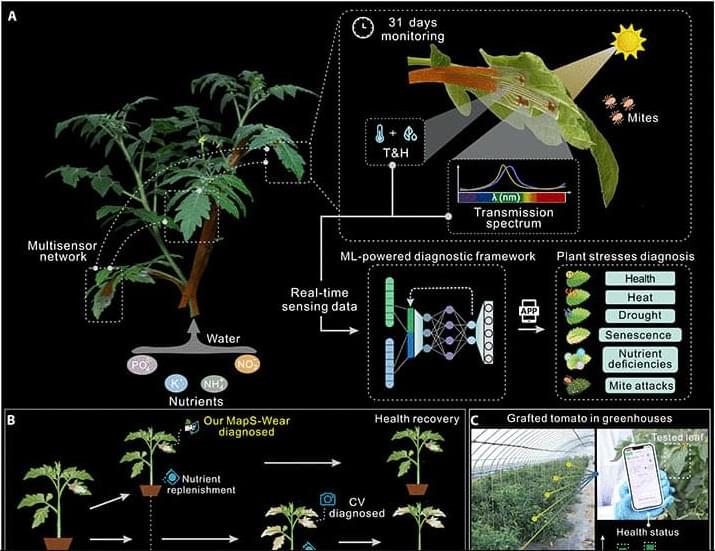
Alzheimer’s disease (AD) is a debilitating neurodegenerative condition that affects a significant proportion of older people worldwide. Synapses are points of communication between neural cells that are malleable to change based on our experiences. By adding, removing, strengthening, or weakening synaptic contacts, our brain encodes new events or forgets previous ones.
In AD, synaptic plasticity, the brain’s ability to regulate the strength of synaptic connections between neurons, is significantly disrupted. This worsens over time, reducing cognitive and memory functions and leading to reduced quality of life. To date, there is no effective cure for AD, and only limited treatments for managing the symptoms.
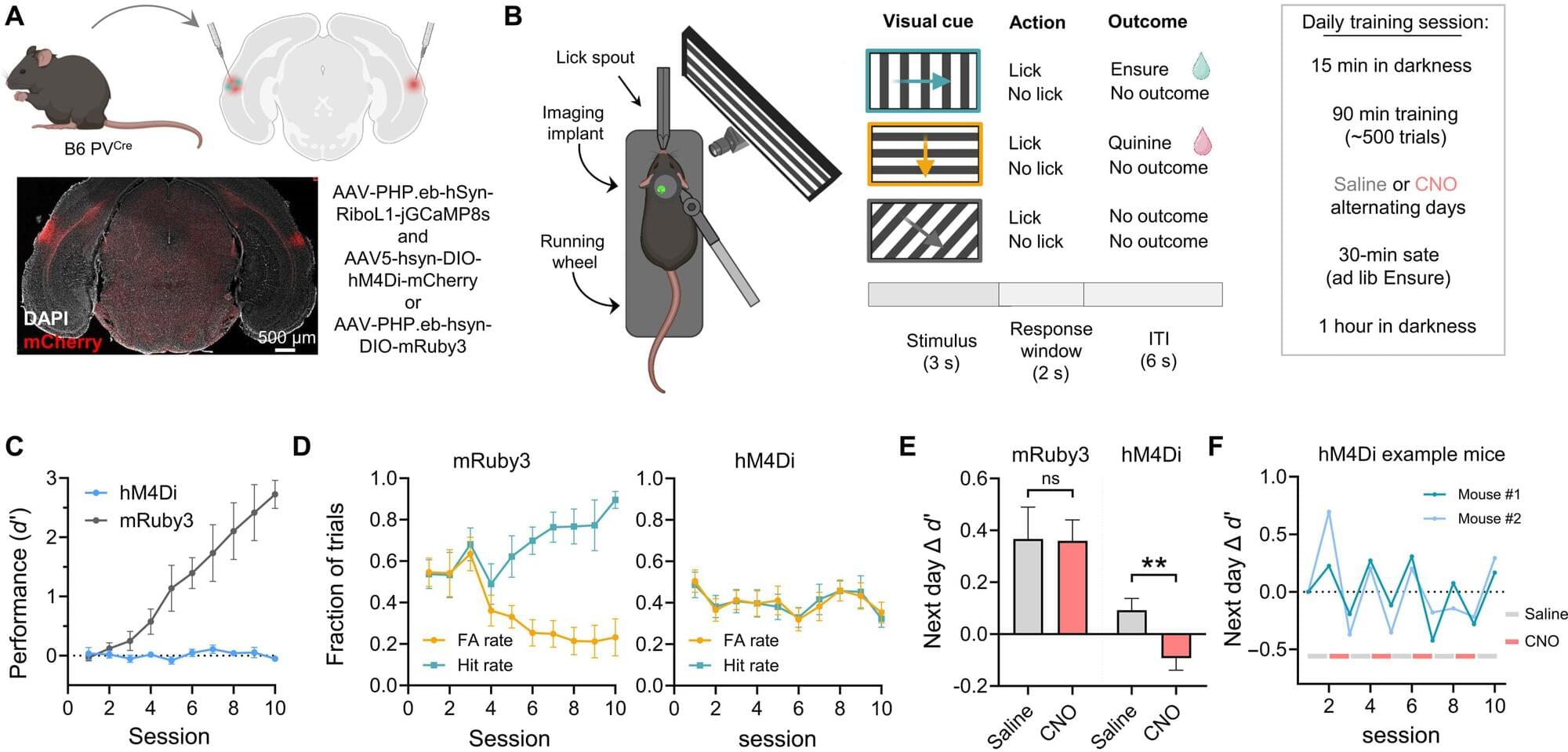
Studies have shown that repetitive transcranial magnetic stimulation (rTMS), a noninvasive brain stimulation technique that uses electromagnetic pulses to target specific brain regions, has therapeutic potential to manage dementia and related diseases. From previous studies, we know that rTMS can promote synaptic plasticity in healthy nervous systems. Moreover, it is already used to treat certain neurodegenerative and neuropsychiatric conditions. However, individual responses to rTMS for AD management are variable, and the underlying mechanisms are not clearly understood.





{kind=link}
{kind=link}
{kind=link}