Startup Precision Neuroscience has tested its flexible, ultra-thin brain implants in people for the first time.


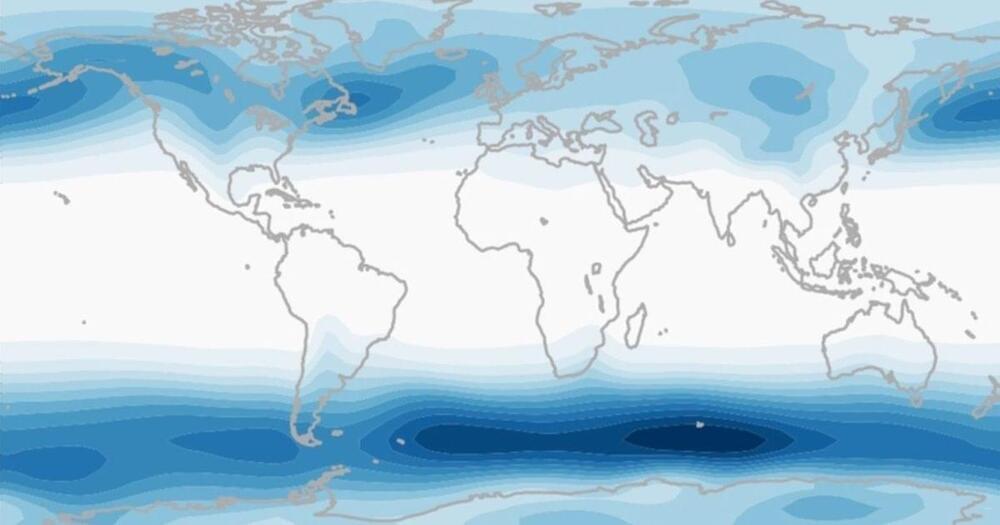
To make its weather predictions, it analyzes 60 million daily observations from satellite, aircraft, and ground-based reports, using what we know about atmospheric physics to determine what the weather is likely to be like across the globe over the next 15 days.
This can literally save lives — if people know in advance that hurricanes or winter storms are heading their way, they can take action to prepare — but because the model is so complex, it must be run on a supercomputer over the course of several hours, which also makes it expensive.
The AIs: AI-based weather forecasting models are starting to catch up with traditional ones, like the European Model.


Imagine that a soldier has a tiny computer device injected into their bloodstream that can be guided with a magnet to specific regions of their brain. With training, the soldier could then control weapon systems thousands of miles away using their thoughts alone. Embedding a similar type of computer in a soldier’s brain could suppress their fear and anxiety, allowing them to carry out combat missions more efficiently. Going one step further, a device equipped with an artificial intelligence system could directly control a soldier’s behavior by predicting what options they would choose in their current situation.
While these examples may sound like science fiction, the science to develop neurotechnologies like these is already in development. Brain-computer interfaces, or BCI, are technologies that decode and transmit brain signals to an external device to carry out a desired action. Basically, a user would only need to think about what they want to do, and a computer would do it for them.
BCIs are currently being tested in people with severe neuromuscular disorders to help them recover everyday functions like communication and mobility. For example, patients can turn on a light switch by visualizing the action and having a BCI decode their brain signals and transmit it to the switch. Likewise, patients can focus on specific letters, words or phrases on a computer screen that a BCI can move a cursor to select.

The challenge: There are very few ways to slow down Alzheimer’s disease or treat its symptoms, and there’s no cure — in 2021, nearly 120,000 Americans died from Alzheimer’s complications, making it one of the top 10 leading causes of death.
One genetic variant in particular — called APOE-e4 — is strongly tied to the brain disease. Having one copy makes a person 2–3 times more likely to develop Alzheimer’s, while having two copies (one from each parent) increases the risk by 8–12 times.

Columbia University researchers have identified patterns of brain injury linked to “hidden consciousness” — and the discovery could lead to better outcomes for people in comas or vegetative states.
Hidden consciousness: Severe brain injuries can cause “disorders of consciousness” (DoC), such as vegetative states, in which a person looks awake, but lacks any indication they are aware of their surroundings, and comas, where they appear neither awake nor aware.
An estimated 15–20% of people with a DoC are also experiencing a phenomenon called “cognitive motor dissociation” (CMD), or “hidden consciousness.” That means they are aware of what’s going on around them, but they can’t physically respond to it.
Rohit Singla, an MD/PhD student, shares how his training in both medicine and engineering is allowing him to identify complex problems, understand the nuances within them and tackle those complex problems with elegant solutions that are the right fit for patients with kidney disease. Using data from over 10,000 cases, he is creating artificial intelligence tools to automatically detect microscopic changes in the kidney structure and develop new treatments to improve people’s lives.
Produced by UBC faculty of medicine development and alumni engagement.
© 2010–2021 UBC Faculty of Medicine. All rights reserved.
For more information on addiction services at #YaleMedicine, visit: https://www.yalemedicine.org/departments/program-in-addiction-medicine.
Written and produced by Yale Neuroscience PhD student Clara Liao.
Addiction is now understood to be a brain disease. Whether it’s alcohol, prescription pain pills, nicotine, gambling, or something else, overcoming an addiction isn’t as simple as just stopping or exercising greater control over impulses. That’s because addiction develops when the pleasure circuits in the brain get overwhelmed, in a way that can become chronic and sometimes even permanent. This is what’s at play when you hear about reward “systems” or “pathways” and the role of dopamine when it comes to addiction. But what does any of that really mean? One of the most primitive parts of the brain, the reward system, developed as a way to reinforce behaviors we need to survive—such as eating. When we eat foods, the reward pathways activate a chemical called dopamine, which, in turn, releases a jolt of satisfaction. This encourages you to eat again in the future. When a person develops an addiction to a substance, it’s because the brain has started to change. This happens because addictive substances trigger an outsized response when they reach the brain. Instead of a simple, pleasurable surge of dopamine, many drugs of abuse—such as opioids, cocaine, or nicotine—cause dopamine to flood the reward pathway, 10 times more than a natural reward. The brain remembers this surge and associates it with the addictive substance. However, with chronic use of the substance, over time the brain’s circuits adapt and become less sensitive to dopamine. Achieving that pleasurable sensation becomes increasingly important, but at the same time, you build tolerance and need more and more of that substance to generate the level of high you crave. Addiction can also cause problems with focus, memory, and learning, not to mention decision-making and judgement. Seeking drugs, therefore, is driven by habit—and not conscious, rational decisions. Unfortunately, the belief that people with addictions are simply making bad choices pervades. Furthermore, the use of stigmatizing language, such as “junkie” and “addict” and getting “clean,” often creates barriers when it comes to accessing treatment. There’s also stigma that surrounds treatment methods, creating additional challenges. Though treatment modalities differ based on an individual’s history and the particular addiction he or she has developed, medications can make all the difference. “A lot of people think that the goal of treatment for opioid use disorder, for example, is not taking any medication at all,” says David A. Fiellin, MD, a Yale Medicine primary care and addiction medicine specialist. “Research shows that medication-based treatments are the most effective treatment. Opioid use disorder is a medical condition just like depression, diabetes or hypertension, and as with those conditions, it is most effectively treated with a combination of medication and counseling.”