Scientists want to simulate various climate conditions to help prevent real life risks to our planet.




AI isn’t nearly as popular with the global populace as its boosters would have you believe.
As Axios reports based on a new poll of 32,000 global respondents from the consultancy firm Edelman, public trust is already eroding less than 18 months into the so-called “AI revolution” that popped off with OpenAI’s release of ChatGPT in November 2022.
“Trust is the currency of the AI era, yet, as it stands, our innovation account is dangerously overdrawn,” Justin Westcott, the global technology chair for the firm, told Axios. “Companies must move beyond the mere mechanics of AI to address its true cost and value — the ‘why’ and ‘for whom.’”
When will AI match and surpass human capability? In short, when will we have AGI, or artificial general intelligence… the kind of intelligence that should teach itself and grow itself to vastly larger intellect than an individual human?
According to Ben Goertzel, CEO of SingularityNet, that time is very close: only 3 to 8 years away. In this TechFirst, I chat with Ben as we approach the Beneficial AGI conference in Panama City, Panama.
We discuss the diverse possibilities of human and post-human existence, from cyborg enhancements to digital mind uploads, and the varying timelines for when we might achieve AGI. We talk about the role of current AI technologies, like LLMs, and how they fit into the path towards AGI, highlighting the importance of combining multiple AI methods to mirror human intelligence complexity.
We also explore the societal and ethical implications of AGI development, including job obsolescence, data privacy, and the potential geopolitical ramifications, emphasizing the critical period of transition towards a post-singularity world where AI could significantly improve human life. Finally, we talk about ownership and decentralization of AI, comparing it to the internet’s evolution, and envisages the role of humans in a world where AI surpasses human intelligence.
00:00 Introduction to the Future of AI
01:28 Predicting the Timeline of Artificial General Intelligence.
02:06 The Role of LLMs in the Path to AGI
05:23 The Impact of AI on Jobs and Economy.
06:43 The Future of AI Development.
10:35 The Role of Humans in a World with AGI
35:10 The Diverse Future of Human and Post-Human Minds.
36:51 The Challenges of Transitioning to a World with AGI
39:34 Conclusion: The Future of AGI.

A massive Microsoft data center in Goodyear, Arizona is guzzling the desert town’s water supply to support its cloud computing and AI efforts, The Atlantic reports.
A source familiar with Microsoft’s Goodyear facility told the Atlantic that it was specifically designed for use by Microsoft and the heavily Micosoft-funded OpenAI. In response to this allegation, both companies declined to comment.
Powering AI demands an incredible amount of energy. Worsening AI’s massive environmental footprint is the fact that it also consumes a mind-boggling amount of water. AI pulls enough electricity from data centers that they risk overheating, so to mitigate that risk, engineers use water to cool the servers back down.
and this means humans will use brain computer interface to transact, but where will the AGI’s economy take shape, and how will you take part?
AI Marketplace: https://taimine.com/
Deep Learning AI Specialization: https://imp.i384100.net/GET-STARTED
AI news timestamps:
0:00 Everyone’s wrong.
1:57 Future of money.
3:04 The economy of AGI
5:35 Brain computer interface transactions.
6:26 Methods of income.
#ai #technology #tech
Check out Robert’s book “Faster Than Light” ➜ https://www.amazon.com/Faster-than-Light-Your-Shadow/dp/1662…atfound-20 https://www.amazon.com/Faster-than-Light-Your-Shadow/dp/1662…atfound-20
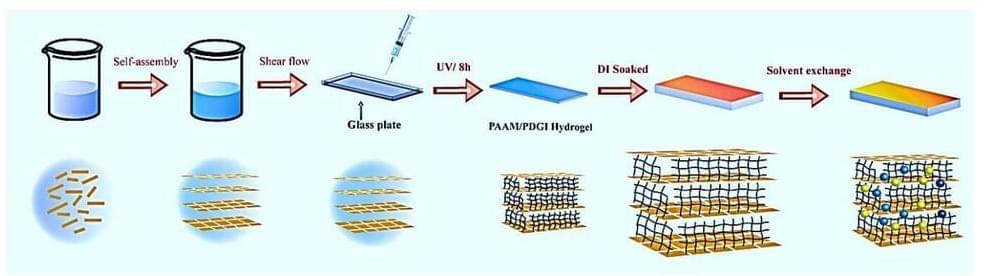
Inspired by amphibians such as the wood frog, investigators designed and synthesized a new type of camouflage skin involving one-dimensional photonic crystal structures assembled in three-dimensional flexible gels.
As described in Advanced Optical Materials, the camouflage skin can quickly recognize and match the background by modulating the optical signals of external stimuli.
It demonstrated excellent mechanical performance, self-adaptive camouflage capabilities in response to complex surroundings, and long-term stability in real-world living environments. Bright structural color and mechanical flexibility were maintained even at temperatures as low as-80℃

Key Takeaways:
Princeton University cosmologist David Spergel emphasizes that the universe’s shape reveals crucial insights into its historical evolution and future trajectory. Questions regarding whether the universe will expand indefinitely or eventually contract, as well as its finiteness or infiniteness, all pivot on its shape.