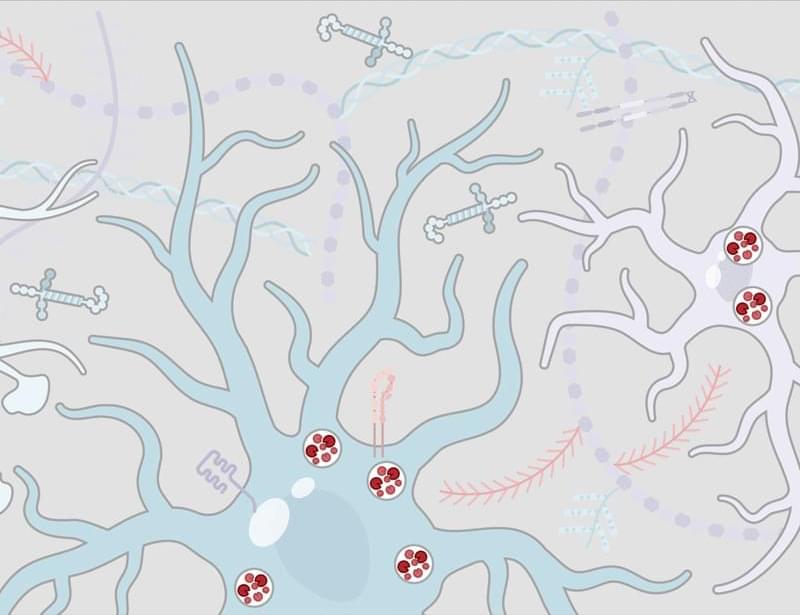
Some microbes happily thrive in unforgiving environments. An extremophile hunt is underway to leverage their resilience tactics, from medicine to space exploration.


Want to know more? See our corrisponding Substack episode. We’re living through the largest uncontrolled experiment on human cognition in history, and most people don’t even know they’re subjects. While the world moved on from pandemic panic t…



A gene-editing delivery system developed by UT Southwestern Medical Center researchers simultaneously targeted the liver and lungs of a preclinical model of a rare genetic disease known as alpha-1 antitrypsin deficiency (AATD), significantly improving symptoms for months after a single treatment, a new study shows.