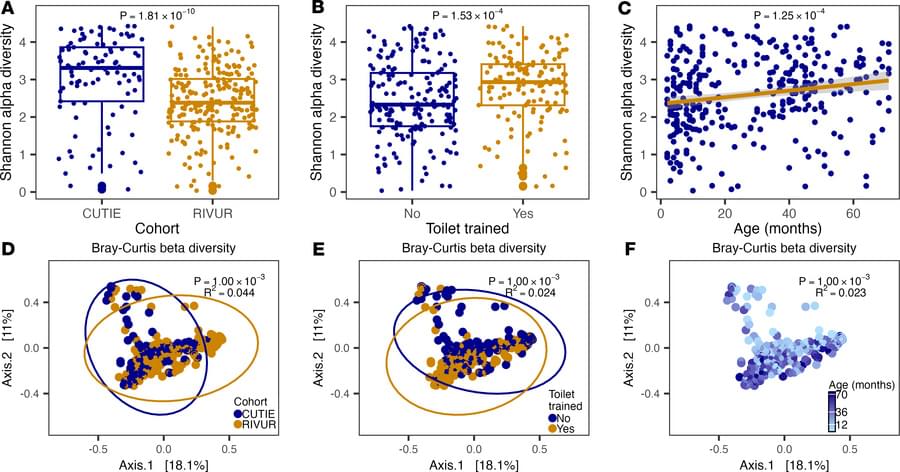
Here, Carlos L. Arteaga & team analyze patient biopsies, finding CD8+ T cells in the TIME promote resistance to estrogen suppression in HR+ breast cancer via CXCL11 and immune-related pathways:
The images: GeoMx-based immunofluorescence of breast tumor tissue obtained during estrogen deprivation therapy (letrozole) demonstrates increased immune cell infiltration in estrogen deprivation–resistant tumors (right) compared with sensitive tumors (left).
1UT Southwestern Simmons Comprehensive Cancer Center, Department of Internal Medicine, University of Texas Southwestern (UTSW) Medical Center, Dallas, Texas, USA.
2Department of Clinical Medicine and Surgery, University of Naples Federico II, Naples, Italy.
3Division of Pediatric Gastroenterology, Hepatology and Nutrition, Cincinnati Children’s Hospital Medical Center, Cincinnati, Ohio, USA.